EdgeViT
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
Introduction
ViT는 global한 representation을 학습하면서 imagenet benchmark에서 압도적인 성능을 내고있다. 하지만 self-attention이라는 연산의 비용이 커서 inference speed나 power efficiency가 떨어진다. 이를 해결하기 위한 기존의 연구는 크게 다음과 같았다.
- Spatial Resolution에서 hierarchical architecture을 만들어 연산량을 줄인다.
- Locally-grouped self-attention mechanism을 사용한다.
- Key, value를 pooling하여 subsampling한다.
하지만 이러한 방법은 time cost가 중요한 mobile이나 edge platform에서 충분하지 못하다. 따라서 저자는 다음의 요소를 고려하여 EdgeViT를 설계했다.
1. Inference efficiency EdgeViT는 on-device에서 사용할 정도로 가볍고 에너지를 적게 사용해야한다. 기존에는 이를 측정하기위해 FLOPS를 주로 사용했지만 이는 latency과 energy consumption을 제대로 반영하지 못한다. 따라서 FLOPS는 추정치로만 참고하고 실제 mobile device에서 벤치마크를 진행한다.
2. Model size 현대 스마트폰은 RAM이 32GB일정도로 메모리량이 충분하다. 따라서 절대적인 모델크기를 고려하는 것은 현대 mobile device에는 적합하지 않아서 이는 크게 고려하지 않는다.
3. Implementation Friendliness 현실적으로 implementation을 하기위해서는 ONNX, TensorRT, TorchScript등 기존의 framework와의 호환성을 고려해야한다.
이를 고려하여 저자는 local-global-local bottleneck을 제안했고 이는 energy efficient하고 inference speed도 빠르다.
Local-Global-Local-BottleNeck
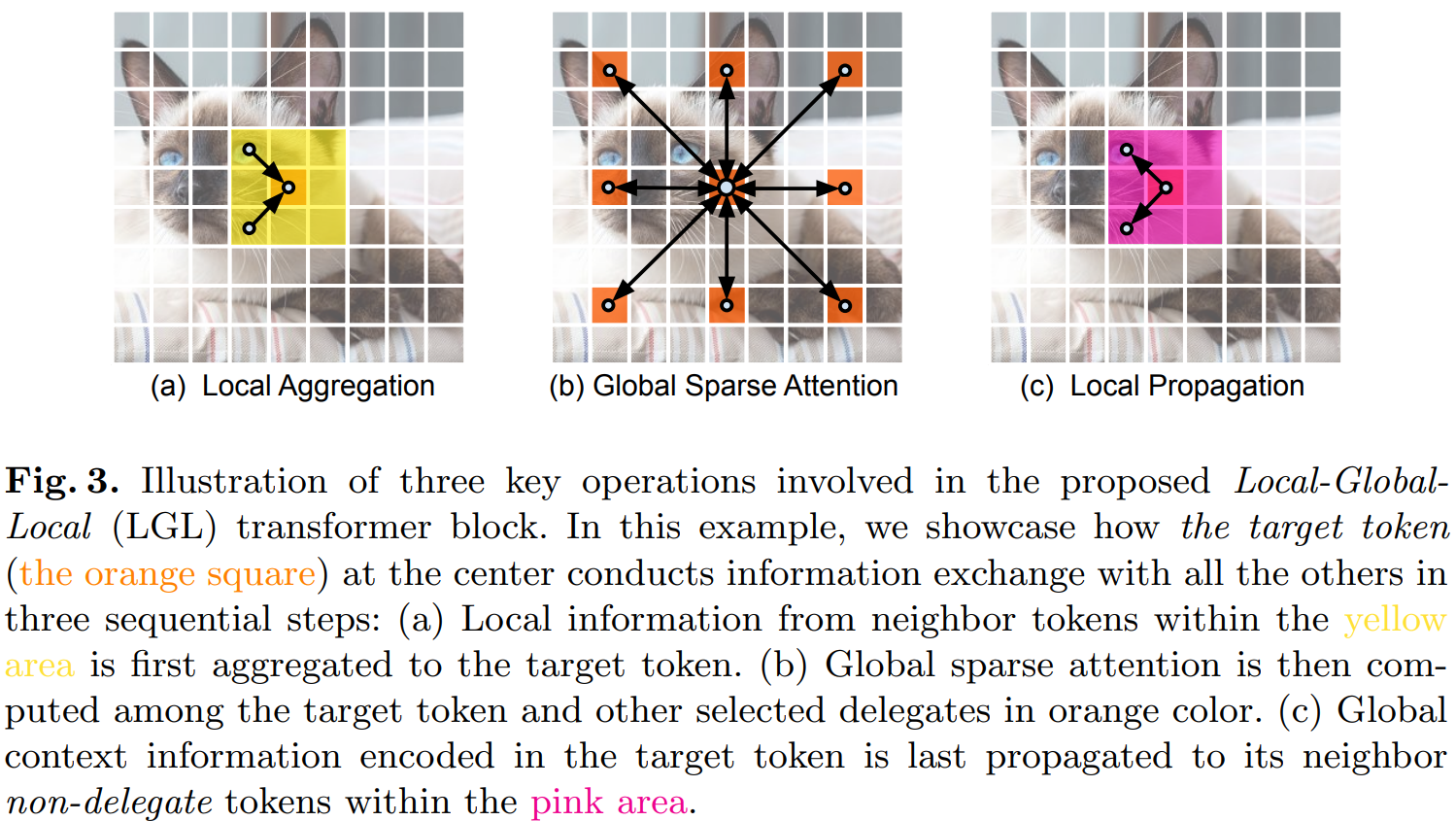
ViT의 성능이 좋은 이유는 global한 representation을 학습하기 유리하기 때문이다. Multi-head self-attention이 이를 가능하게 만들었으니 이를 모사하는 연산을 만드는 것을 필수적이다. 따라서 저자는 factorization을 통해 해당 연산을 3가지로 쪼개 모사했다.
Local Aggregation
연산을 가볍게 만들기 위해서는 절대적인 연산량을 줄여야 한다. 다행히도 이미지에서는 주변 픽셀은 비슷하다는 inductive bias가 존재한다. 따라서 전체 token에 대하여 attention을 계산하지 않고 주변 픽셀의 정보를 aggregation함으로써 scope를 줄일 수 있다. 따라서 attention 계산에 앞서서 locally proximate tokens의 signals을 integrate한다. 이는 기존 depth-wise separable convolution을 사용한다.
Global Sparse Attention
이제 attention에 대한 scope을 줄였으니 long-range relationship을 계산해야 한다. 하지만 모든 토큰에 대해 self-attention을 수행하면 비용이 크다. 저자는 각 \(r \times r\) local window에서 하나의 delegate token을 선택하여, delegate token들 간에만 self-attention을 수행한다. 이때 \(r\)은 sub-sampling rate이다.
기존 PVTs나 Twins-SVTs는 key와 value만 subsampling하고 query는 모든 위치에서 계산한다. 반면 EdgeViT는 query, key, value 모두 delegate token에서만 계산하므로 연산량이 더 적다. Sub-sampling rate는 stage별로 다르게 설정한다: \((r_1, r_2, r_3, r_4) = (4, 2, 2, 1)\). 마지막 stage에서는 \(r = 1\)이므로 standard MHSA와 동일하다.
Local Propagation
이제 global contextual information을 계산했으니 local window에 전파해야한다. 이는 간단하게 transpose convolution으로 구성했다.
위의 3가지 연산을 통해 local-global-local bottleneck을 구성한다. 그리고 이는 다음과 같은 식으로 연결된다. \(X=LocalAgg(Norm(X_{in}))+X_{in}\) \(Y=FFN(Norm(X))+X\) \(Z=LocalProp(GlobalSparseAttn(Norm(Y)))+Y\) \(X_{out}=FFN(Norm(Z))+Z\) 이 때 FFN은 fully connected layer 2개로 구성되어있으며 Normalization은 Layer Normalization을 사용한다.
Model Archtecture
``
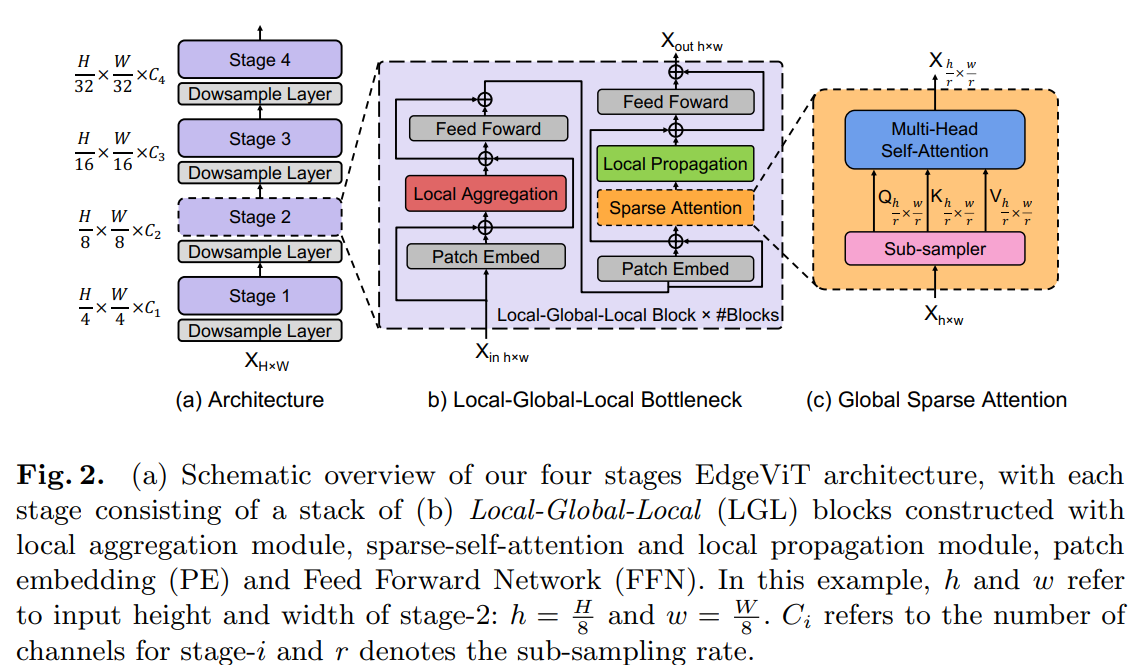
전체적인 모델구조는 위와 같다. Spatial resolution을 기준으로 hierachical 구조를 가지고 있다. Downsampling은 1번째만 제외하고 2x2 convolotion을 stride 2로 구성한다. 첫 번째 downsamping은 4x4 convolution은 stride 4로 연산한다. Patch embedding은 요즘 성능이 좋은 relative positional embedding[paper]을 사용한다.
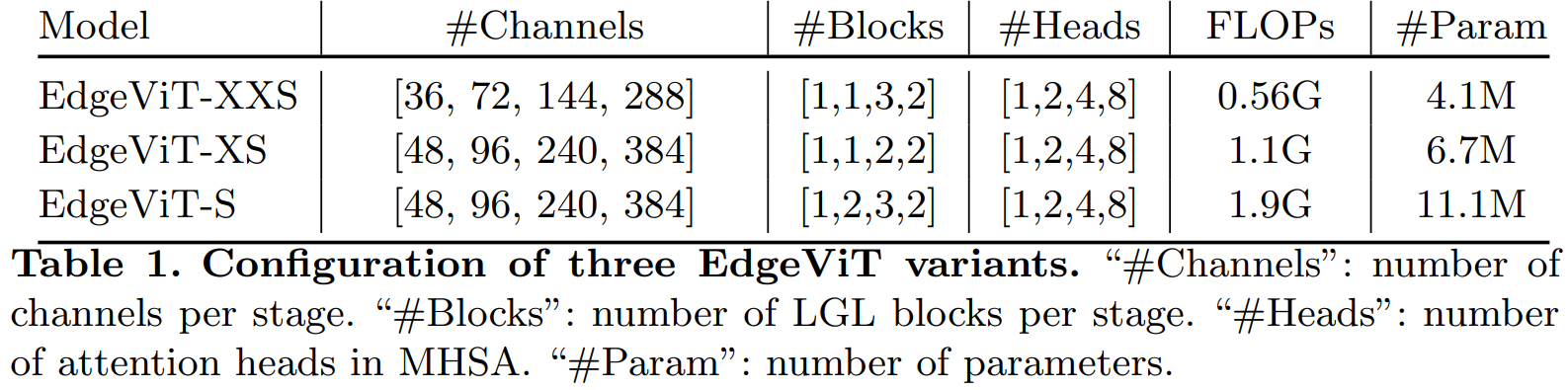
Scalability를 위해 3가지 크기의 모델을 제공한다.
| Model | Channels | Blocks | Heads | FLOPs | Params |
|---|---|---|---|---|---|
| EdgeViT-XXS | [36, 72, 144, 288] | [1,1,3,2] | [1,2,4,8] | 0.56G | 4.1M |
| EdgeViT-XS | [48, 96, 240, 384] | [1,1,2,2] | [1,2,4,8] | 1.1G | 6.7M |
| EdgeViT-S | [48, 96, 240, 384] | [1,2,3,2] | [1,2,4,8] | 1.9G | 11.1M |
Experiment
벤치마크 환경은 다음과 같다.
| 항목 | 설정 |
|---|---|
| Latency 측정 | Samsung Galaxy S21, Snapdragon 888 CPU |
| Framework | TorchScript Lite, 50회 반복 평균 |
| Energy 측정 | Monsoon High Voltage Power Monitor + Snapdragon 888 HDK8350 |
| NPU | 범용성이 떨어져 측정하지 않음 |
FLOPS나 parameter 수가 아닌 실제 디바이스에서의 latency와 에너지 소비를 측정한 것이 이 논문의 차별점이다.
ImageNet
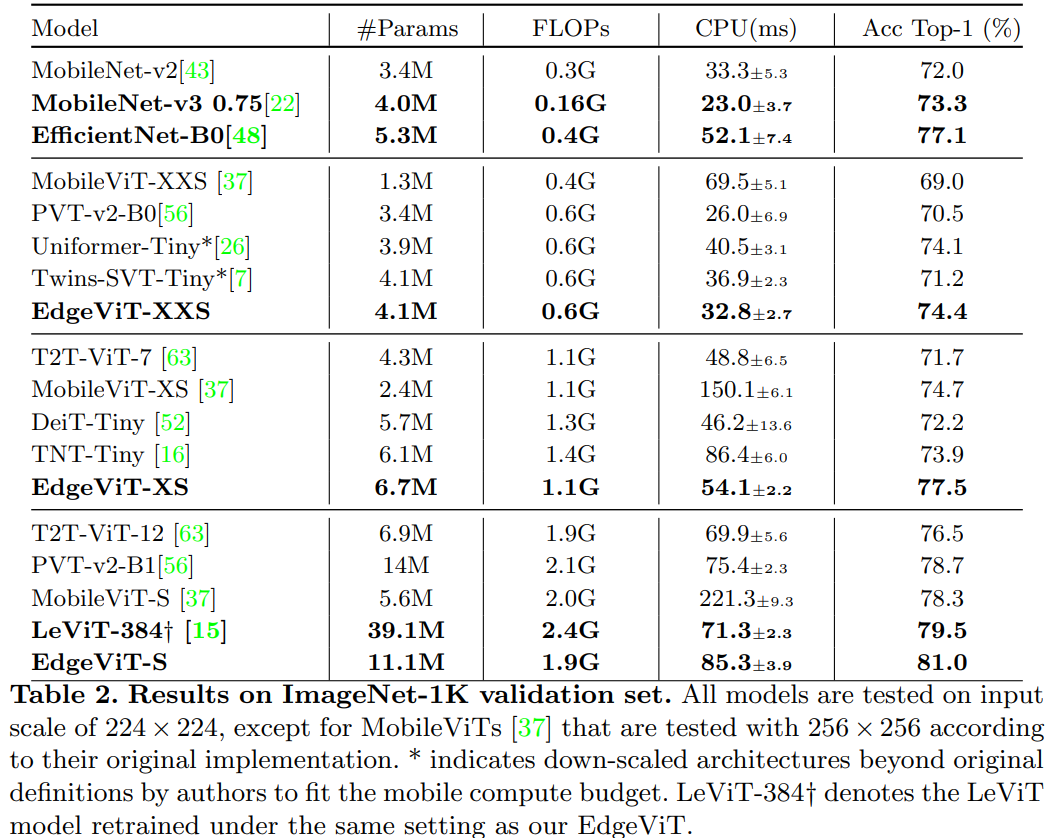
경량 ViT 모델들 중에서 EdgeViT는 accuracy-latency trade-off에서 좋은 성능을 보인다. 특히 DeiT-Ti, PVT-Tiny 등 기존 경량 ViT 대비 비슷한 정확도에서 latency가 낮다. 다만 MobileNetV2, EfficientNet-B0 같은 CNN 모델과 비교하면 latency에서는 아직 열세인데, 이는 ViT의 attention 연산이 모바일 하드웨어에서 아직 충분히 최적화되지 않았기 때문이다.
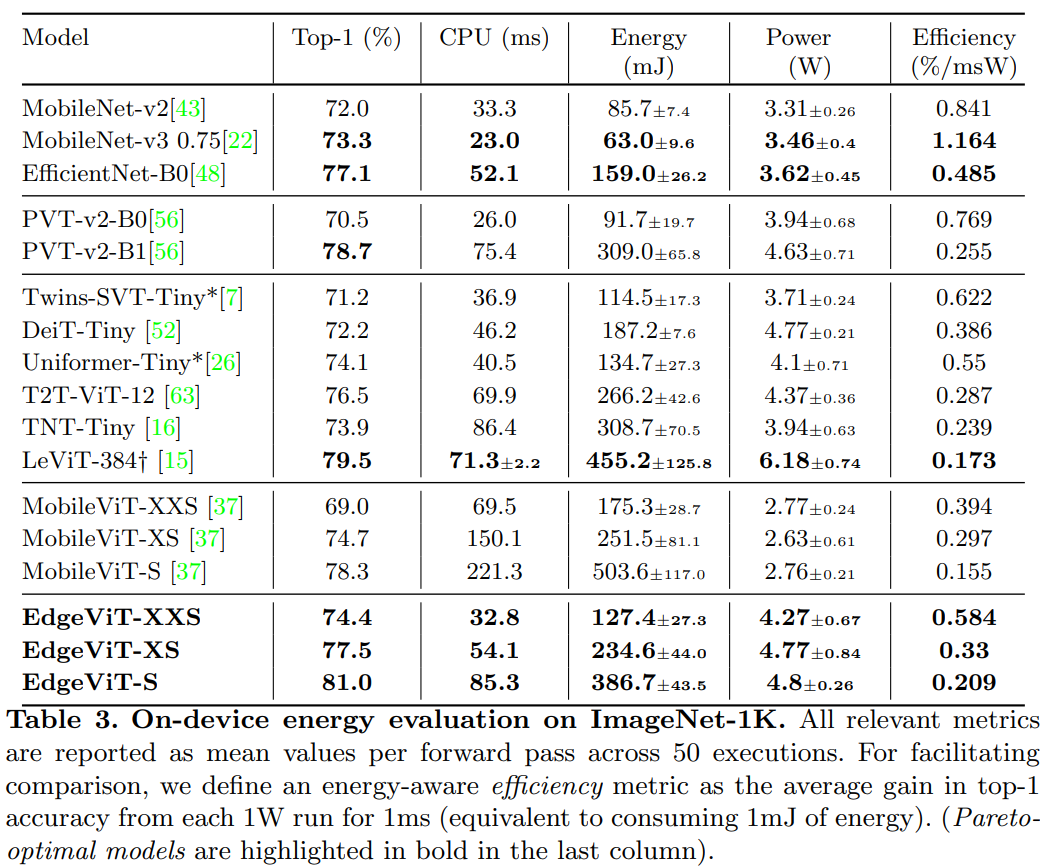
Energy efficiency 측면에서 EdgeViT는 특히 두드러진다. 정확도 대비 소비 전력을 측정하면 EdgeViT-S가 가장 효율적인 모델로 나타난다. 이는 Global Sparse Attention이 전체 토큰이 아닌 대표 토큰(delegate token)만 사용하여 연산량뿐 아니라 메모리 접근도 줄이기 때문이다. 배터리 기반 디바이스에서는 latency보다 에너지 효율이 더 중요한 경우가 많으므로, EdgeViT의 실용적 가치가 있다.
이 논문의 시사점
EdgeViT가 보여주는 핵심 메시지는 FLOPS만으로 모바일 효율성을 판단하면 안 된다는 것이다. FLOPS, parameter 수, latency, energy consumption은 각각 다른 지표이며, 실제 디바이스에서 측정한 latency와 전력 소비가 가장 신뢰할 수 있는 기준이다. Local-Global-Local bottleneck은 이론적으로 우아하지만, 실제로는 CNN 대비 모바일 추론 속도에서 아직 gap이 있다. 이는 하드웨어 최적화(NPU 지원 등)가 진행되면 좁혀질 수 있는 부분이다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: