Cross-Domain Adaptive Teacher for Object Detection
Introduction
데이터셋 중에서 label이 있는 데이터도 있지만 label이 없는 데이터도 있다. 이 두개의 domain이 다를 경우 이를 다루는 것은 쉽지 않다. 이 논문은 object detection에서 source domain은 label이 있고 target domain은 label이 없는 상황에 semi-supervised로 domain adaptation을 하는 방법을 다루고 있다.
Adaptive teacher
논문에서 semi-supervised learning을 위하여 teacher-student 모델을 사용한다.

학습은 다음과 같이 진행된다.
- Source domain을 이용하여 object detector를 학습한다.
- 학습된 object detector를 복사하여 teacher model과 student 모델을 제작한다.
- Teacher model은 target domain에 weak augmentation을 적용해 pseudo-label을 만든다.
- Student model은 strong augmentation된 source data로 supervised loss, strong augmentation된 target domain으로 unsupervied loss, discriminator로 discriminator loss를 계산한다.
- Student model은 gradient update로 학습한다.
- Teacher model은 EMA로 학습한다.
이 때 pseudo-label은 confidence threshold( \(\delta\) )를 사용하여 양질의 것만 사용한다.
Augmentation
기본적으로 teacher model은 source data에서 학습하고 target domain의 pseudo-label을 제작한다. 따라서 positive-false과 같은 오류가 발생할 수 있으므로 더 정확한 pseudo-label을 위해 pseudo-label 제작시 weak augmentation을 적용한다. 하지만 student는 믿을만한 pseudo-label을 가지고 있기 때문에 strong augmentationd르 적용한다.
- Weak augmentation: horizontal flipping, cropping
- Strong augmentation: randomly color jittering, grayscaling, Gaussian blurring, and cutting patches
Loss
loss는 supervised loss, unsupervised loss, discrimination loss를 사용한다. Pseudo-label에서 사용하는 confidence threshol(\(\delta\))는 class의 confidence만 반영하고 bouding box의 confidence를 반영하지 않는다. 따라서 unsupervised loss에서는 class loss만을 사용한다.
\[\mathcal{L}_{sup}(X_s, B_s, C_s)=\mathcal{L}_{cls}^{rpn}(X_s, B_s, C_s) +\mathcal{L}_{reg}^{rpn}(X_s, B_s, C_s) +\mathcal{L}_{cls}^{roi}(X_s, B_s, C_s) +\mathcal{L}_{reg}^{roi}(X_s, B_s, C_s)\] \[\mathcal{L}_{unsup}(X_s, B_s, C_s)=\mathcal{L}_{cls}^{rpn}(X_s, B_s, \hat{C_s}) +\mathcal{L}_{cls}^{roi}(X_s, B_s, \hat{C_s})\] \[\mathcal{L}_{dis}=-d \times logD(E(X))-(1-d)\times log(1-D(E(X))\]EMA
Teacher model의 update는 EMA를 사용한다.
\[\theta_t \leftarrow \alpha \theta_t + (1-\alpha)\theta_s\]Result
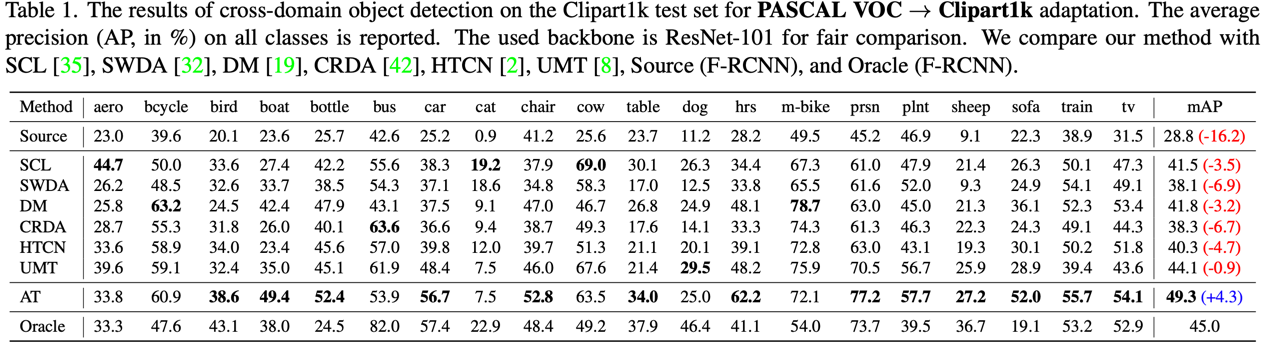
여러 domain adaptation 벤치마크에서 AT(Adaptive Teacher)는 기존 방법 대비 일관되게 SOTA를 달성했다.
특히 주목할 점은 Cityscapes → Foggy Cityscapes 실험에서 AT가 fully supervised learning (Oracle)보다 높은 성능을 보인다는 것이다. Source domain의 깨끗한 이미지로 학습한 teacher가 target domain의 안개 이미지에 대해 pseudo-label을 생성하고, student가 strong augmentation으로 학습하면서 더 robust한 representation을 학습한 것으로 해석할 수 있다.

Ablation 결과를 보면, 각 구성 요소의 기여가 명확하다.
| 구성 요소 | 효과 |
|---|---|
| EMA (Teacher update) | Student의 noisy gradient를 smoothing하여 안정적인 pseudo-label 생성 |
| Weak/Strong augmentation | Teacher는 정확한 pseudo-label을, Student는 robust한 feature를 학습 |
| Discriminator | Source-target domain 간 feature alignment으로 domain gap 감소 |
| Confidence threshold (\(\delta\)) | 저품질 pseudo-label 필터링으로 noise 감소 |

Confidence threshold \(\delta\)가 너무 낮으면 noisy한 pseudo-label이 포함되고, 너무 높으면 학습 데이터가 부족해진다. 적절한 \(\delta\)를 선택하는 것이 중요하며, 논문에서는 class별로 다른 threshold를 사용하여 class imbalance도 함께 해결한다.
이 논문의 의의
AT는 semi-supervised learning의 Mean Teacher와 domain adaptation의 adversarial training을 하나의 프레임워크로 통합한 것이 핵심이다. Teacher-student 구조로 pseudo-label의 품질을 점진적으로 개선하면서, discriminator로 domain gap을 줄이는 두 가지 목표를 동시에 달성한다. 특히 Oracle보다 높은 성능을 보이는 것은 strong augmentation과 pseudo-label 학습이 단순한 supervised learning보다 더 robust한 모델을 만들 수 있음을 보여준다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: