FitNet
fitnet 논문 링크 많이 쓰이는 딥러닝 모델은 inference time에 많은 시간이 소요된다. 그리고 파라미터 수가 많아서 많은 메모리도 필요하다. 이러한 이유로 Knowledge Distillation을 사용한다. 하지만 이전의 연구들은 더 얕은 네트워크에 적용하지 않아 속도면에서 아쉬운 점이 있었다. 따라서 이 논문에서 더 얕은 네트워크를 사용하여 compression하는 방법을 제공한다.
Method
Review of Knowledge Distillation
이전 연구(Hinton & din, 2014)에선 student network가 학습할 때 제공된 label뿐만 아니라 teacher network의 output까지 학습하게 한다. \(P_T\)는 teacher의 output, \(P_S\)는 student의 output이라 하자. 또한 \(P_T\)는 true label과 유사하기 때문에 τ를 사용하여 soften시킨다.
student network는 다음을 최적화하는 것이 목표이다.
H는 cross entropy이고, λ는 두 cross entropy의 균형을 맞추는 hyper parameter이다.
Hint based Training
저자는 DNN을 학습시키기 위해 hint와 guide layer라는 것을 도입했다. hint는 student의 학습을 도와주기 위한 teacher의 hidden layer이다. 또한 guide layer는 teacher의 hint layer로부터 배우는 student의 hidden layer이다. 저자는 guide layer가 teacher의 hint layer를 학습하도록 목표를 잡았다. 이때 hint layer와 guide layer는 teacher와 student의 middle layer로 설정했다. 그리고 guide layer는 hint와 차원이 맞지 않기 때문에 regression layer를 추가했다.
\(u_h, v_g\)는 각각teacher와 student의 nested function이고 \(W_{Hint}, W_{Guided}\)는 teacher와 student의 parameter이다.
regression layer를 fully connected layer로 설정할 수 있지만 파라미터수가 많아지므로 cnn layer를 사용하여 \(N_{h,1} \times N_{h,2} \times O_{h} \times N_{g,1} \times N_{g,2} \times O_{g}\) 에서 \(k_1 \times k_2 \times O_{h} \times O_{g}\)로 줄일 수 있었다.
Training Method
FitNet(논문에서 제안한 방법으로 학습된 네트워크)은 teacher가 student를 가르치는 방법으로 다음과 같이 직관적인 학습과정을 거친다.
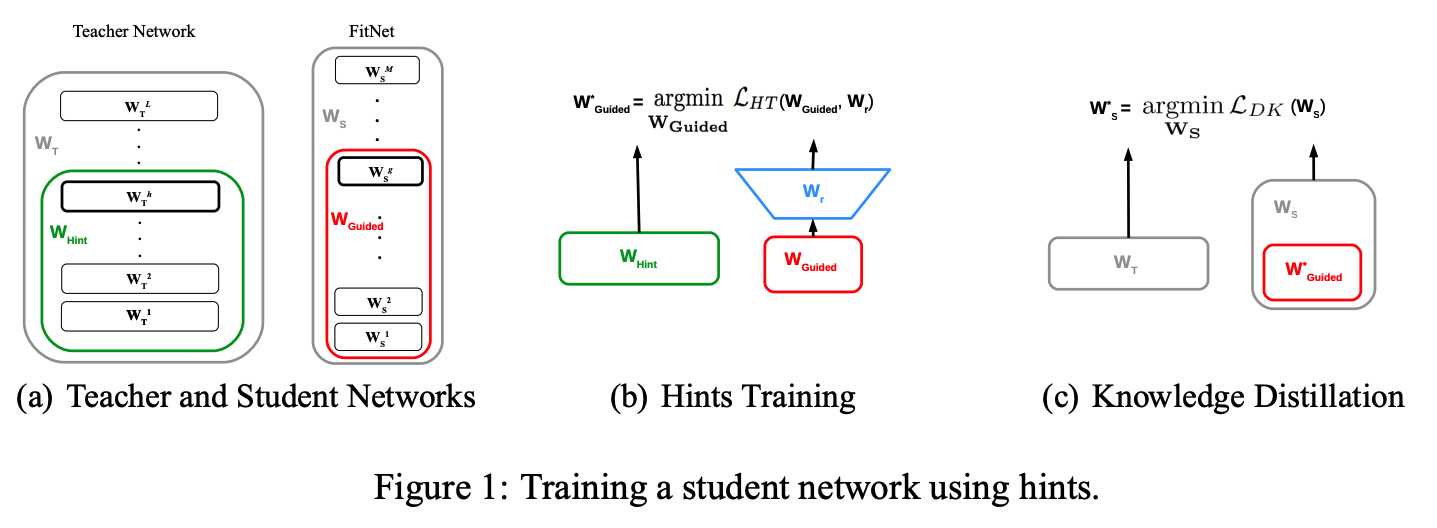
- 학습된 teacher network와 random initialized된 student network를 준비한다.
- hint와 guide layer를 가지고 regressor를 학습시킨다.
- hint와 regressor를 사용해 guide를 학습시킨다. 이 때 student의 학습이 일어난다.
이에대한 알고리즘은 다음과 같다.

Result
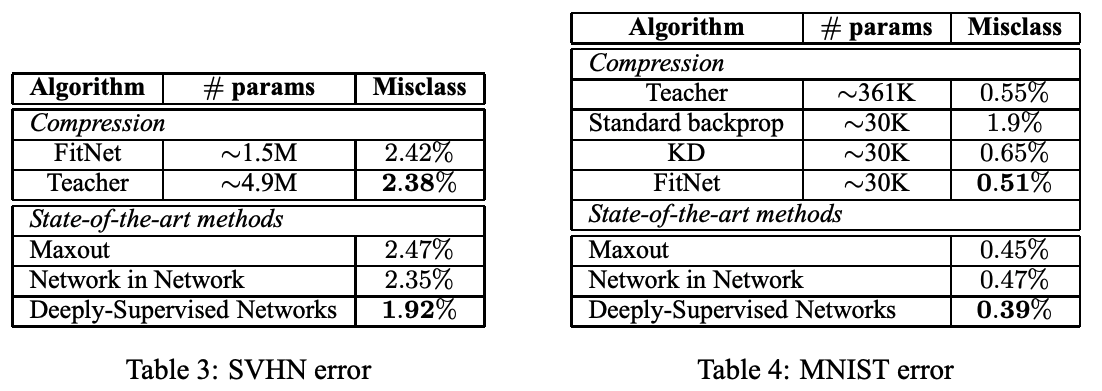
실험 결과, FitNet은 teacher보다 더 적은 파라미터를 사용하면서도 teacher에 근접하는 정확도를 달성했다. 특히 주목할 점:
- FitNet은 teacher보다 얇지만 더 깊다. 깊은 네트워크가 넓은 네트워크보다 파라미터 효율이 좋다는 것을 보여준다.
- Hint-based training 없이 단순히 KD만 적용하면 깊은 student의 학습이 불안정한데, hint가 중간 layer의 학습을 안내(guide)하여 이 문제를 해결한다.
- CIFAR-10, CIFAR-100, SVHN 등 다양한 데이터셋에서 일관된 성능을 보인다.
느낀점
Feature map 기반으로 knowledge를 전달한다는 아이디어는 이후 많은 distillation 논문(AT, PKT, CRD 등)에 영향을 주었다는 점에서 의의가 크다.
다만 regressor를 별도로 학습시킨다는 점에서 의문이 있다. Regressor를 학습할 때 teacher는 이미 의미있는 representation을 가지고 있지만, student는 random initialized 상태이므로 의미있는 representation이 없다. 따라서 두 representation space 사이의 매핑이 적절하게 학습되었는지는 불확실하다. 이후 연구들에서는 regressor 없이 직접 feature distance를 최소화하는 방식(AT 등)이 더 많이 사용된다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: