Rethinking “Batch” in BatchNorm
Introduction
BatchNorm은 layer의 중간에 들어가며 학습을 안정화하여 학습속도를 상승시키고 오버피팅을 방지한다. 하지만 train test domain이 많이 다르거나 batch size가 현저하게 작다면 batch norm은 문제를 일으키기도 한다. 따라서 이 논문에서는 BatchNorm의 함정을 정리하고 권장사항을 제시한다.
BatchNorm
BatchNorm은 다음과 같은 식으로 정의된다.
\[y=\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}\]보통 평균과 분산은 학습시 mini-batch를 통하여 모평균과 모분산을 추정한다.
\[\mu_{\mathcal{B}}=mean(X,axis=[N,H,W])\] \[\sigma_{\mathcal{B}}^2=var(X,axis=[N,H,W])\]기존의 BatchNorm은 흔히 모평균과 모분산을 예측하기 위해 EMA(Exponential Moving Average)를 사용한다.
\[\mu_{EMA} \leftarrow \lambda \mu_{EMA} + (1-\lambda) \mu_{\mathcal{B}}\] \[\sigma_{EMA}^2 \leftarrow \lambda \sigma_{EMA}^2 + (1-\lambda) \sigma_{\mathcal{B}}^2\]하지만 EMA는 이전에 사용한 값을 대부분 가져가 실제 평균, 분산을 늦게 반영한다. (\(\lambda\)는 보통 0.9로 설정한다.)
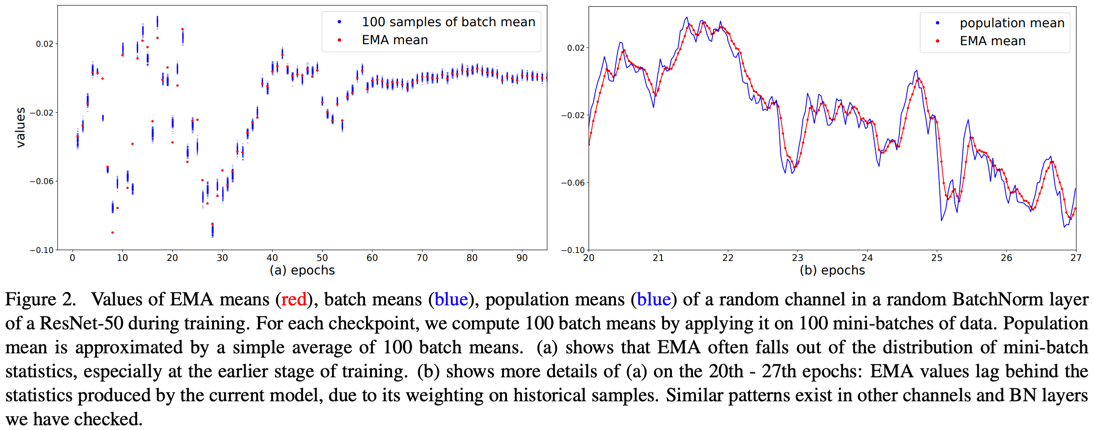
PreciseBN
따라서 저자는 PreciseBN을 제안했다. PreciseBN은 mini-batch마다 batch parameter를 update하지 않고 한 epoch이 끝나면 model을 freeze한 후 batch statistics를 aggregation을 하여 update한다.
\[\mu_{pop}=E[\mu_{\mathcal{B}}], \sigma_{pop}^2=E[\mu_{\mathcal{B}}^2+\sigma_M^2]-E[\mu_{\mathcal{B}}^2]\]EMA vs PreciseBN
Large Batch Size
PreciseBN은 EMA보다 안정적이다. 저자는 먼저 batch size가 매우 클 경우에 대하여 실험했다. EMA에서 batch size가 커지면 절대적인 update수가 적어져 validation error의 분산이 커진다. 하지만 PreciseBN은 한 epoch이후에 update하기 때문에 분산이 커지는 일이 없었고 실험적으로 1k~10k의 sample을 aggregation을 하면 모수를 추정하기 충분했다.

Small Batch Size
EMA는 mini-batch만 볼 수 있기때문에 batch size가 작을수록 성능하락이 커 PreciseBN의 성능이 높았다. 하지만 실험적으로는 EMA는 모델이 충분히 학습하여 수렴했을 때와 Batch size가 충분히 큰 경우 Precise BN과 성능차이가 별로 없었다.

EMA는 Batchsize가 작아질수록 train-test inconsisitency가 커진다. 따라서 inference에 mini-batch statistic을 이용하면 성능하락이 줄어든다.
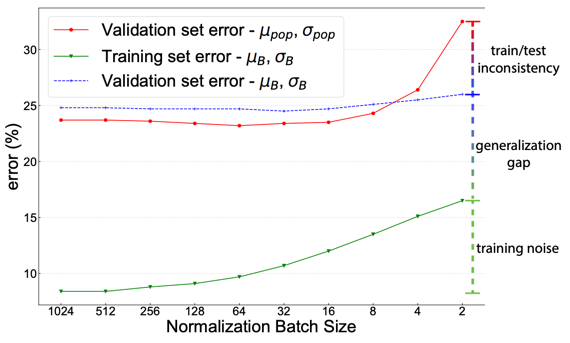
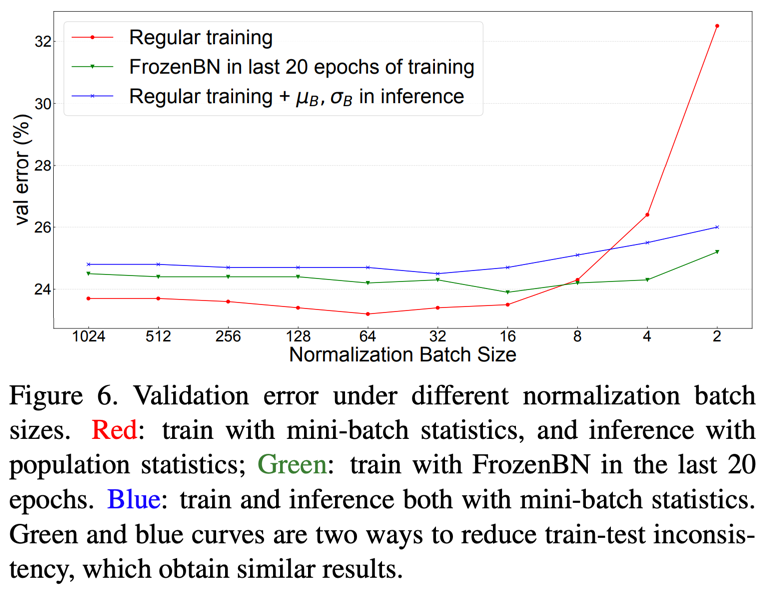
FrozenBN
Finetuning할 때 batch norm을 freeze한다. 하지만 일반적인 training에서도 효과를 보는 것을 찾아냈다. 이 때 학습 epoch에서 중간쯤부터 batchnorm을 freeze하면 된다. ImageNet실험에서는 마지막 20 epoch때 frozenBN을 사용하여 train-test-inconsistency를 개선했다.
Adaptive BatchNorm
Train test에서 큰 domain inconsistency가 존재한다. 따라서 Test set에서 batch norm의 population statistics를 학습 후 평가했을 때 정확도가 상승했다. 이 때 train과 evalutation의 augmentation 방법이 동일해야한다.
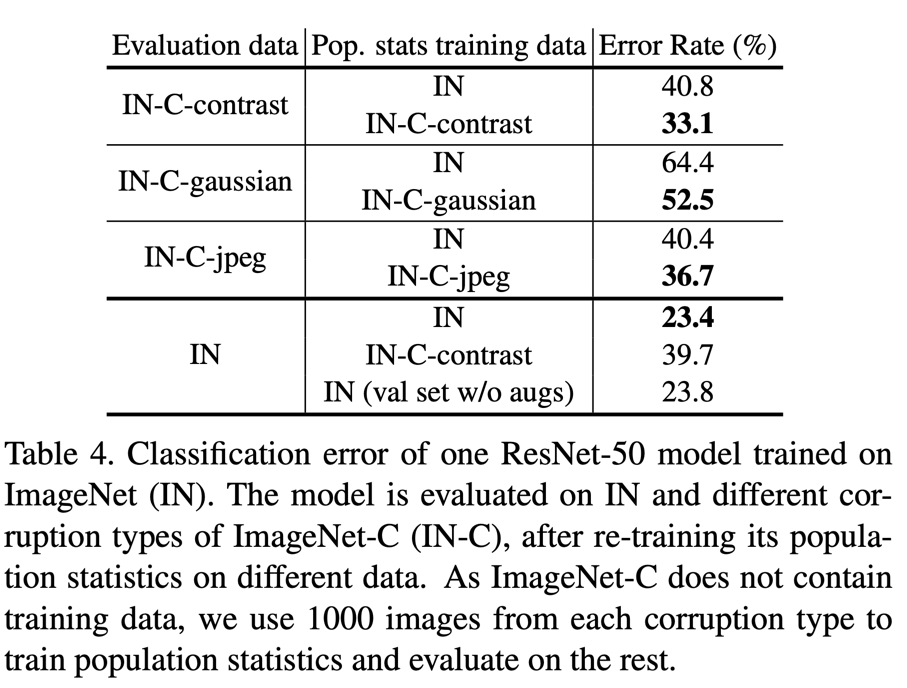
BatchNorm in multi-domain training
multi-domain에서 다음의 식이 성립한다.
\[f([X_1, X_2,...,X_n]) \neq [f(X_1, f(X_2), ..., f(X_n)]\]즉, domain 별로 normalize하는 것과 domain을 합쳐 normalize하는 것과 다르다. 이것이 문제를 일으킨다.
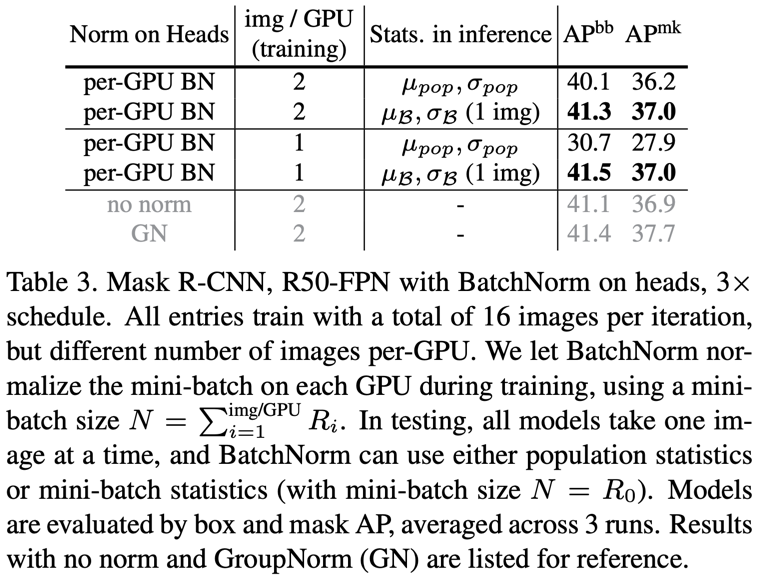
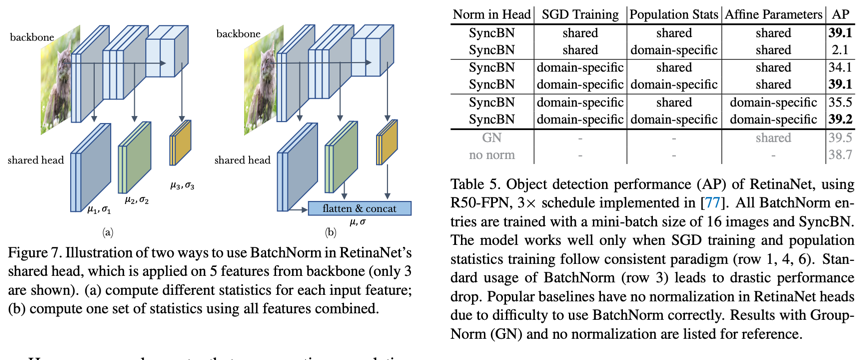
저자는 이를 retinanet에 실험을 했다. Retinanet은 size가 다른 featuremap을 공유된 head로 detection을 진행한다. 하지만 각각의 feature map은 다른 domain을 볼 수 있다. 따라서 각각의 featuremap을 normalization하는 것이 아닌 합쳐서 normalization을 하면 성능이 높아진다. 이때 training과 population statistics과 affine parameter의 환경을 일치하는 것이 중요하다.
Ghost BatchNorm, LayerNorm
Training하다보면 mini-batch안에 같은 class의 image가 들어가는 경우가 있다. 이럴때 모델은 mini-bath에서 class의 hint를 얻을 수 있기 때문에 mini-batch간 dependency가 존재할 수 있고 이는 bias를 유발한다. 따라서 minibatch에서 서로 다른 class 끼리 normalizaion을 진행하면 성능이 올라간다.

Enjoy Reading This Article?
Here are some more articles you might like to read next: