Convolutional Character Network
Introduction
대부분 Scene Text Detection은 Text Detection과 Text Recognition으로 나누어져 있다. 하지만 이러한 방법은 representation을 제대로 학습하지 못해 성능이 하락한다. 따라서 저자는 Detection과 Recognition이 합쳐진 CharNet을 제안한다. 또한 CNN과 RNN을 같이 학습하는 것이 어려운 과제이기 때문에 Character 단위로 Text를 예측하는 모델을 제시한다.
Convolutional Character Network
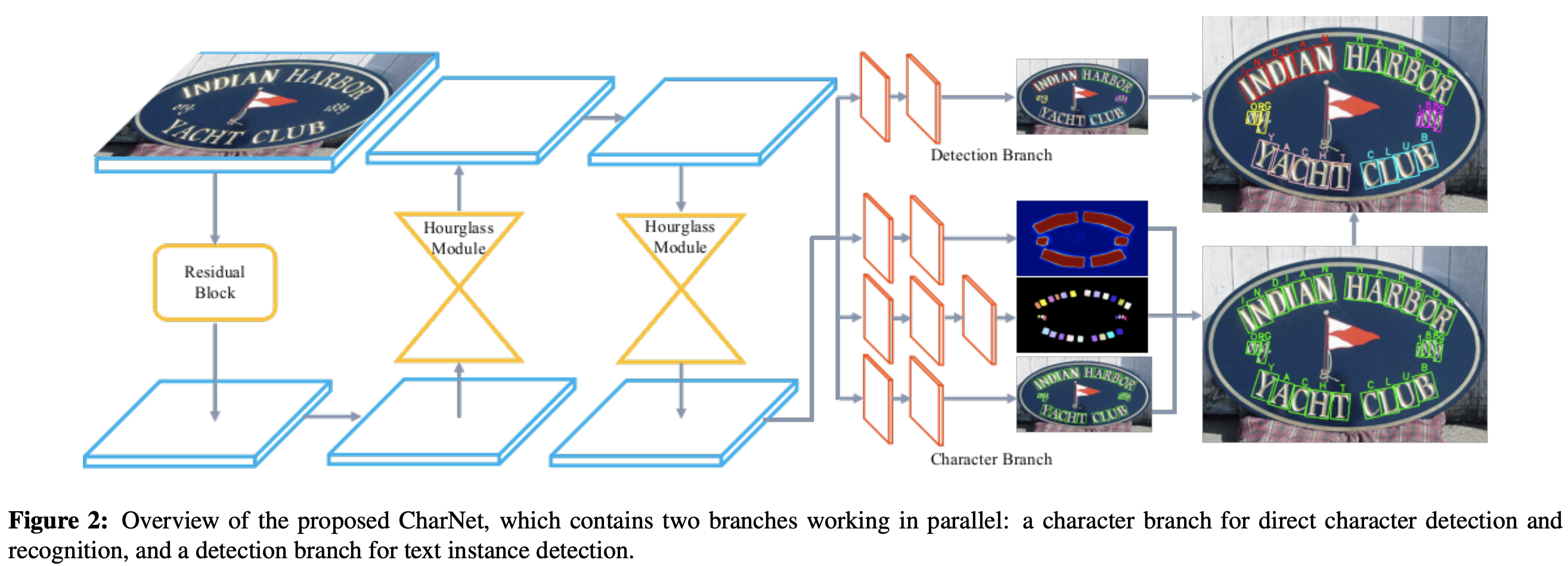
모델은 Detection Branch와 Character Branch로 나뉘어져 있다. Character branch는 character detection과 recognition을 위해 만들어졌고 Text detection은 Text의 bbox를 예측한다.
Backbone
Backbone으로 ResNet50을 사용하였고 높은 해상도를 위하여 featuremap size를 1/4로만 줄인다. 또한 두 개의 Hour Glass Module을 쌓는다. 이때 Hourglass-104에서 down sampling과 마지막 몇 개의 layer를 제거하여 Hourglass-88을 제작한다.
Character Branch
Word 단위로 인식하는 네트워크들은 필연적으로 RNN계열의 모델이 들어간다. 하지만 이로인해 더 많은 데이터와 작업이 필요하므로 word단위가 아닌 character단위로 만드는 것이 성능을 높일 수 있다. 따라서 저자는 Character branch를 도입했다.
Character branch는 Text instance segmentation, character detection, character recognition으로 이루어져있으며 앞 2가지는 3개(3x3, 3x3, 1x1)의 CNN layer을 가지고 있으며 character recognition은 4개의 CNN layer를 가지고 있다.
- Text instance segmentation: text와 non-text를 구분하는 역할로 2개의 channel을 가지고 있다
- Character detection: character의 bbox와 orientation을 예측하는 5개의 channel을 가지고 있다.
- Character recognition: 26개의 알파벳, 10개의 숫자, 32개의 특수문자를 분류한다.
이 때 Character의 bbox는 95%이상의 confidence를 갖는 것만 이용한다.
Text Detection Branch
Text detection branch는 더 높은 수준의 representation을 학습한다. 또한 word 사이 간격이 가까우면 character로 word를 만들기 어렵기 때문에 text detection을 같이사용한다.
- Multi-Orientation Text: text, non-text를 나누는 2채널 bbox와 orientation을 학습하는 5채널을 학습한다.
- Curved Text: Direction layer를 사용한다.
- Generation of Final Results: 만약 Text bbox와 character bbox이 겹치는 정도가 일정 수준을 넘어가면 해당 text에 character가 있다고 판단한다.
Iterative Character Detection
저자는 text detection/recognition을 위해 character-level annotation이 필요하나 많은 데이터셋은 word-level annotation을 가지고 있다. 이 때 Synth800k는 두 수준의 annotation을 모두 가지고 있는데 이는 현실데이터와 달라 현실데이터로 fine-tuning하지 않으면 성능이 낮다. 따라서 저자는 다음과 같은 전략을 취한다.
- Synth800k을 사용하여 pretrained weight를 제작한다.
- 1번에서 학습시킨 모델과 word-level annotation을 이용하여 weakly-supervised learning을 한다. 이 때 character bbox와 달리 character class는 label로 사용하지 않는다.
- 2번 과정에서 만들어진 모델을 가지고 weakly-supervised learning을 반복하여 성능을 높인다.
Weakly supervised learning은 1번을 학습시킨 모델을 사용하여 word-level annotation에서 character level annotation(label)을 만드는 것인데 만약 예측이 다음과 같은 조건을 만족시키면 “correct”라고 가정한다.
Text instance에 존재하는 character bounding box의 개수와 text instance의 label(word)가 일치하면 해당 pseudo label은 correct하다고 결정한다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: