MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Introduction
Transformer는 NLP에서 좋은 성능을 보였고 vision task에서도 ViT를 통하여 좋은 성능을 보여줬다. 이는 global representation을 학습할 수 있기 때문인데 이와같은 성질은 light weight제작시 단점이 된다. 기존의 CNN에서 light weight 제작은 인접픽셀끼리 높은 상관관계를 가지고 있다라는 inductive bias의 덕을 보았기 때문이다. 따라서 저자는 CNN과 ViT의 장점을 합쳐놓은 MobileViT를 제안하였고, light weight, general-purpose, low latency를 달성하였다.
MobileViT
ViT
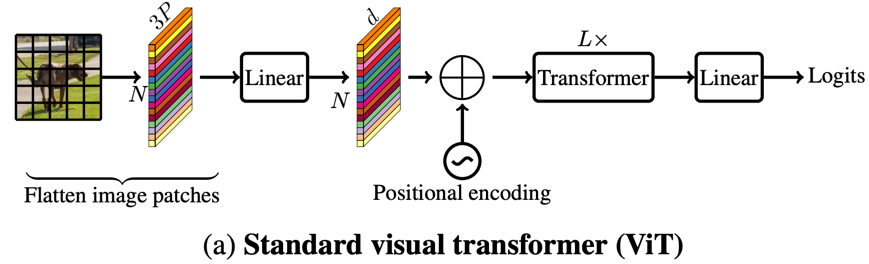
- Input \(X \in \mathbb{R}^{H \times W \times C}\)를 flatten patch \(X_f \in \mathbb{R}^{N \times PC}\)로 만든다.
- Fixed d-dimensional space \(X_p \in \mathbb{R}^{N \times d}\)에 projection 시킨다.
- L개의 transformer block을 이용하여 inner-patch representation을 학습한다.
ViT의 computational cost는 \(O(N^2d)\)이고, \(P=wh\)이다.
ViT는 spatial inductive bias를 무시하기 때문에 더 많은 파라미터를 요구한다.
MobileVit Architecture

MobileViT block은 위와 같다. MobileViT는 local global feature를 적은 파라미터를 학습하기 위해 구상되었다.
- (Local feature) Input tensor \(X \in \mathbb{R}^{H \times W \times C}\)을 standard \(n \times n\) convolution layer와 point wise convolution을 이용하여 \(X_L \in \mathbb{R}^{X \times W \times d}\) 를 만든다.
- \(X_L\)을 non-overlapping patch인 \(X_U \in \mathbb{R}^{P \times N \times d}\)로 unfold한다. 이 때 \(P=wh, N=\frac{HW}{P}\)이고, \(h \leq n, w \leq n\)이다.
- (Global feature) 패치 \(p \in \{1, ... ,P\}\)에 대하여 inter-patch relationship을 학습하기 위해 transformer를 사용한 후 \(X_G \in \mathbb{R}^{P \times N \times d}\)를 얻는다.
- 이후 point-wise convolution으로 차원을 \(C\)로 만들고 \(X\)와 concatenation 연산을 한다.
- 또 다른 \(n \times n\) convolution을 통하여 concatenation한 결과를 fusion한다.
위의 과정을 통해 local information을 \(X_U(p)\)에 encode하고, global information을 \(X_G(p)\)에 encode한다.

위의 그림에서 볼 수 있듯 convolution을 통해 local feature를 encode 한 후 transformer연산을 통해 inter-patch relationship을 encode하여 결과적으로 한 pixel이 다른 모든 pixel을 고려할 수 있게되었다.
Relationship to convolution
Standard convolution은 다음 3가지 연산의 스택으로 볼 수 있다.
- Unfolding
- Matrix multiplication
- Folding
이 때 MobileViT block은 matrix multiplication(local processing )에서 transformer(global processing)로 변경되었으므로 transformer as convolution으로 볼 수 있다.
Light-weight.
다른 ViT계열 모델들은 transformer만 사용하여 inter-patch relationship을 계산하여 image-specific inductive bias의 정보를 잃게되었다. 하지만 MobileViT block은 convolution-like한 특성을 가지고 있어 다른 모델보다 경량화가 가능한 것이다.
Computational cost
MobileViT \(O(N^2Pd)\), ViT는 \(O(N^2d)\)이다. MobileViT는 ViT보다 비효율적이지만 실제로는 DeIT보다 2배 더 적은 FLOPs와 1.8%의 성능향상이 되었다.
MobileViT architecture
light-weight CNN을 고려하여 S, XS, XXS 모델을 만들었고, 처음 layer는 3x3 standard convolution layer를 사용하고 다음은 MobileNetv2(MV2) block과 MobileViT block을 사용한다. MobileViT block에서는 3x3 CNN을 사용하였고 \(h=w=2\)를 사용하였다. MV2는 down-sampling의 역할을 수행한다.
MULTI-SCALE SAMPLER FOR TRAINING EFFICIENCY
일반적인 ViT모델들은 여러 스케일의 모델들을 만든 후 fine-tuning할수밖에 없다. 하지만 MobileViT는 multi-scale traning이 가능하고 이 때 GPU성능을 끌어올리기 위해 batch-size를 resoution마다 유동적이게 관리했다. Resolution set \(S={(H_1, W_1),...,(H_n, W_n)}\)에 대하여 최대 resolution이 \((H_t, W_t) \in S\)일 때, t번째 resolution \((H_t, W_t) \in S\)의 batch size는 \(b_t=\frac{H_nW_nb}{H_tW_t}\)이다.
EXPERIMENTAL RESULTS
IMAGE CLASSIFICATION ON THE IMAGENET-1K DATASET
- Nvidia GPU 8개
- epoch: 300
- batch size: 1024
- AdamW optimizer
- label smoothing cross-entropy (0.1)
- multi-scale sampler (\(S=\{(160,160),(192,192),(256,256),(288,288),(320,320)\}\))
- learning rate scheduler: warmup+cosine (0.0002 → 0.002 for 3k, anneal to 0.0002)
- L2 weight decay 0.01
- Random resized cropping and horizontal flipping
Comparison with CNNs

Comparison with ViTs.

ViT계열 모델들은 augmentation에 민감하다 따라서 basic과 advanced로 나누엇다.
MOBILE OBJECT DETECTION
MS-COCO에서 평가하였고 SSD에서 backbone만을 교체하여 실험하였다.

MOBILE SEMANTIC SEGMENTATION
DeepLabv3를 사용하였으며 데이터셋은 pascal voc 2012를 사용했다.

PERFORMANCE ON MOBILE DEVICES
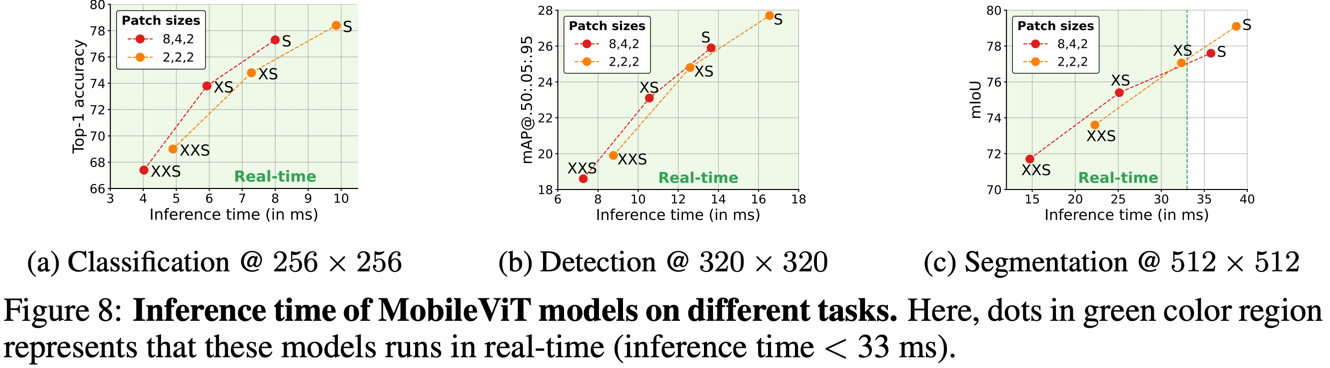
CorML을 사용하여 iPhone12에서 실험을 진행했을 때 patch size별로 실험을 했을 때 모든 모델들은 real-time에서 동작하였다.

하지만 mobilenet과 같은 CNN모델보다는 성능이 안좋았다.
저자는 이를 하드웨어 optimization이 지원되지 않아서라고 추측한다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: