Fairness-aware Data Valuation for Supervised Learning
들어가기 앞서
Active learning과 class imbalance를 찾던 도중 발견한 논문이다. 그래서 FairML 분야는 아는 것이 없고, 이 논문이 좋은지 나쁜지도 판단이 안 된다. 하지만 해당 논문의 개념도 간단하고, 이런 것을 고려하면서 sampling을 하는 것도 좋겠다는 생각에 논문을 정리하고자 한다.
Introduction
기존의 data valueation 연구는 데이터를 특정한 performance related value로 embedding한다. Active learning에서 “해당 train instance를 추가하면 모델의 성능이 올라가겠다”를 목적으로 entropy를 사용하여 embedding하는 방법도 있다. 하지만 추천시스템에서 해당 value만 사용할 경우 특정 그룹이나 인종에 안 좋은 데이터를 추천해주는 등 여러 안 좋은 점들이 있다. 따라서 fairness도 고려되어야 하는데 기존까지는 performance와 fairness를 동시에 고려하는 연구는 많지 않았다. 저자는 entropy를 기반으로 하여 두 가지 factor를 모두 고려하여 data를 utility value에 embedding하는 framework를 제안하였고 이를 이용하여 더 좋은 data sampling, re-weighting을 할 수 있었다.
Fairness-aware Data Valuation
Framework
일단 저자는 utility개념을 빌려왔는데, 해당 논문에서 utility는 performance와 fairness를 종합하는 function을 의미한다. Single data instance \(i\) 에 대해 performance-related valuation은 \(v_{y_i}\) , protected attribute에 대한 fairness-related valuation은 \(v_{z_i}\) 로 표시한다. Utility function은 다음과 같다.
\[U_i(v_{y_i},v_{z_i})=\alpha(v_{y_i})+(1-\alpha)v_{z_i}\]이 때 \(\alpha \in [0,1]\) 이다. 만약 fairness를 subgroup으로 나눈다면 다음의 식으로 확장할 수 있다.
\[U_i(v_{y_i},v_{z_i})=\alpha(v_{y_i})+\sum_{j=1}^{k}\beta v_{z_{j_i}}\]Entropy metric
먼저 저자는 performance related value를 instance \(i\) 의 prediction \(y_{i}\) 의 entropy로 정의했다.
\[V_{y_i}=E_{y_i}=\hat{y}_i\cdot {log}_2\hat{y}_i+(1-\hat{y}_i)\cdot {log}_2(1-\hat{y}_i)\]해당 수식은 active learning에서 영감을 받았다. Entropy가 높다는 것은 모델이 해당 instance를 잘 예측하지 못한다는 이야기이고, 추후에 이를 집어넣으면 성능이 높아진다는 것을 예상할 수 있다. 하지만 실제 상황에서는 애매한 instance뿐만 아니라 noise 또한 entropy가 높아져서 성능이 더 낮아질 가능성도 있다. 하지만 여러 task에서 해당 방법은 성능이 준수하다는 것으로 나와서 저자는 entropy를 사용했다.
저자는 fairness-related valueation또한 entropy로 정의했다.
\[V_{z_i}=E_{z_i}=\hat{z}_i\cdot {log}_2\hat{z}_i+(1-\hat{z}_i)\cdot {log}_2(1-\hat{z}_i)\]이 수식이 왜 되는지는 이해가 잘 안되지만 저자에 말은 이러하다.
In the second case, where the variable in question (Z) is not the target for the task at hand, and is seen by the model even at inference time, we prioritize observations where the model had more difficulty in establishing a relationship among X, Y, and Z, leveraging the fact the model has no explicit incentive to draw such relationships. This is directly related to mitigating the base bias condition of the taxonomy of Pombal et al. (2022a) ( P[X, Y] 6= P[X, Y Z] ), and so related to promoting fairness.
- Fairness-aware data valuation for supervised learning, Pombal et al, 2023 -
내가 이해한 대로 적자면 여러 예측 모델이 있는데 이들 모두의 예측값의 entropy가 높다면 bias가 없는 데이터이다. 하지만 특정 모델에서 entropy가 높아 잘 예측한다면 그 데이터는 특정 모델에 적합한 bias가 있는 데이터일 것이다. 따라서 fairness 또한 entropy로 표현할 수 있게 되는 것이다.
이렇게 구한 performance related valuation과 fairness related valuation을 종합하여 utility function을 제작하게 된다.
\[U_i=\alpha E_{y_i}+(1-\alpha)E_{z_i}\]Experiment
Dataset
Dataset으로 bank account-opening fraud dataset을 사용했다. 해당 데이터에서 fraud rate는 1%이다. 해당 데이터는 사기계좌를 찾는 것으로 True Positive Rate (TPR)이 높아야한다. 반면에 False Positive Rate (FPR)가 높으면 사용자의 계좌사용이 불편해지기 때문에 FPR을 낮추는 것을 목표로 하고 있다.
Model
Model은 tabular data에서 SOTA를 찍고있는 LightGBM을 사용한다.
Setup
Data sampling, re-weighting은 다음의 과정을 거친다.
- 각각의 예측모델 Y, Z에 대해 tranining instance의 value를 계산한다.
- 각각의 train instance에 대해 utility value를 계산한다.
- Utility value를 기반으로 Utility-aware prevalence sampling (UASP) 또는 Utility-aware reweighting (UAR) 수행한다. 이 때 UASP는 under sampling을 이야기하는 것이다.
Result
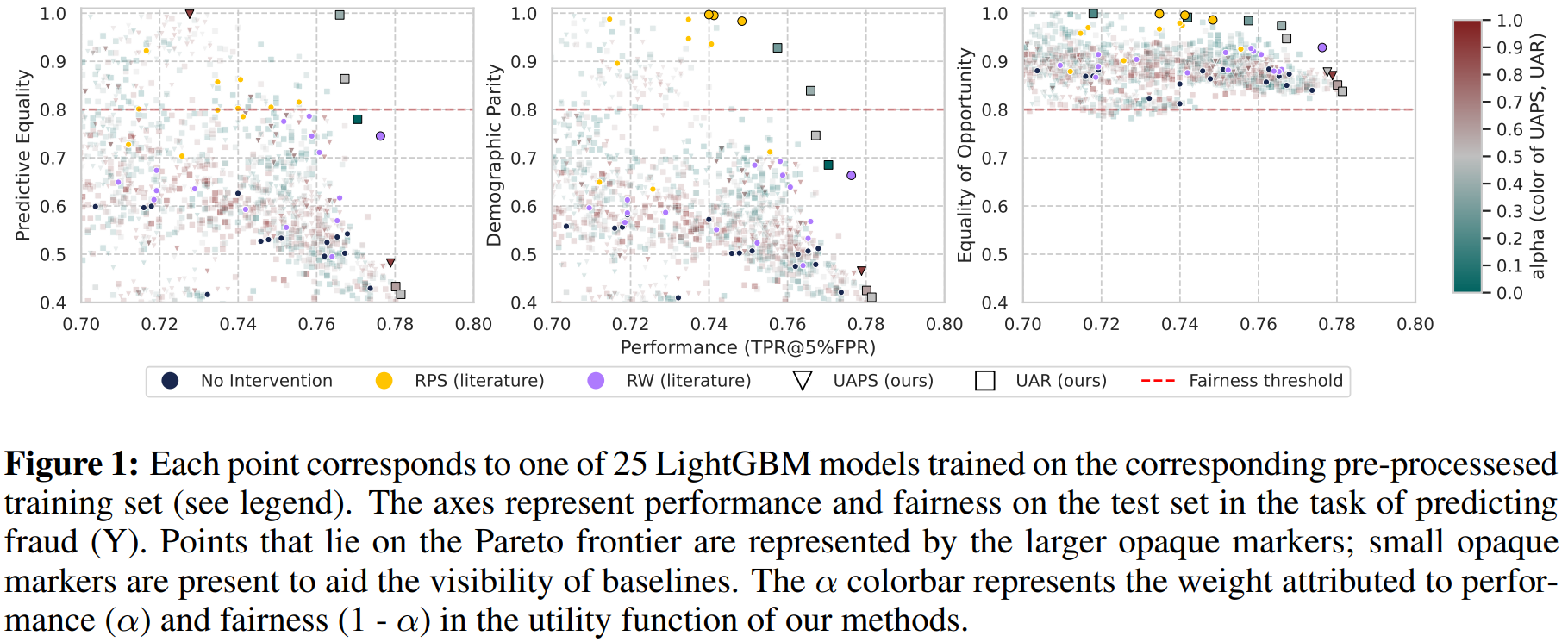
결과를 보면, UAPS(Utility-Aware Prevalence Sampling)와 UAR(Utility-Aware Reweighting)를 적용했을 때, baseline 대비 performance(TPR)와 fairness(FPR의 group 간 차이) 사이의 balance가 개선되었다.
핵심은 \(\alpha\) 값을 조절함으로써 performance와 fairness 사이의 trade-off를 사용자가 직접 제어할 수 있다는 점이다. \(\alpha = 1\)이면 순수 performance 기반, \(\alpha = 0\)이면 순수 fairness 기반이 되며, 중간값을 사용하면 두 목표를 적절히 균형 맞출 수 있다.
느낀점
이 논문의 contribution은 performance와 fairness를 하나의 utility function으로 통합했다는 것이다. 기존에는 두 목표를 별도로 최적화하거나, fairness constraint를 추가하는 방식이었는데, entropy 기반의 단일 scalar value로 만들어 sampling이나 re-weighting에 직접 활용할 수 있게 한 것이 실용적이다. 다만 fairness-related entropy의 이론적 근거가 다소 약하고, 실험도 하나의 데이터셋에서만 진행한 점은 한계로 보인다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: