Simple Baselines for Image Restoration
Introduction
Image restoration에서 SOTA Network들은 많은 모듈을 추가하여 complexity가 증가하였다. 저자는 이를 inter-block complexity, intra-block complexity로 나누어 생각했고, low inter-block complexity와 low intra-block complexity로 SOTA를 달성하기 위해 여러 실험을 진행하였다.
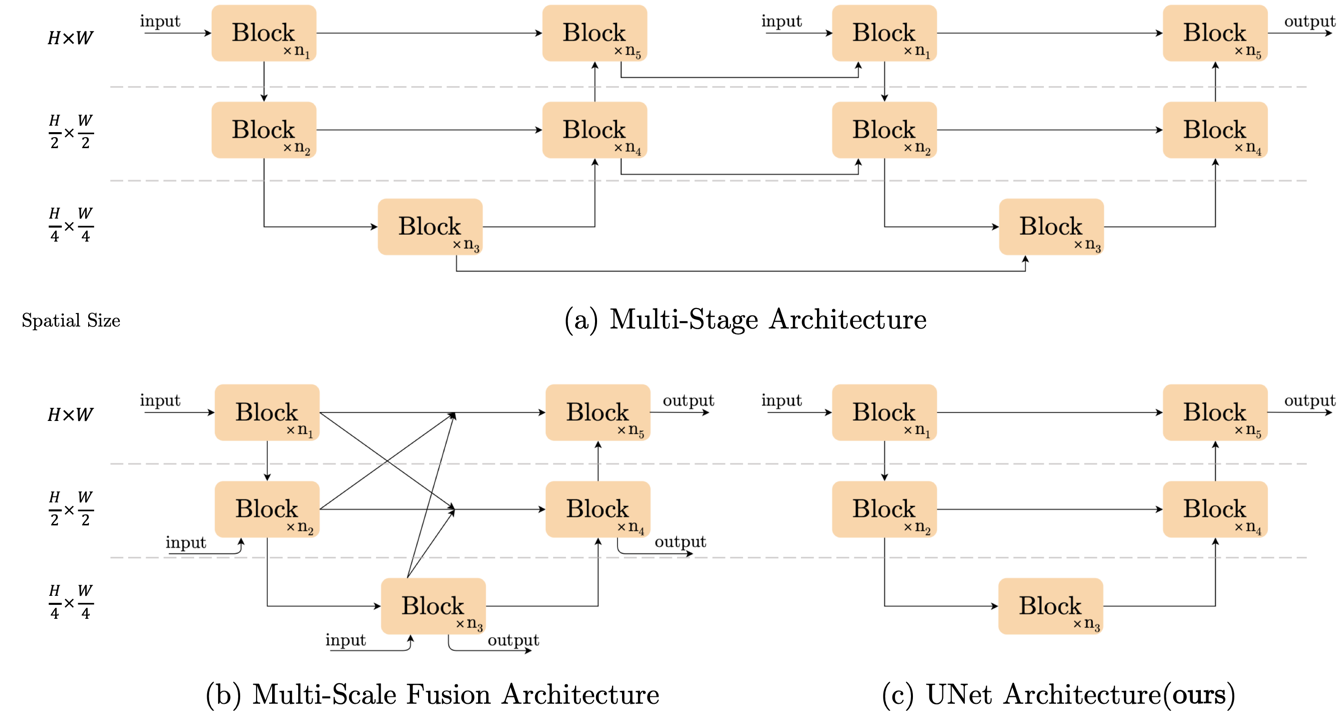
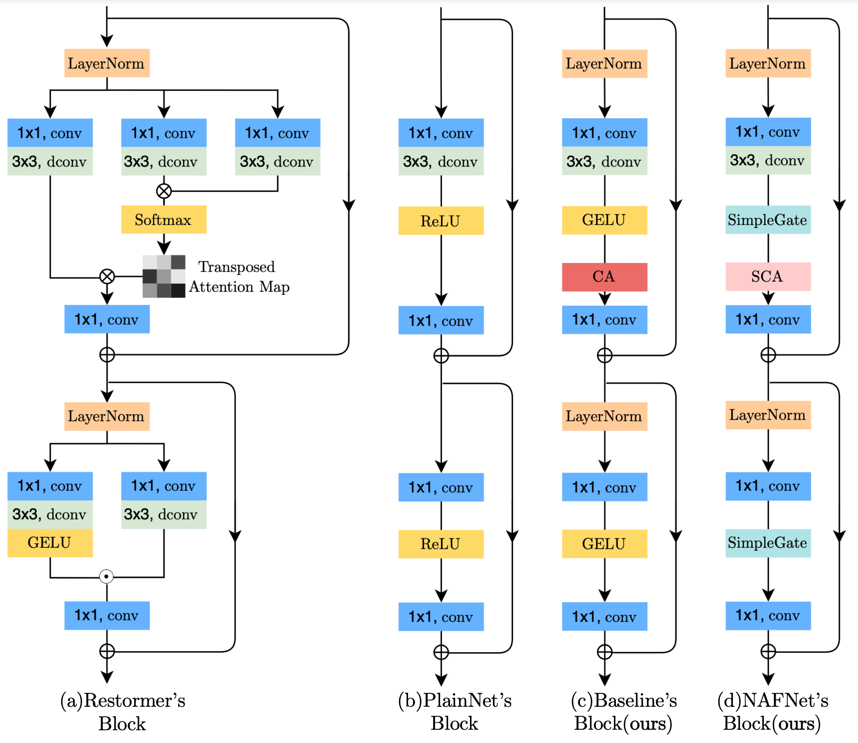
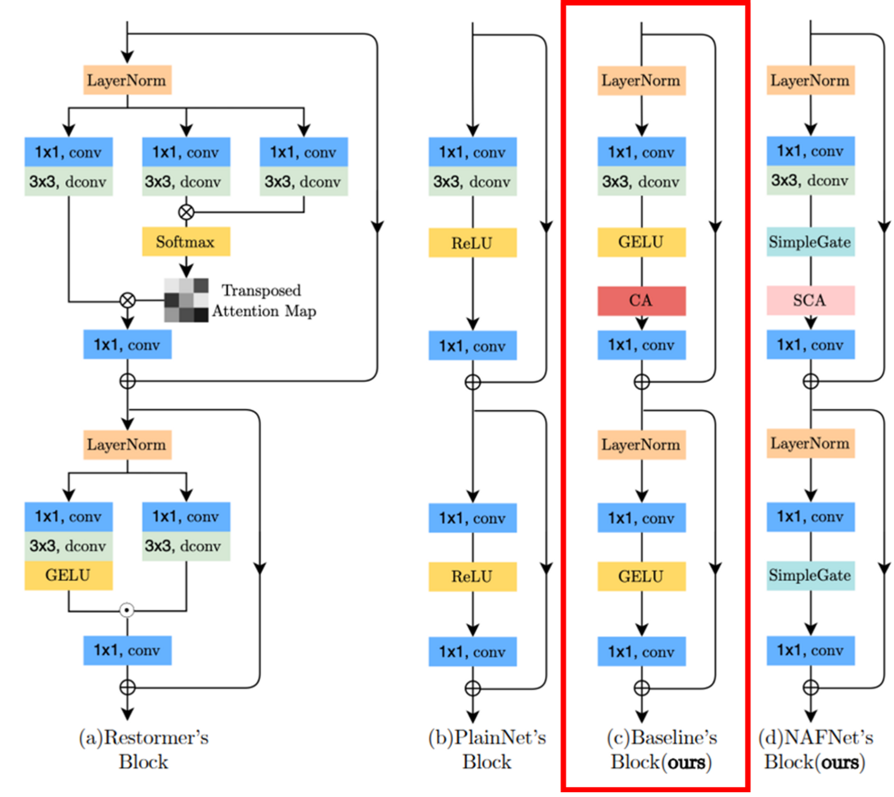
기본적으로 UNet구조를 따랐고, convolution-relu-shortcut으로 구성된 간단한 plain block으로 시작하였다. 이후 plain block에서 SOTA method 중 필수적이라고 생각하는 것 만을 하나씩 추가하였고 결과적으로 GELU, Channel Attention을 추가하였다. 이후 더 발전사항으로 GELU를 GLU로 대체하고 Channel Attention을 GLU형태로 변환해 SC(Simple Channel Attention)로 변경하였다.
Simple Baseline
여러 아이디어를 평가하였는데 채택된 아이디어는 bold체에 밑줄로 표현하겠다.
Internal architecture
- Block
- PlainNet: Conv, ReLU, Shortcut
- Transformer 사용 X
- SOTA를 달성하는데 필수요소 X
- Depth-wise convolution이 더 간단한 표현
- BatchNorm
- BatchNorm: small batch size에 취약
- InstanceNorm: manual한 tuning이 필요
- LayerNorm: 다수의 SOTA에서 사용, 성능 향상과 학습 안정성에 기여
- learning rate 10배 증가 가능
- +0.44dB on SSID, +3.39dB on GoPro
- Activation
- ReLU: 좋지만 SOTA에서 미미한 사용
- GELU: SOTA에서 많이 사용
- SSID에서 차이 X, +0.21dB on GoPro
결과
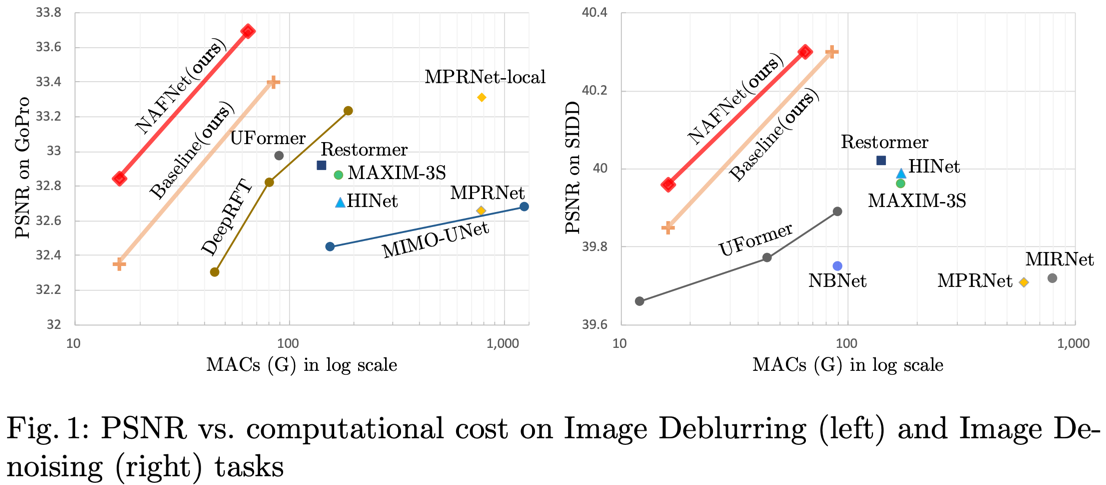
Baseline만으로 SOTA 달성하였다.
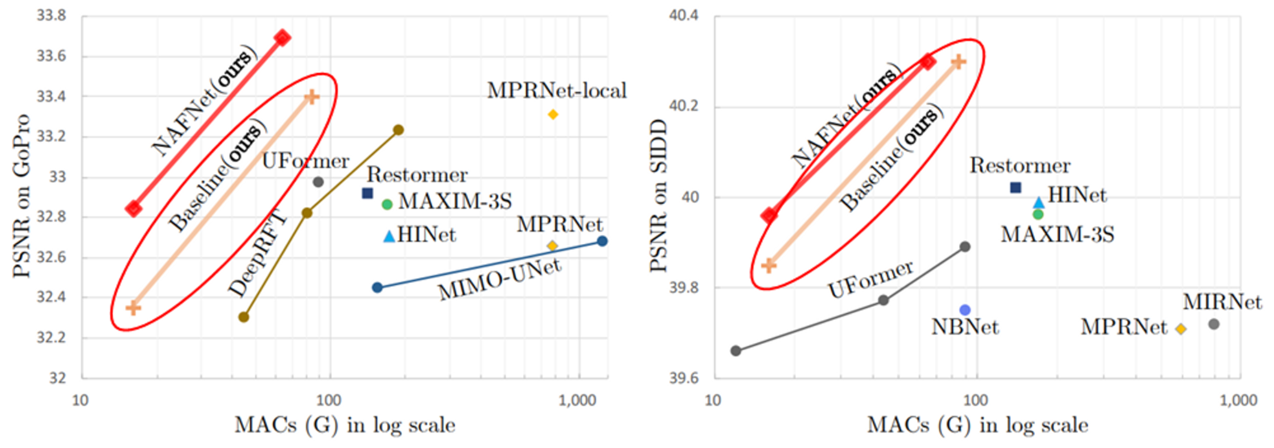 \
\
NAFNet
저자는 baseline network의 GELU와 channel attention의 개선점을 찾아 적용했다.
GELU
GELU는 많은 SOTA network에서 사용하며 수식은 다음과 같다.
\[GELU(x)=x\phi(x)\]이때 \(\phi\)는 cumulative distribution function of the standard normal distribution으로 다음과 같이 근사화시킬 수 있다.
\[GELU \approx 0.5x(1+tanh[\sqrt{2/\pi}(x+0.044715x^3)])\]GLU (Gate Linear Unit)
SOTA network에서 GLU를 사용한다. 따라서 저자는 이 함수가 baseline의 성능을 향상시킬 수 있다고 생각했다.
\[Gate({X},f,g,\sigma)=f({X}) \odot \sigma(g({X}))\]이는 GELU의 generalization한 format이었고 따라서 GELU를 GLU로 대체하였다. 이 때 \(\odot\)은 element-wise product이다.
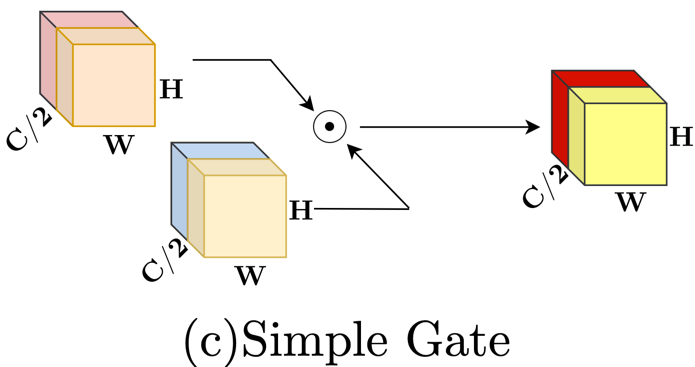
SimpleGate
GELU에서 element-wise product으로 인해 non-linearity가 발생한다. 따라서 sigmoid를 제거할 수 있다고 생각하였고 다음과 같은 simple gate function을 완성시킨다.
\[SimpleGate({X},{Y})=X \odot Y\]간단히 말하자면 channel을 반으로 쪼개어 element-wise product를 하였다.
Channel Attention
Channel attention의 수식은 다음과 같다.
\[CA({X})={X}*\sigma(W_2max(0, W_1pool({X})))\]global average pooling을 이용하여 global한 feature를 aggretation하고 channel들간 상관관계를 계산하기 위해 linear layer를 추가한다. 이 때 CA는 channel-attention calculation을 하나의 함수 \(\psi\)로 간주하여 다음과 같이 재정의할 수 있다. 밑의 식에서 \(*\)는 channel-wise product이다.
\[CA({X})={X}*\psi({X})\]이는 이전에 살펴본 GLU와 format이 유사하여 global informaion aggregation, channel information interaction을 남겨 다음과 같이 SCA(Simple Channel Attention)으로 재정의하였다.
\[SCA({X})={X}*Wpool({W})\] 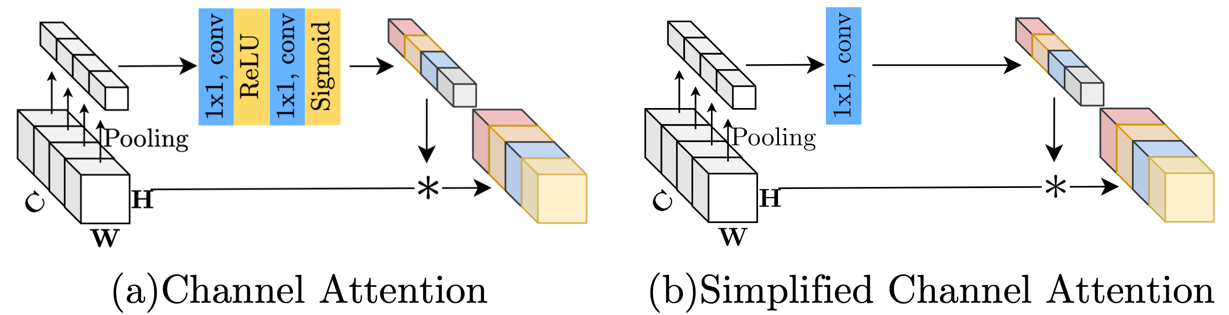
NAFNet
결과적으로 만들어진 NAFNet의 block은 다음과 같다.
전체적인 아키텍쳐는 앞서 언급했듯 UNet을 따른다.
Experiment
- 16GMACs computational budet
- gradient clip
- PSNR loss
- Adap optimizer \(\beta_1=0.9, \beta_2=0.9\) weight decay = 0
- Total iteration 200K
- Cosine scheduler: initail learning rate: 1e-3, final learning rate: 1e-6
- image size: 256x256
- batch size: 32
- TLC 사용 (Improving image restoration by revisiting global information aggregation. arXiv preprint arXiv:2112.04491 (2021))

LayerNorm을 추가하면서 learning rate를 높일 수 있게되었고, GELU, CA로 성능이 높아졌다.
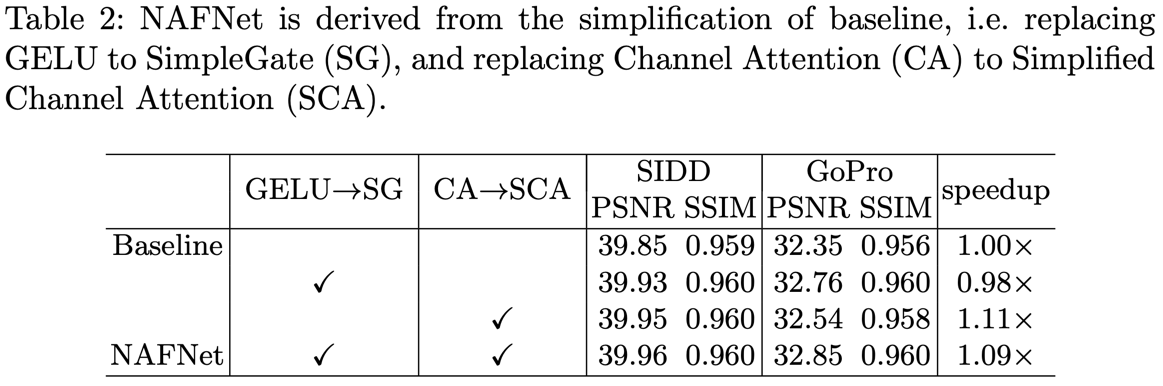
GELU와 CA를 각각 SG, SCA로 바꾸었을 때 속도 약간 느려졌지만 성능이 좋아졌다.
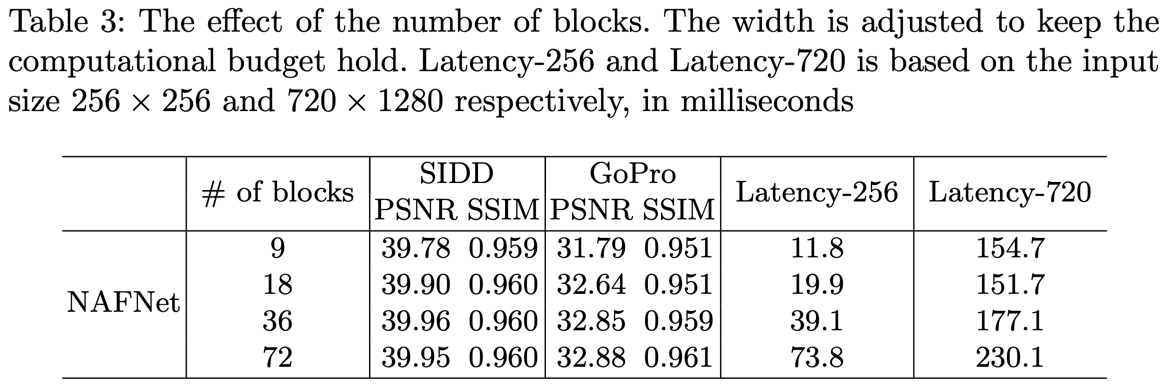
block수는 36개까지 성능향상이 컸는데 72개부터는 성능향상보다 complexity가 더 커서 36으로 결정하였다.
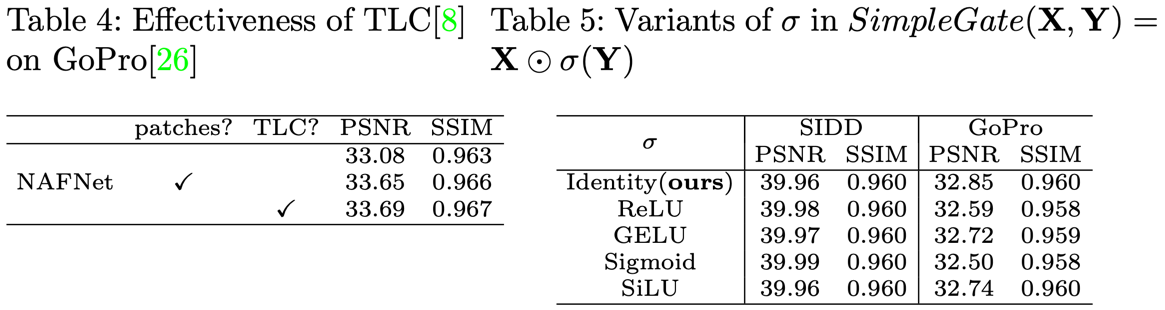
TLC는 긍정적이었고 SG에서 non-linear function의 영향을 비교했지만 미미하여 Identity를 사용하였다.
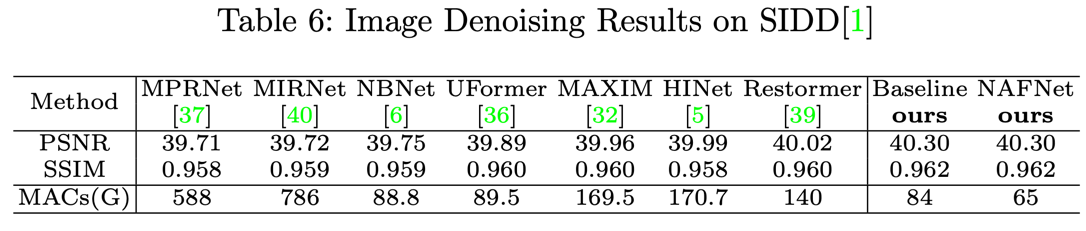

Denosing과 Deblur 모두 SOTA를 달성하였다.
이미지비교

Enjoy Reading This Article?
Here are some more articles you might like to read next: