DINE: Domain Adaptation from Single and Multiple Black-box Predictors
DINE: Domain Adaptation from Single and Multiple Black-box Predictors
Introduction
정제된 데이터가 많이 있지만 새로운 도메인에 접근하려면 labeling을 진행하기 힘든 경우가 많다. 따라서 이를 위한 Unsupervised Domain Adaptation(UDA) 연구가 진행되고 있다. 하지만 UDA의 문제점이 존재한다.
개인정보
의료분야와 같은 개인정보로 인해 Source data에 접근이 힘든 경우가 있어 UDA시 이를 활용할 수 없을 수 있다. 또한 GAN을 이용하는 방법에서는 source data가 재생산 가능하여 또 다시 개인정보 문제가 나타날 수 있다.
Network Architecture
보통의 UDA는 같은 네트워크 구조에서 진행한다. 하지만 사용자의 환경에 따라 경량화 네트워크를 쓸 수도 있기 때문에 다른 네트워크 구조에서도 작동할 수 있어야한다.
저자는 기존의 UDA는 위의 두 가지 문제점을 가지고 있다고 판단하여 source model이 완전히 black-box인 상황에서도 작동하는 DINE을 제시했다.
Methodology
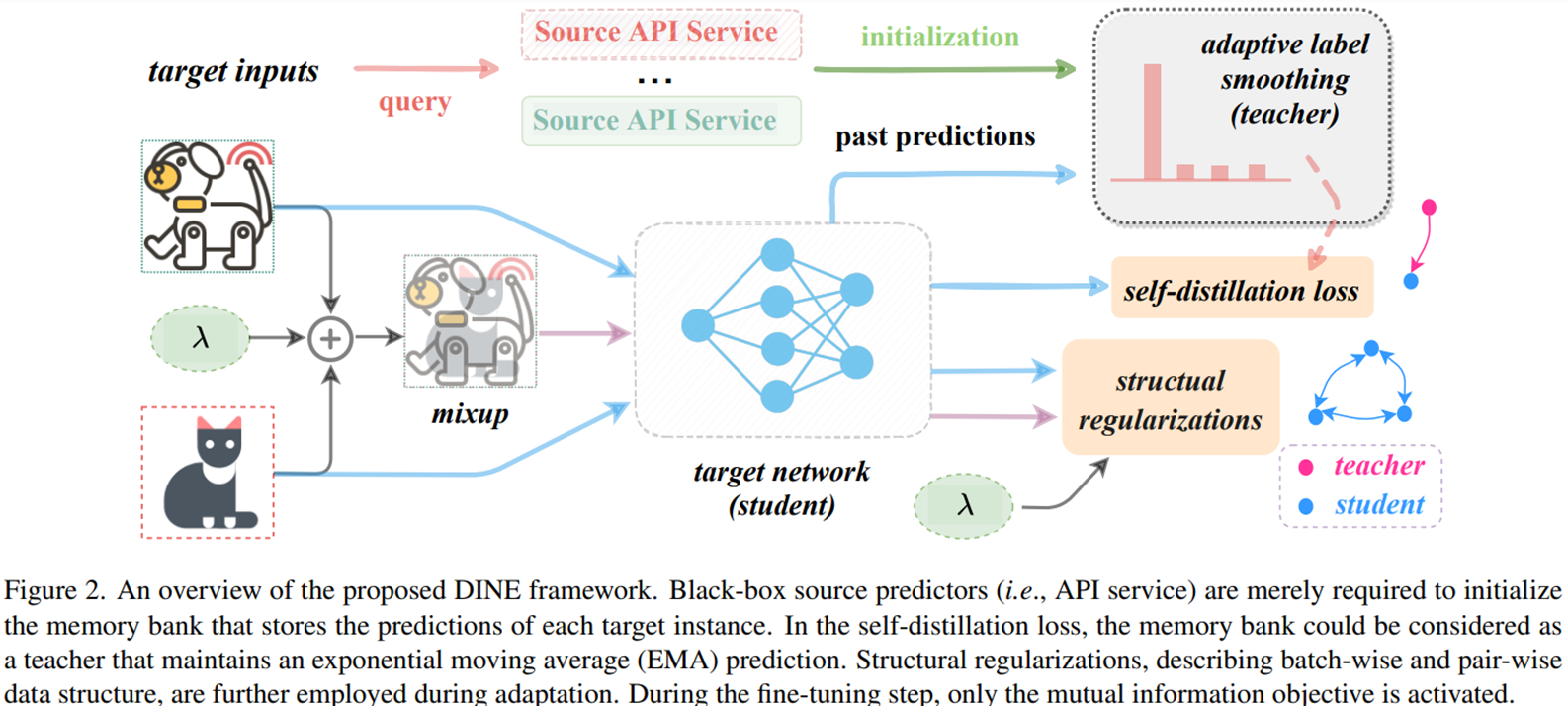
Notation
- Source Domain: \(n_s\) 개의 data, \(x_s^i \in \mathcal{X}_s, y_s^i \in \mathcal{Y}_s\) 에 대하여 \(\{x^i_s, y^i_s\}^{n_s}_{i=1}\)
- Target Domain: \(n_t\) 개의 data, \(x_t^i \in \mathcal{X}_t, y_t^i \in \mathcal{Y}_t\) 에 대하여 \(\{x^i_t, y^i_t\}^{n_t}_{i=1}\)
저자는 \(\mathcal{Y}_s=\mathcal{Y}_t\) 또는 \(\mathcal{Y}_s \supset \mathcal{Y}_t\) 인 경우를 다루고 있다.
Source Domain Model
Source domain model 은 backbone network에 fc layer를 결합하여 사용한다. Source domain model을 학습시킬때는 일반적인 학습방법으로 label smoothing을 적용하여 학습을 시킨다.
\[\mathcal{L}_s(f_s;\mathcal{X_s},\mathcal{Y}_s)=-\mathbb{E}_{(x_s, y_s)\in \mathcal{X}_s \times \mathcal{Y}_s}(q^s)^Tlogf_s(x_s)\]Target Domain Model
Target domain model을 학습시키기 위해서는 source model의 noise를 보정해줘야 한다. 따라서 저자는 두 가지 방법을 사용한다.
- Adaptive self-knowledge distillation
- Distillation with structural regularizations
Adaptive self-knowledge distillation
Target model 또한 backbone network에 fc layer를 결합하여 사용한다. 하지만 source model과 backbone 구조는 다를 수 있다.
기존의 kowledge distillation은 다음과 같다.
\[\mathcal{L}_{kd}(f_t;\mathcal{X}_t,f_s)=\mathbb{E}_{x_t\in \mathcal{X}_t} \mathcal{D}_{kl}(f_s(x_t)||f_t(x_t))\]source domain model의 예측값과 target domain model의 kl divergence가 최소가 되도록 학습을 진행한다. 하지만 저자는 source domain과 target domain의 차이로인해 noise가 발생할 것이라고 했고 이를 보정하기 위해 Adaptive Label Smoothing(AdaLS)을 제안한다.
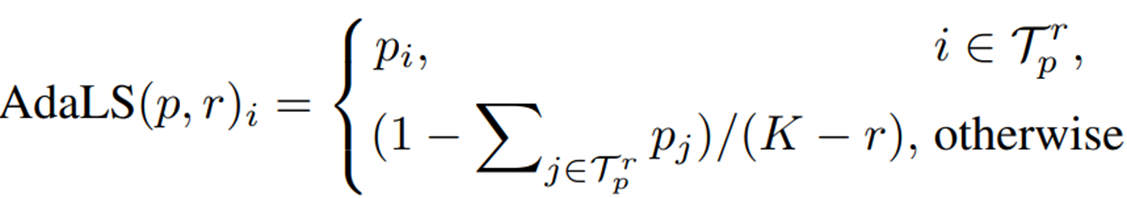
즉, top r개의 probability만 가져오고 나머지는 smoothing한 결과를 가져와 K-r개의 예측값은 noise라 판단하여 무시하는 것이다. 저자는 이를 통해 self-weighted pseudo labeling효과를 낼 수 있다고한다. 만약 Source model이 여러개이면 AdaLS의 평균값을 사용한다.
\[P^T \leftarrow \frac{1}{M}\sum^{M}_{m=1}AdaLS(f_s^{(m)}(x_t))\]논문에서는 추가로 noise 감소를 위해 self-distillation strategy를 사용했다. EMA를 통해서 target domain model의 self-distillation을 하는 것이다.
\[P^T(x_t) \leftarrow \gamma P^T(x_t)+(1-\gamma)f_t(x_t), \forall x_T \in \mathcal{X}_t\]Distillation with Structural Regularizations
저자는 AdaLS로는 noise regularization이 부족하다 생각했고 structural regularization을 사용했다.
Mixup
Target domain network의 예측값으로 mixup loss를 만들어 target domain structural information을 사용했다. 이미지의 linear combination의 예측과과 각각의 예측의 linear combination을 이용하여 target domain에 대한 구조적 정보를 만든 것이다.
\[\mathcal{L}_{mix}(f_t,\mathcal{X}_t)=\mathbb{E}_{x_i^t,x_j^t \in \mathcal{X}_t} \mathbb{E}_{\lambda\in Beta(\alpha,\alpha)}\] \[l_{ce}({Mix}_{\lambda}(f_t^\prime(x_i^t), f_t^\prime(x_j^t)), f_t({Mix}_{\lambda}(x_i^t, x_j^t))\]Mutual Information
Image set을 이용하여 모델의 예측에 대한 엔트로피를 계상하여 global한 구조적 정보를 학습한다. 아래의 수식은 모든 예측값에 대한 엔트로피는 높혀 불명확한 것은 불명확하게, 이미지에 대한 예측값의 엔트로피는 낮춰 명확한 예측값은 명확하게 만든다.
\[\mathcal{L}(f_t; \mathcal{X}_t)=H(\mathcal{Y}_t)-H(\mathcal{Y}_t|\mathcal{X}_t)=h(\mathbb{E}_{x_t\in \mathcal{X}_t}f_t(x_t))-\mathbb{E}_{x_t\in \mathcal{X}_t}h(f_t(x_t))\]Loss
전체적인 Loss는 다음과 같다.
\[\mathcal{L}_t=\mathcal{D}_{kl}(P^T(x_t)||f_t(x_t))+\beta\mathcal{L}_{mix}-\mathcal{L}_{im}\]FineTune
DIRT-T의 영감을 받아서 secondary training을 진행한다. 이때 loss는 mutual information을 사용한다.
\[\mathcal{L}(f_t; \mathcal{X}_t)=H(\mathcal{Y}_t)-H(\mathcal{Y}_t|\mathcal{X}_t)=h(\mathbb{E}_{x_t\in \mathcal{X}_t}f_t(x_t))-\mathbb{E}_{x_t\in \mathcal{X}_t}h(f_t(x_t))\]Experiment
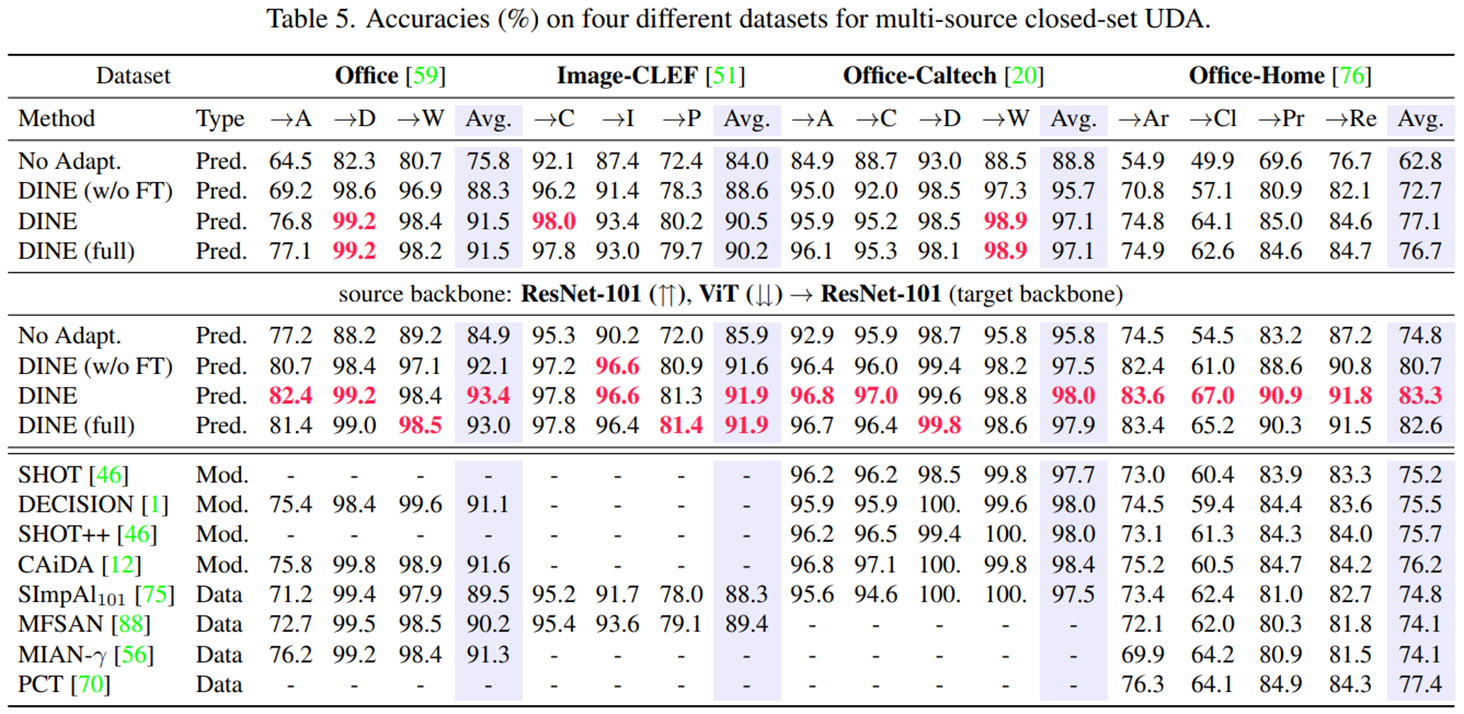
실험 결과, source data에 접근할 수 없는 방법들 중에서는 SOTA를 달성했고, source data에 접근 가능한 모델과 비슷한 수준의 성능을 보였다.
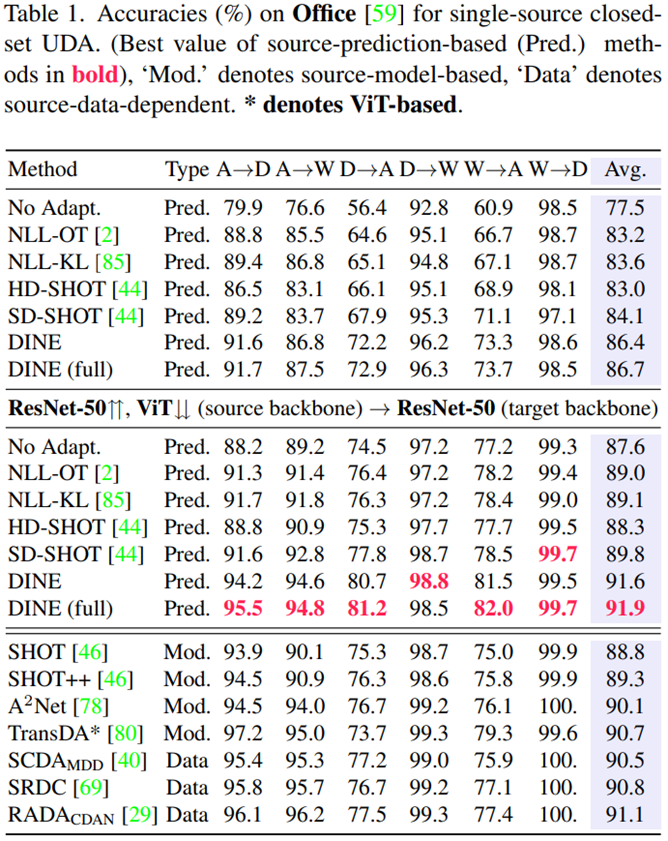
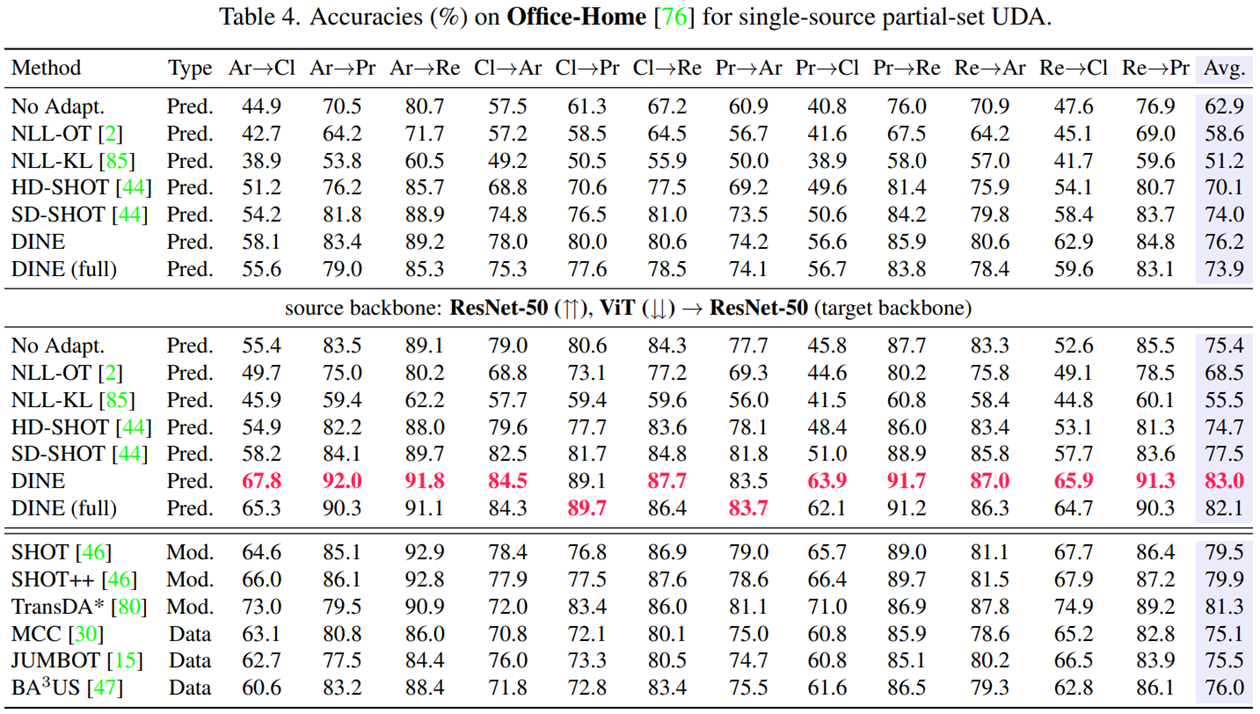
Analysis
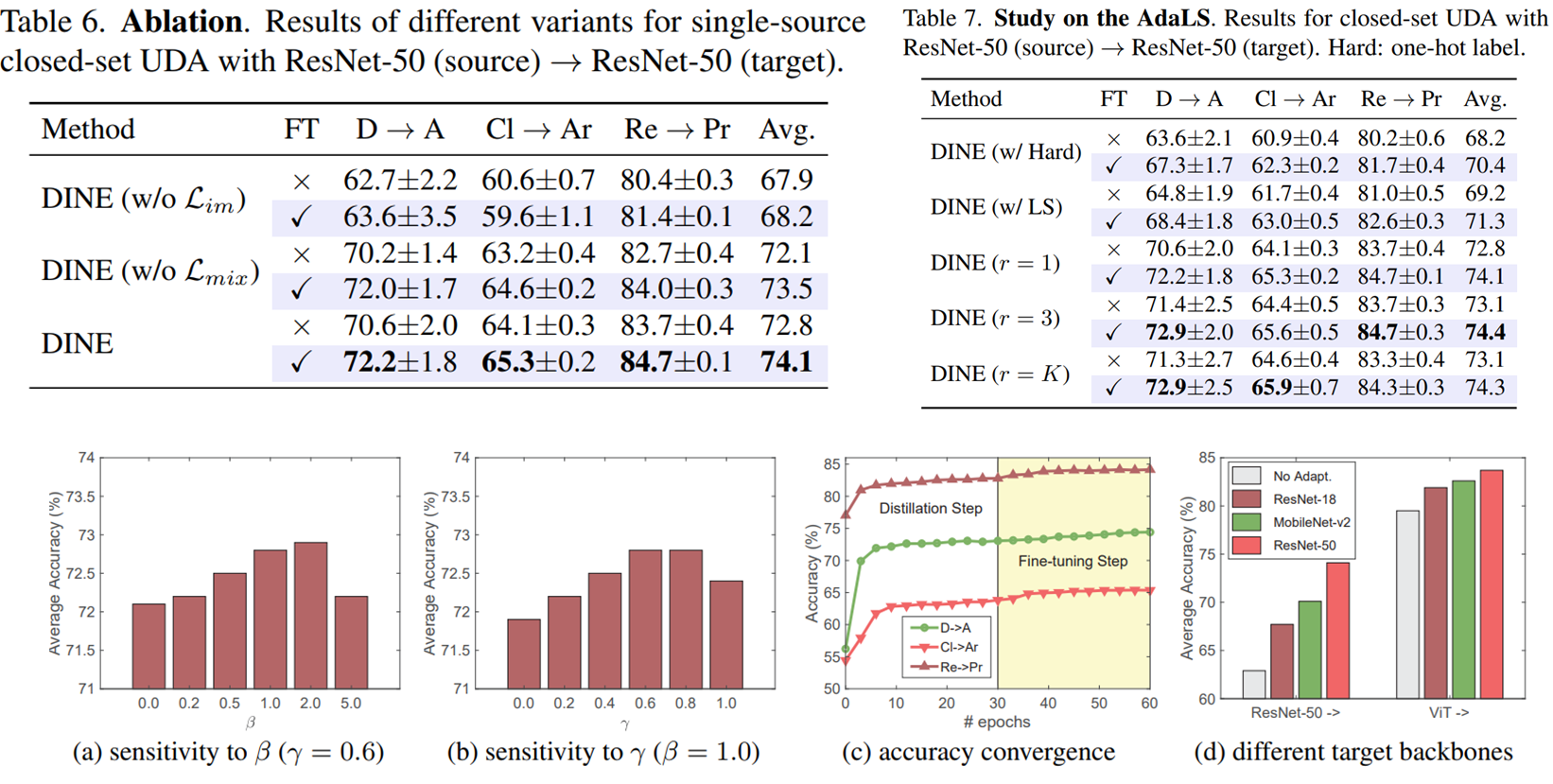
Mutual information loss가 학습에 가장 큰 영향을 미쳤고, AdaLS는 top r개를 선택하는 것이 효과적이었다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: