Bootstrap your own latent
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning (Grill et al., DeepMind, NeurIPS 2020)
BYOL 논문 링크 세상에는 많은 데이터가 존재하지만 이를 annotation하는 것은 많은 비용이 발생한다. Self-supervised learning은 레이블이 지정되지 않은 데이터에서 feature들을 추출하기 위해 학습하는 방법이다. 고전적인 방법으로는 AutoEncoder, GAN이 있지만 contrastive learning이 제시되고 큰 성능향상을 가져왔다. 하지만 contrastive learning은 negative label의 수에 의존적이고 color distortion에 민감하다는 단점이 있다. 먼저 contrastive learning에 대해 살펴보고 이를 BYOL이 어떻게 해결하였는지 살펴보자.
Contrastive Learning
Contrastive learning은 self-supervised learning의 한 종류이다. 이미지에서 data augmentation을 통해 image patch를 추출하게 되는데 같은 이미지에서 나온 image patch는 representation vector space에서 distance가 작게, 다른 이미지에서 나온 image patch는 representation vector space에서 distance가 크게 만든다. 이를통해 이미지의 feature를 나타내는 representation vector를 만든다.
Contrastive learning의 단점
1. Data augmentation에 의존적
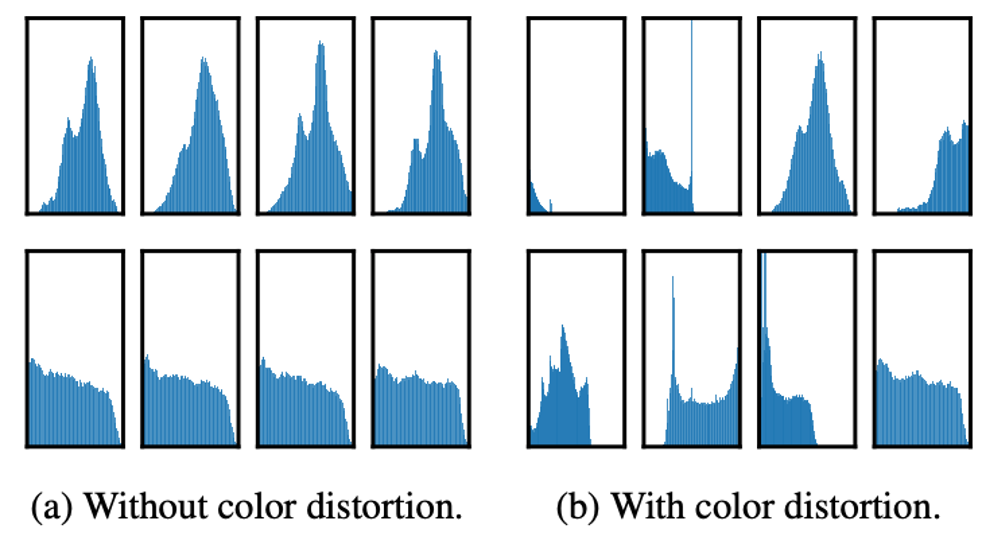
contrastive learning은 한 이미지 내에서 positive sample을 추출한다. 따라서 positive sample들은 비슷한 color histogram을 가지게 된다. 이를 그대로 contrastive learning에 사용할 경우 네트워크는 다른 유용한 정보 대신 color histogram만으로 positive sample과 negative sample을 구분하게 되어 모델의 성능이 낮아지게된다.
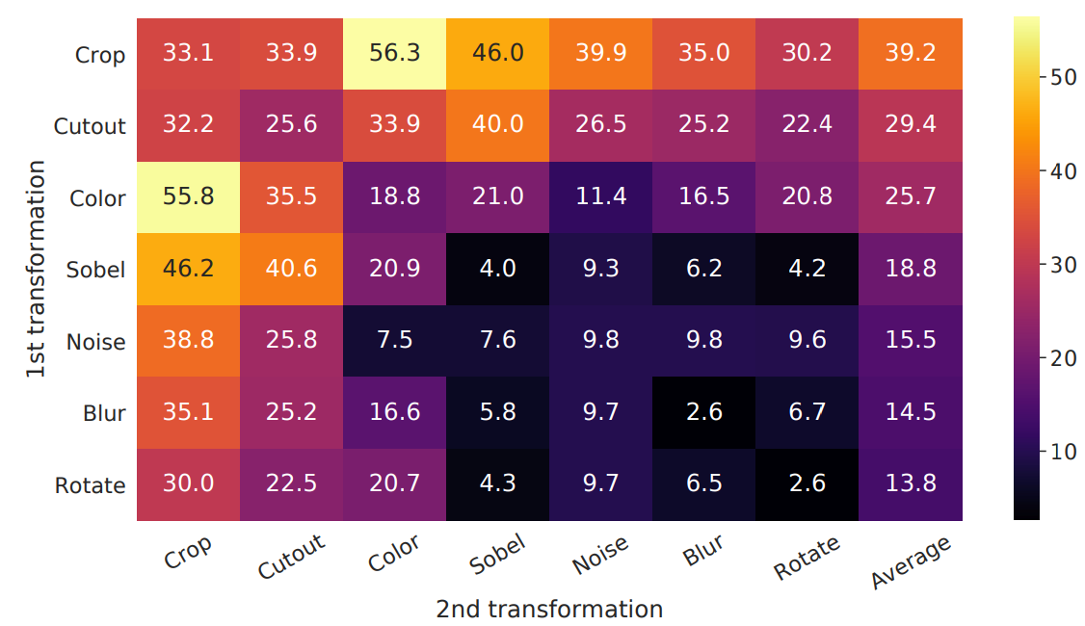
위의 그림은 SimCLR의 data augmentation으로 data augmentation의 조합에도 성능이 많이 달라진다.
2. Negative sample의 수에 의존적
\[\mathcal{L}_q=-log \frac{exp(q \cdot k_{+} / \tau)}{\sum_{i=0}^K exp(q \cdot k_i / \tau)}\]위는 contrastive learning의 loss function인 InfoNCE이다. 이 때 contrastive learning에서 positive sample만 사용하면 네트워크는 항상 같은 constant vector를 출력하여 model collapse가 발생한다. 따라서 이를 방지하기 위해 negative sample과의 비교도 하여 model collapse를 방지한다.
이는 loss function에서도 볼 수 있다. InfoNCE가 optimal value가 되었을 때 전개해보면 다음과 같다. 맨 아래인 식을 해석하자면 infoNCE는 Mutual information의 lower bound를 제한한다. 이 때 negative sample의 수 또한 lower bound를 제한해 negative sample의 수가 많을수록 성능이 향상되는 것을 알 수 있다.
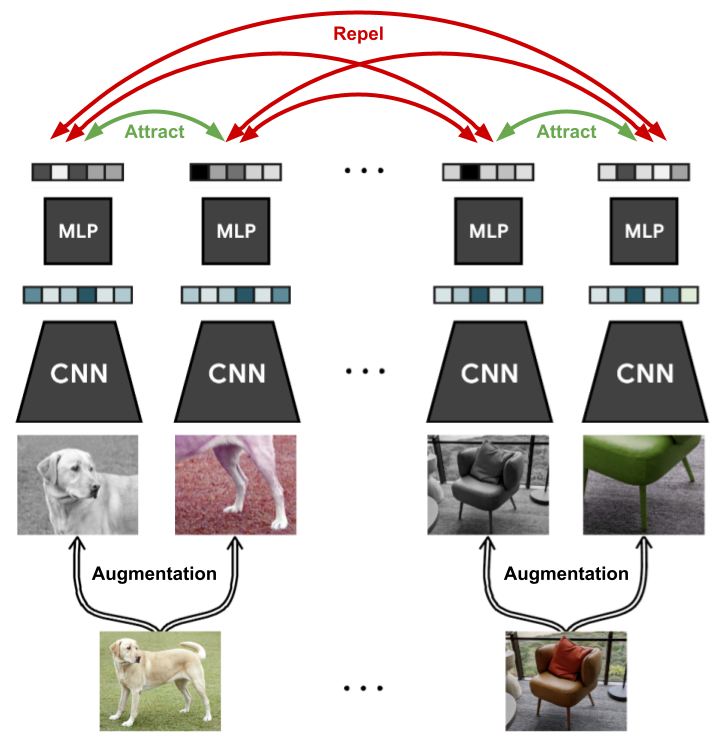
SimCLR은 batch에 positive sample과 negative sample을 함께 구성하여 negative sample의 수를 확보한다. 이러한 특성으로인해 batch size가 줄어들면 성능이 급격하게 하락하는 것을 볼 수 있다.
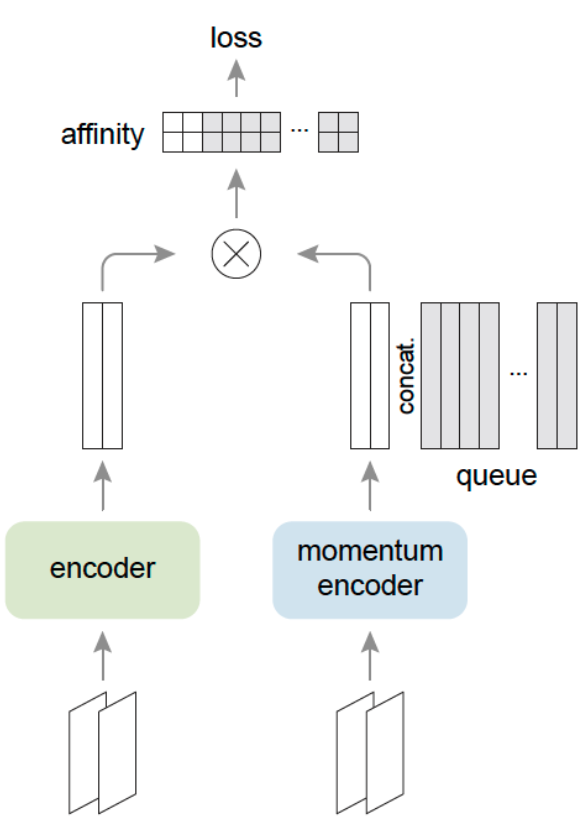
또한 MoCo는 momentum encoder를 사용하여 negative sample queue를 만들어 negative sample를 확보한다. 이러한 특성으로 batch size가 작아도 많은 negative sample을 확보할 수 있다.
BYOL
이 모든 과정을 model collapse를 방지하기 위해 하는 것이다. BYOL의 저자는 이를 해결하기위해 그저 encoder를 random initialization하여 실험을 진행했다.

Encoder를 random initialization한 후 parameter를 고정한다. 그리고 linear layer를 하나 붙여 ImageNet에 학습을 시킬 경우 정확도가 1.8%로 낮았다. 하지만 random initialization encoder의 representation vector를 label로 만들어 encoder를 학습시킨 후 위와같은 학습을 하면 정확도가 18.8%로 상당히 상승했다. 저자는 이에 아이디어를 얻어 실험을 진행하였다.
학습과정

- 구조가 동일한 online network와 target network를 만든다.
- Target network의 역할은 online network가 예측할 representation vector \(f_\mathcal{E}\)를 만든다.
- Online network의 역할은 \(f_\mathcal{E}\)를 예측하는 것이다.
- Representation vector를 그대로 사용하지 않고 projection layer \(g\)를 사용하여 projection vector \(z\)로 변환한다. (SimCLR 참고)
- \(z'_\mathcal{E}\)을 예측하기위해 Online network에 prediction layer \(q_{\theta}\)를 추가하여 asymmetric한 구조를 만들었다.
- Data augmentation pool \(\mathcal{T}\) 을 만들고 \(t\), \(t'\)를 뽑아 각각의 네트워크에 통과시킨다.
- online network의 output \(q_{\theta}(z_{\theta})\)와 \(z'_\mathcal{E}\)를 L2 normalize하여 \(\overline{q_{\theta}(z_{\theta})}\)와 \(\overline{z'_\mathcal{E}}\)를 만든다.
- \(\overline{q_{\theta}(z_{\theta})}\)와 \(\overline{z'_\mathcal{E}}\)의 L2 loss를 구한다.
- Symmetric한 구조를 만들기 위해 \(t\), \(t'\)를 뒤집어 다시 loss를 구한다.
- Online network의 parameter는 backpropagation을 통해 update한다.
- Target network의 parameter는 online network의 parameter의 exponential moving average(EMA)을 사용하여 update한다.
Why it works?
단순히 보기만해도 구조와 학습방법이 이상하고 왜 작동하는지 모르겠다. 저자는 “BYOL 의 prediction layer가 optimal 인 경우에는 undesirable equilibria 는 unstable 하다.”라고 한다. 즉, model collapse가 발생하기 어렵다는 것이고 대한 이유로 prediction layer와 EMA를 뽑았다.
Prediction layer
만약 prediction layer가 optimal solution이 \(p^{\star}\)라고 하자.
다음 parameter update는 다음과 같다.
만약 online network가 representation을 constant값을 출력한다면 다음과 같은 식이 성립한다.
이 때 constant representation vector보다 작은 representation vector가 존재하므로 다음 parameter update가 일어난다.
EMA
Target network를 update할 때 EMA를 사용하지 않고 gradient descent로 update하면 model collapse가 발생한다.
위의 식과 같은이유로 model collapse가 발생하면 parameter update가 일어나지 않는다.
Experimental Result

Backbone으로 ResNet50을 사용하였다. ImageNet에서 linear evaluation에서 성능이 좋았고 다른 ResNet backbone에서도 성능이 좋았다.

전체 dataset의 일부만 사용하는 semi-supervised learning에서도 같은 결과를 보였다

ImageNet에만 특화되어있는지 알기위해 다른 classification task에 적용을 했을 때도 대부분의 경우에 성능이 좋았다.
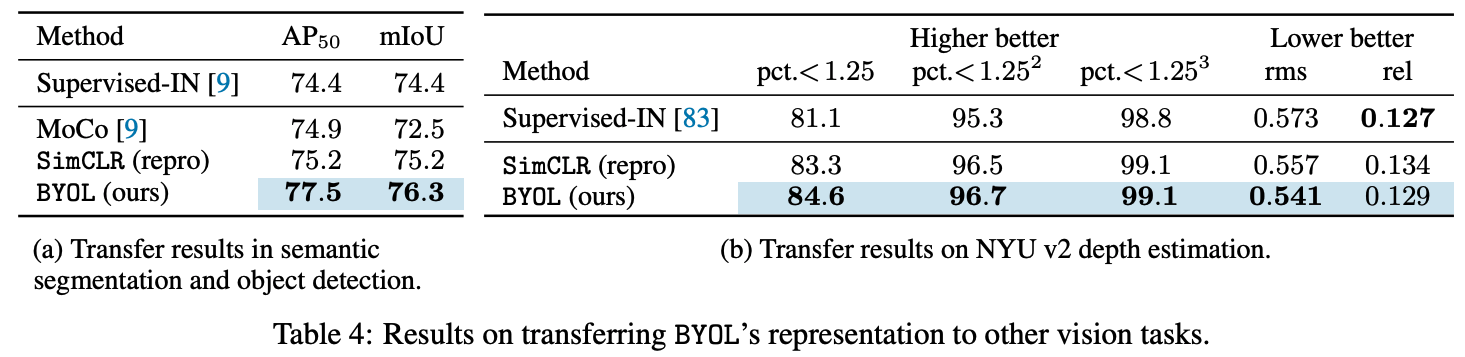
Image classification뿐만아니라 다른 vision task에서도 성능이 좋았다.
Ablation study
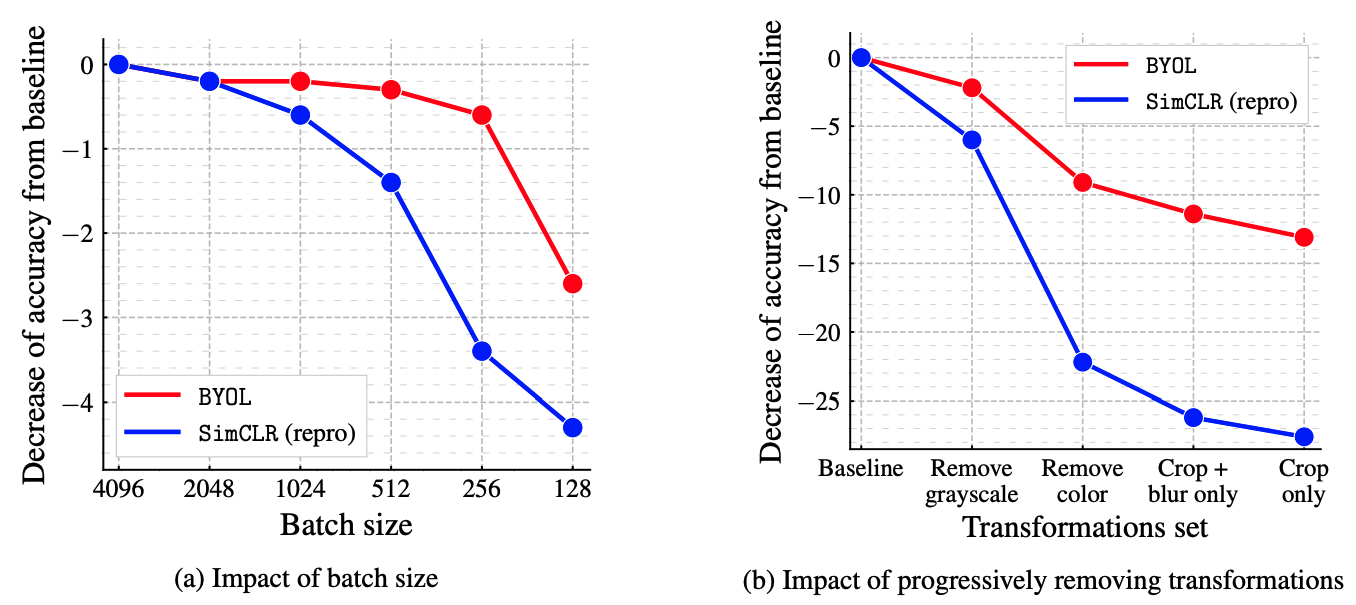
Batch size, data augmentation의 영향을 받으나 이는 SimCLR보다 더 적은 것으로 나타난다. BYOL은 positive sample만 사용하기 때문에 batch size에 둔감하다는 것이라 추정한다.
결론
BYOL은 self-supervised representation learning에서 SOTA를 달성했다. 이것이 왜 작동되는가는 아직도 많은 논쟁이 있지만 필자는 target network에서 EMA를 사용한 것이 negative sample을 대체했다고 생각한다. 이에대한 자세한 의견은 정리되지 않았으므로 추후에 이야기하겠다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: