[AutoML] NASNet
2017년에 NASNet이 나온 이후 2018년 부터 AutoML의 시대가 열렸습니다. MnasNet, MobileNet V3, EffientNet등 여러 경량화 네트워크들은 NAS(Neural Architecture Search)을 사용했고, 모바일쪽 네트워크들은 많이 NAS를 사용하고 있습니다. 이번에 소개할 논문은 Neural Architecture Search with Reinforcement Learning를 소개해드리겠습니다.
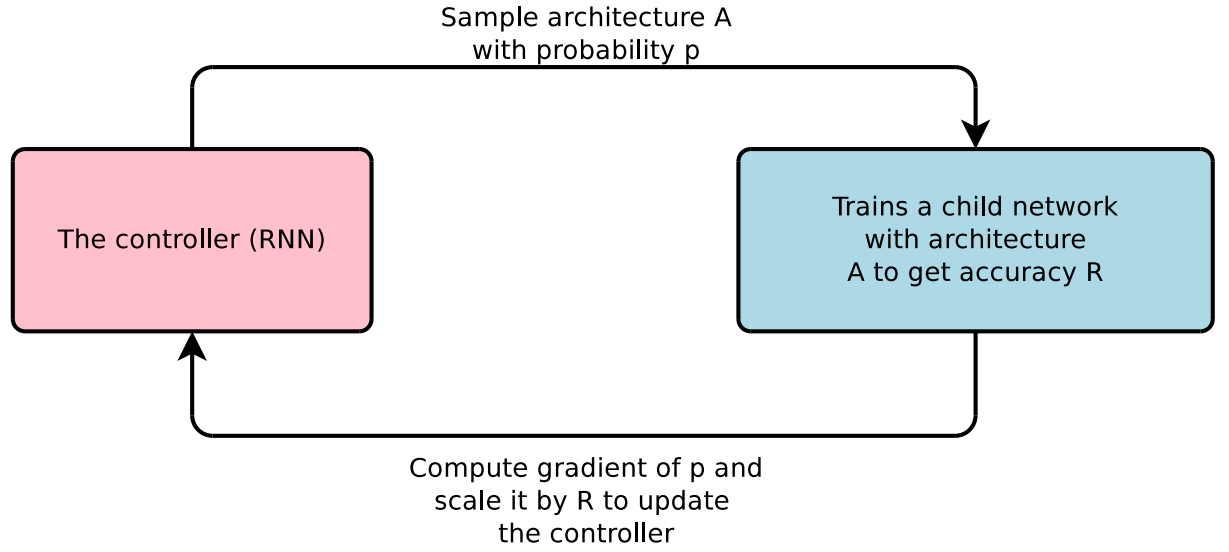
Neural Architecture Search은 RNN을 사용하여 model description을 생성하고 생성된 네트워크를 학습합니다. 그리고 validation set을 이용하여 accuracy를 구하고 이를 reward로 만듭니다. 후에 이 reward를 갖고 policy gradient를 구해 controller를 업데이트 시킵니다.
Generate Model Description
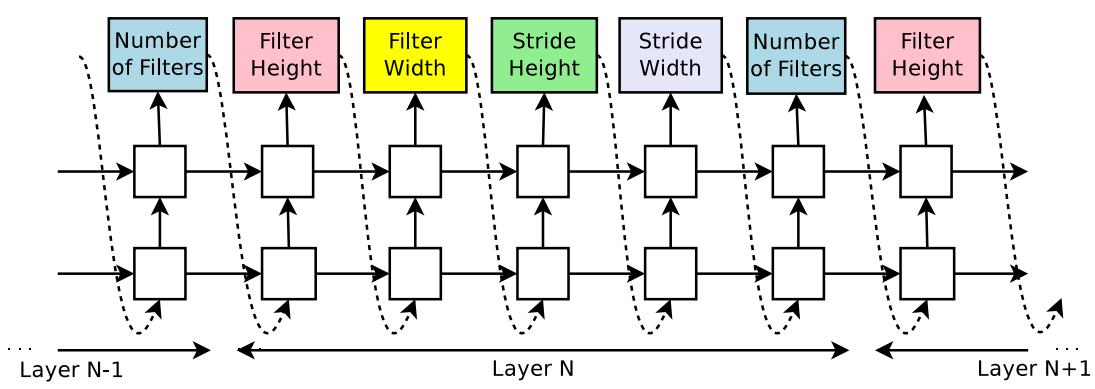
NAS에서 controller가 model description을 만듭니다. model description을 갖고 model을 만든 다음 학습을 시키고 수렴이 되면 validation set으로 accuracy를 측정하게 됩니다. controller RNN의 파라미터 \(\theta_c\)는 validation accuracy의 평균을 이용해 최적화 시킵니다.
Training With REINFORCE
controller를 학습시키려면 우리는 loss 함수를 정의해야합니다. controller에서 만들어진 네트워크를 child network라고 하겠습니다. 그리고 child network를 구성하기 위한 action들을 \(a_{1:T}\), 학습된 child network의 validation accuracy를 R이라고 할 때 \(J(\theta_c)\)는 다음과 같습니다.
reward signal인 R은 미분 불가능하기 때문에 REINFORCE라는 policy로 update를 합니다. 이는 다음과 같은 식으로 만들 수 있고
따라서 위의 식은 다음과 같이 근사될 수 있습니다.
m은 한 배치에 controller가 만들 child network의 개수이고 k번째 child network의 validation accuracy를 \(R_k\)이다. 위의 식은 불편 추정치이지만 분산이 크기 때문에 분산을 줄이기 위해서 다음과 같은 식을 씁니다.
b는 이전 네트워크들의 validation accuracy의 지수이동평균입니다.
Skip Connection
GoogleNet, ResNet같은 네트워크들은 skip connection을 통해 성능을 높입니다. 이와 같이 NASNet에서도 skip connection을 생성하기 위해 다음과 같이 설정했습니다.
layer N에서 이전의 layer으로 부터 skip connection이 있는지를 결정하는 N-1개의 content-based sigmoid(anchor point)를 추가합니다.
\(h_j\)는 j번째 layer의 controller의 hiddenstate이고 그 값은 0 부터 N-1까지 가질 수 있다.
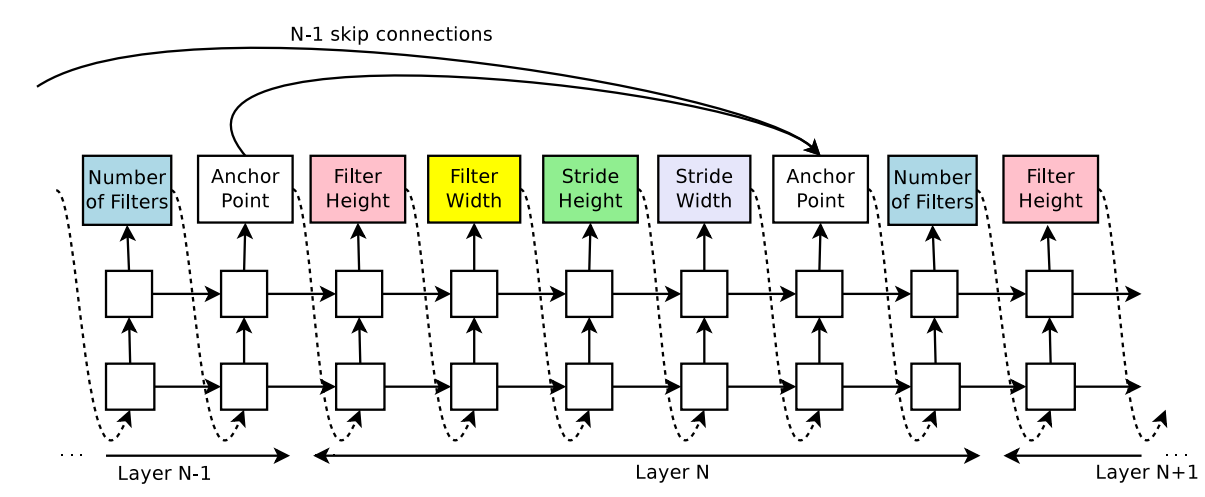
하지만 이렇게 연결하다보면 구조가 망가지는 경우가 있기 때문에 다음과 같은 규칙을 정한다.
- input layer로 쓴 layer는 다른 layer의 input layer가 되지 않는다.
- skip connection이 안되어있는 layer를 다 final layer에 connection을 만든다.
- 만약 skip connection시 layer의 size가 다르면 zero padding을 한다.
Result
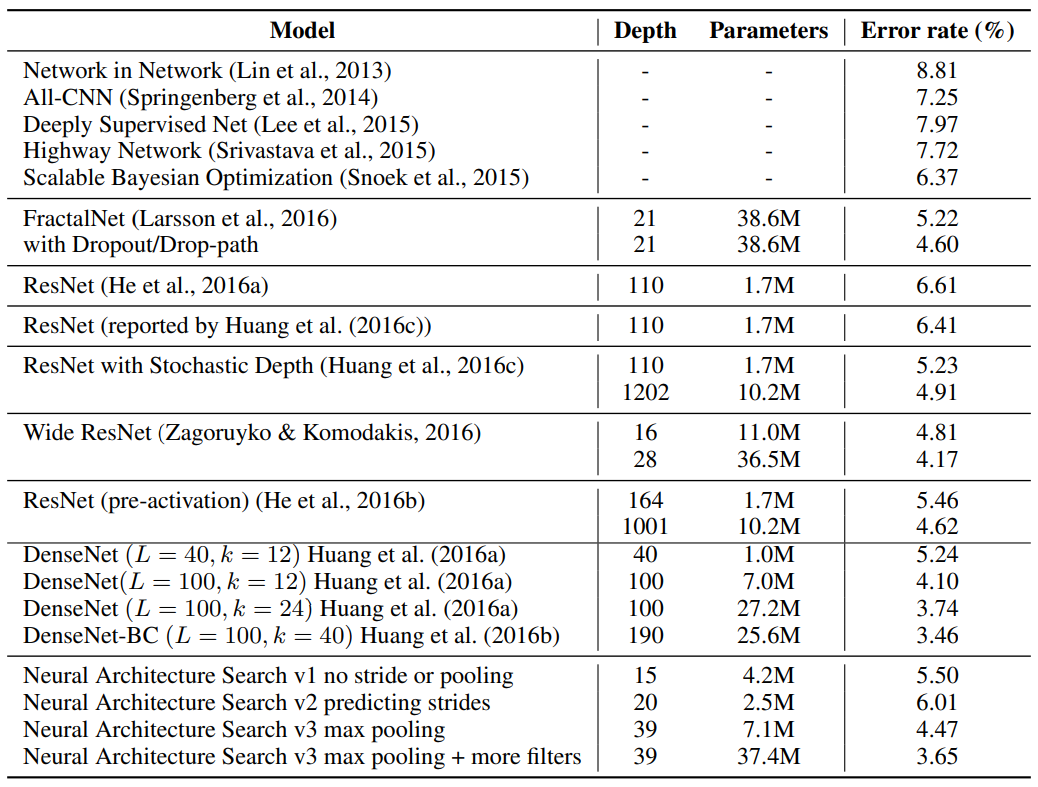
Opinion
NASNet의 정확도 자체는 당시 수동 설계된 네트워크(ResNet, DenseNet 등)와 비교해 압도적이지는 않지만, 사람의 직관 없이 기계가 설계했다는 점에서 큰 의의가 있습니다.
다만 NAS의 실용성에는 한계가 있었습니다. Controller를 학습시키기 위해 수백~수천 개의 child network를 학습해야 하므로, 논문에서는 800대의 GPU로 28일 동안 실험했습니다. 이 비용 문제는 이후 DARTS(differentiable NAS), Once-for-All 등 효율적인 NAS 방법론의 연구 동기가 됩니다.
그리고 실험 결과에서 filter들이 직사각형이 많다는 관찰이 있는데, 이는 무작위로 뽑아도 직사각형이 될 확률이 정사각형보다 높기 때문일 수 있습니다. NAS가 발견한 패턴이 정말 의미있는 것인지, 단순한 확률적 결과인지 구분하기 어려운 점이 NAS 연구의 해석 난이도를 높이는 요소입니다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: