MobileOne: An Improved One millisecond Mobile Backbone
Introduction
MobileNet, ShuffleNet등 경량화 네트워크들은 parameter의 수와 FLOPS를 기준으로 모델을 경량화하고 있다. MobileNetV3, MNasNet 등 만이 실제 기기에서 latency를 측정하여 반영하고 있다. 저자는 parameter 수와 FLOPS가 줄어들수록 latency가 줄어드는 관계가 항상 일치하지 않는다는 것을 발견하여 실제로 모델의 어떤 부분이 높은 복잡도를 갖는지 평가하여 모델을 제작했다.
Method
Metric Correlation
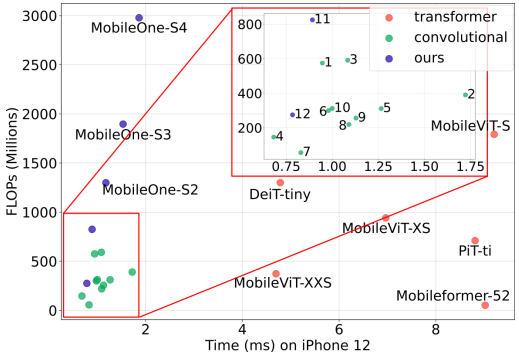
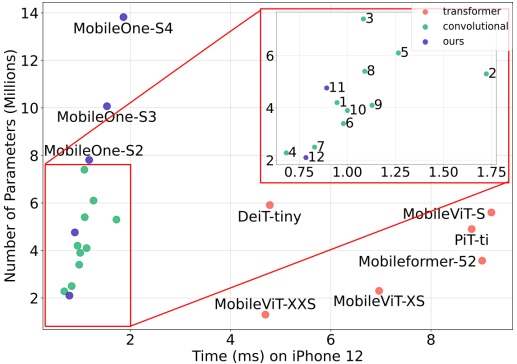
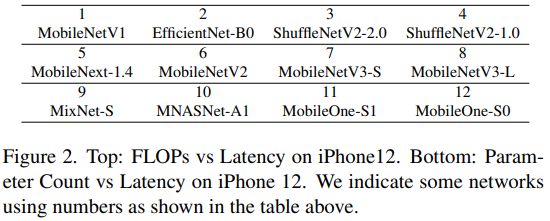
모델의 cost를 비교할 때 parameter의 수와 FLOPS를 기준으로 비교하곤한다. 하지만 실제 모바일환경에서 일치가 안될 경우고 있으므로 iPhone 12를 사용하여 상관관계를 측정했다.
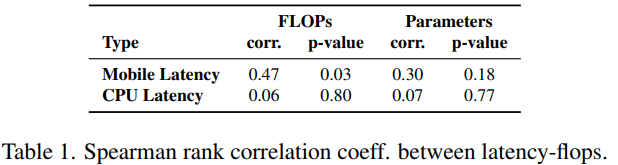
그 결과 모바일 환경에서는 FLOPS가 중간정도의 상관관계를 나타냈고 파라미터의 수는 낮은 상관관계를 나타냈다. 반면에 CPU 환경에서는 상관관계가 없어 보인다.
Key Bottlenecks
Activation Function
Activation function마다 cost가 다르다. 따라서 이를 비교하기 위해 30 layer의 모델을 선언하였으며 activation layer만 바꾸면서 속도측정을 했다.
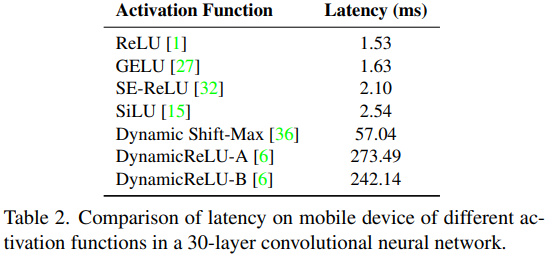
Dynamic Shift-Max등 여러 강력한 activation function이 있으나 이는 latency가 커서 RELU를 사용하기로 했다.
Architectural Blocks
Runtime performance에 영향을 주는 원인은 크게 memory access cost과 degree of parallelism이 있다. 예를 들면 skip connection은 이전 feature map에 대한 정보를 저장하고 읽어와야하기 때문에 memory access cost가 늘어나고 SE-block에서 사용하는 global pooling operation은 동기화를 해야하기 때문에 degree of parallelism이 줄어든다. 따라서 MobileOne에서는 skip connection을 제거하고 SE-block의 수는 적당히 조절하였다.
MobileOne Architecture
MobileOne Block
기본적인 block은 depthwise, pointwise layer로 factorization하였다. Basic block은 MobileNet-V1에서 사용하는 3x3 depthwise convolution과 1x1 pointwise convolution을 사용한다. 그리고 Rep-VGG에서 사용한 re-parameterizable skip connection을 사용한다. 이 때 trivial over-parameterization factor k는 1~5의 값을 사용한다. Memory access cost를 줄이기 위해 skip connection은 inference time에 제거했다.
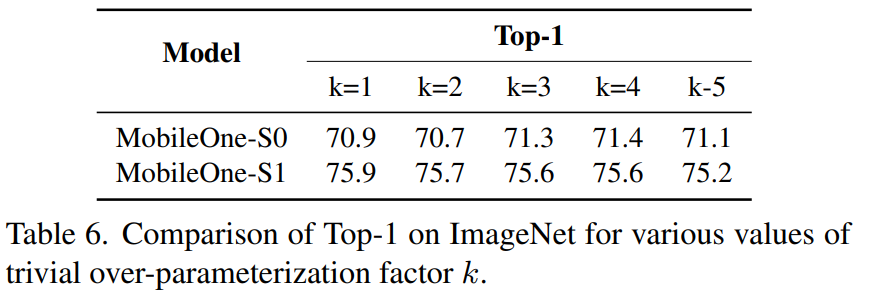
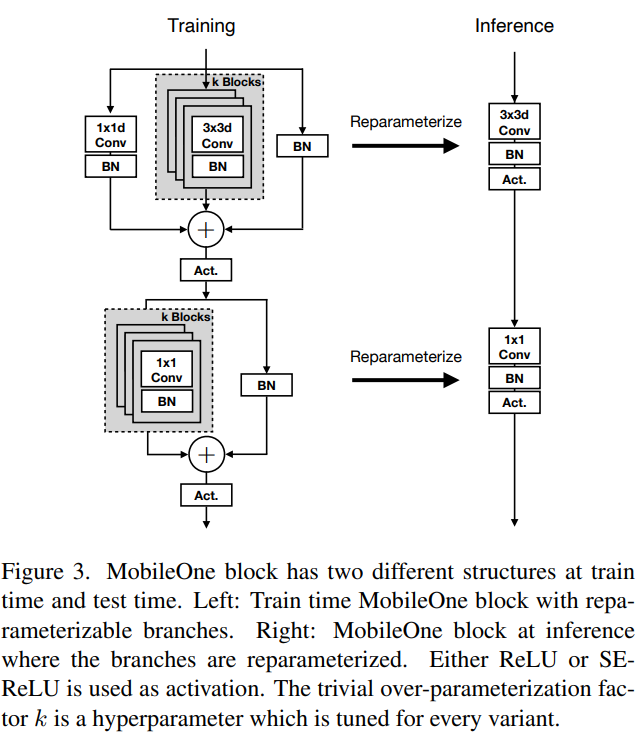
Convolution에 대해서는 BatchNorm을 Conv layer에 folding하였다. Kernel size \(K\), Input channel dimension \(C_{in}\), output channel dimension \(C_{out}\)에 대해서 weight matix는 \(W^\prime \in \mathbb{R}^{C_{out} \times C_{in} \times K \times K}\), bias는 \(b^\prime \in \mathbb{R}^D\)로 표시할 수 있다. 또한 BatchNorm은 accumulated mean \(\mu\), accumulated standard deviation \(\sigma\), scale \(\gamma\), bias \(\beta\)로 구성되어 있다. Conv와 BN은 모두 linear operation이므로 이를 다음과 같이 합칠 수 있다.
- Weight
- Bias
BN에 대한 skip connection은 1x1 convolutio에 K-1 zero padding으로 folding 할 수 있다. 위 과정을 통해 얻어진 folding은 inference time에 사용된다.
Model Scaling
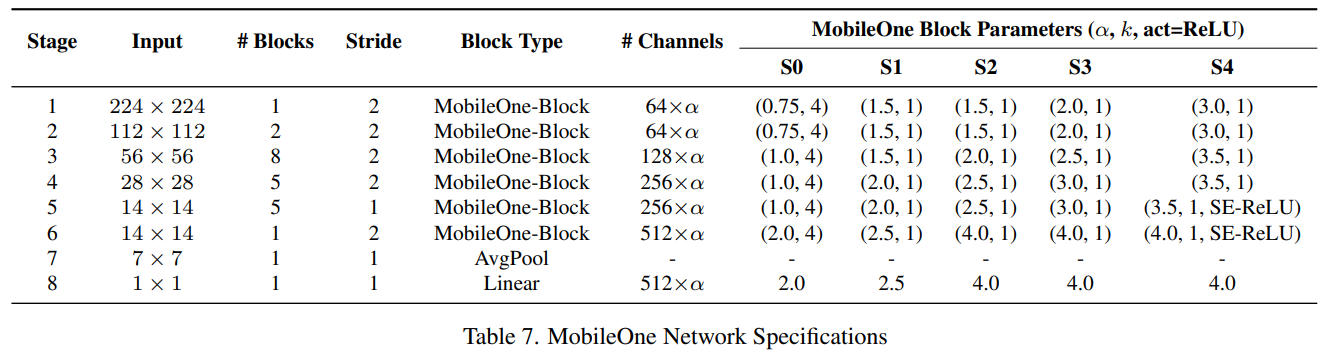
모델의 속도를 위해 block의 수는 resolution마다 다르게설정했다. 이는 resolution이 높은 상단 layer에서는 cost가 높기 때문에 block의 수를 줄이고 하단 layer는 channel 수가 많기 때문에 block를 줄이게 된 것이다.
Training
Overfitting을 방지하기 위해 small model에 대해서는 regularization을 적게 해야한다. 또한 cosine learning rate를 decay와 함께 regularization도 deacy를 해준다.
Result
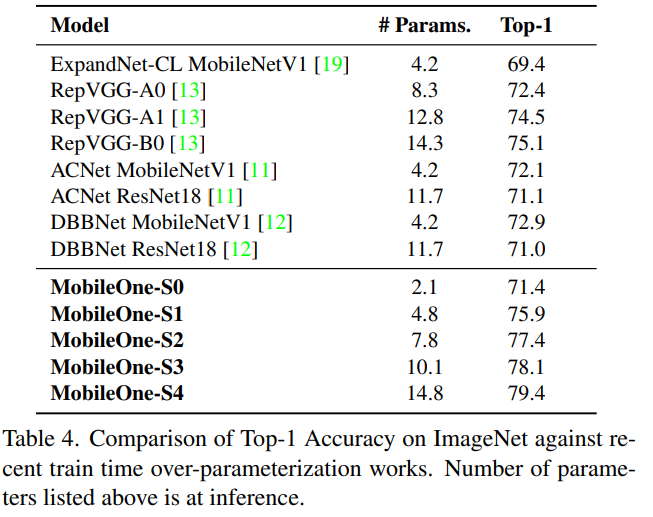
파라미터의 수가 비슷한 모델중에서는 성능이 제일 높게 나타난다.
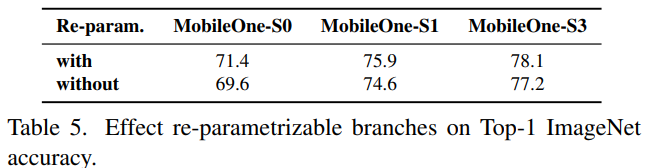
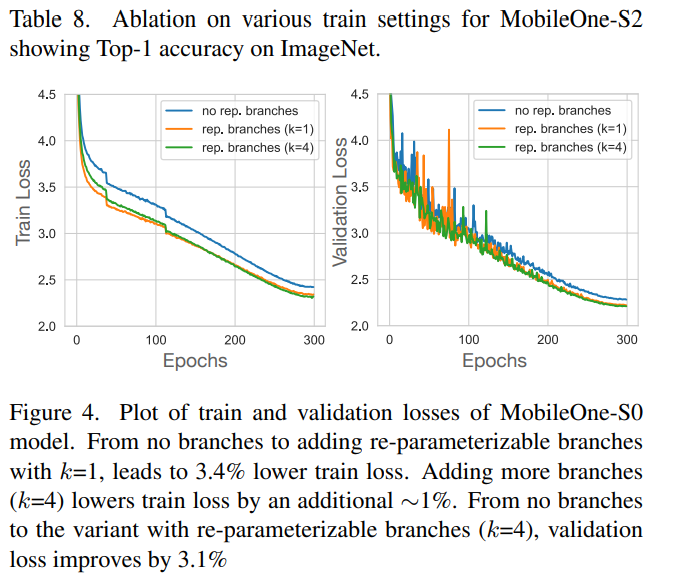
Reparameterization도 성능에 좋은 영향을 내는데 모델의 크기가 클수록 성능차이가 좁아진다.
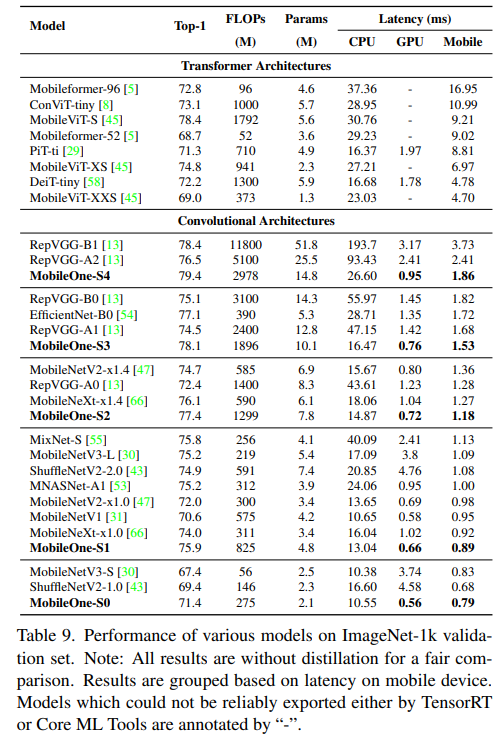
다른 모바일 네트워크를 CPU, GPU, Mobile에서 돌렸을 때 성능과 속도가 좋았고
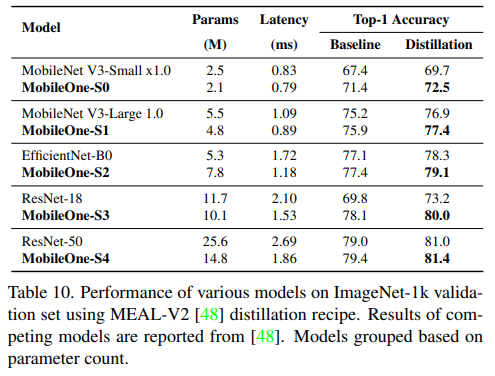
knowledge distillation을 했을 때도 성능이 제일 좋았다.
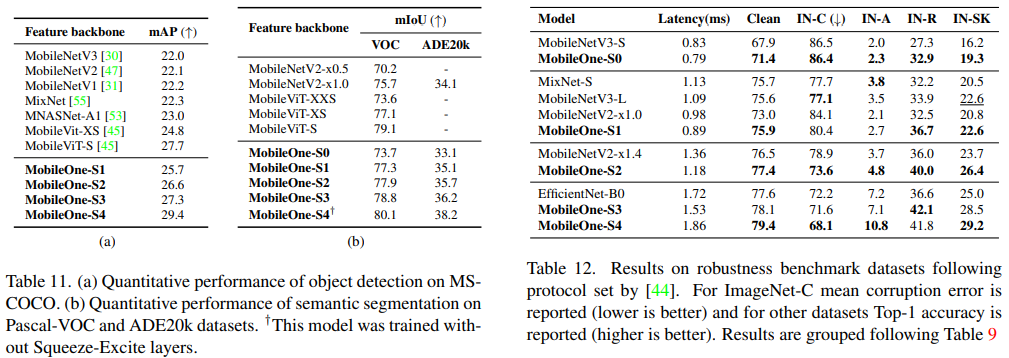
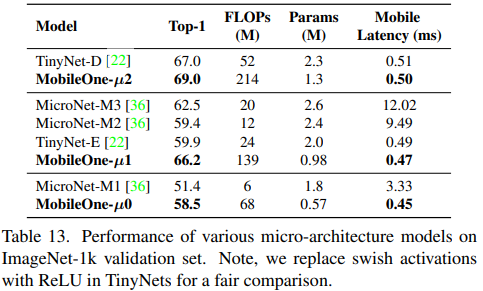
다른 Task에서도 성능이 좋았다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: