META-REWARDING LANGUAGE MODELS: Self-Improving Alignment with LLM-as-a-Meta-Judge 설명
Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge
Introduction
InstructGPT의 성공 이후, LLM의 instruction following 능력은 매우 중요한 요소로 자리 잡았다. 이를 개선하기 위해 SFT, preference optimization(RLHF, DPO, PPO, KPO 등)과 같은 방법들이 사용되었으나, 이러한 방식들은 사람이 만든 preference 데이터가 필요하다는 한계가 있다. 고품질의 preference 데이터를 만드는 것은 비용이 크고 확장이 어렵다.
Self-Reward: 사람 없이 스스로 개선하기
이를 해결하기 위해 Self-Reward 방법론이 제시되었다. 이 접근법에서는 하나의 LLM이 두 가지 역할을 동시에 수행한다.
- Actor: 주어진 instruction에 대한 response를 생성한다.
- Judge: LLM-as-a-Judge 프롬프트를 통해 Actor가 생성한 response를 평가하여 preference pair를 만든다.
이렇게 만든 preference pair로 DPO 등의 방법으로 자기 자신을 학습시키면, 사람의 개입 없이 반복적으로 성능을 향상시킬 수 있다.
문제: Judge는 개선되지 않는다
하지만 기존 Self-Reward에는 근본적인 한계가 있다. Actor의 response 품질을 높이는 데만 초점이 맞춰져 있어, Judge의 평가 능력 자체는 개선되지 않는다. Judge가 정확하지 않으면 잘못된 preference pair가 생성되고, 이로 인해 Actor의 학습도 왜곡된다.
해결책: LLM-as-a-Meta-Judge
저자는 Meta-Judge라는 세 번째 역할을 추가하여 이 문제를 해결한다. Meta-Judge는 여러 Judge의 평가를 비교하여 어떤 Judge가 더 좋은 평가를 했는지 판단한다. 이를 통해 Judge의 성능도 함께 개선된다.
| 역할 | 기능 | 학습 대상 |
|---|---|---|
| Actor | Instruction → Response 생성 | Actor preference pair로 학습 |
| Judge | Response → Score 평가 | Judge preference pair로 학습 (기존에 없던 것) |
| Meta-Judge | Judge 평가 → 어떤 Judge가 더 나은지 판단 | (추가 학습 없음, Judge 학습 데이터 생성용) |
핵심 insight: 하나의 LLM이 세 가지 역할을 모두 수행한다. 별도의 모델이나 사람의 개입 없이, 자기 자신이 만든 데이터로 자기 자신을 개선한다.
Meta-Rewarding 프레임워크
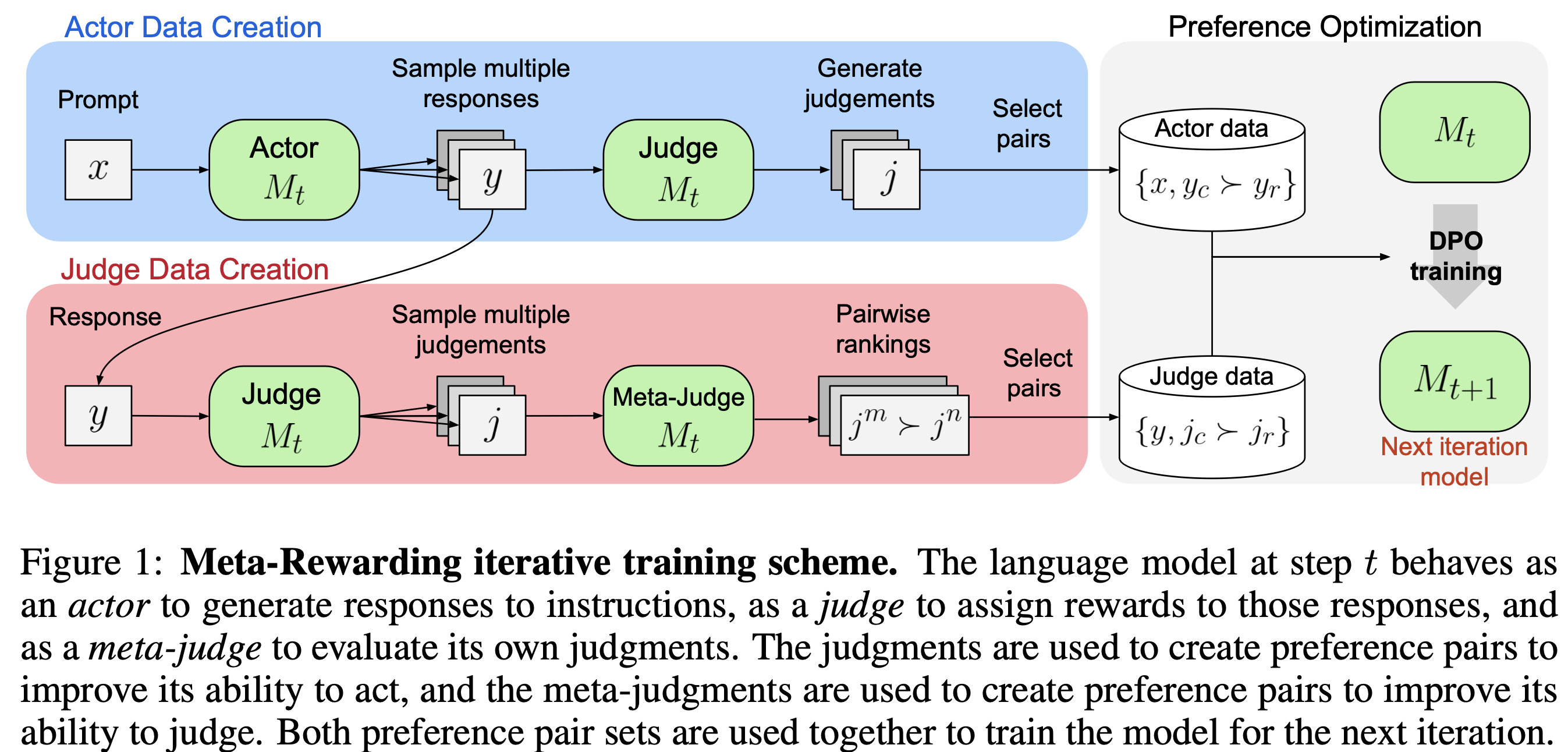
Meta-Rewarding은 각 iteration에서 두 종류의 preference pair를 생성한다.
- Actor Preference Pair: “어떤 response가 더 좋은가” → Actor 능력 개선
- Judge Preference Pair: “어떤 judge가 더 정확한가” → Judge 능력 개선
Actor Preference Dataset Creation
Step 1: Response 샘플링
Iteration \(t\)에서 현재 모델 \(M_t\)를 사용하여 하나의 instruction에 대해 \(K\)개의 response를 생성한다.
\[\{y_1, y_2, \ldots, y_K\}\]Step 2: Multiple Judgements 집계
각 response \(y_k\)에 대해 \(N\)번의 독립적인 Judge 평가를 수행한다. 각 평가는 5점 척도의 점수와 그 이유(rationale)를 포함한다.
\[\{j_k^1, j_k^2, \ldots, j_k^N\}\]\(N\)번의 평가 점수를 평균내어 각 response의 최종 점수 \(S_k\)를 구한다. 여러 번 평가하는 이유는 LLM의 평가가 stochastic하기 때문에, 한 번의 평가로는 신뢰성이 부족하기 때문이다. Parsing이 불가능한 평가 결과는 제외한다.
Step 3: Preference Pair 선택 + Length Control
최고 점수 \(S_{\max}\)의 response \(y_c\) (chosen)와 최저 점수 \(S_{\min}\)의 response \(y_r\) (rejected)를 선택한다.
이때 중요한 것이 Length Control이다. LLM은 긴 response를 선호하는 경향(verbosity bias)이 있어, 단순히 점수만으로 선택하면 모델이 점점 긴 답변을 생성하게 된다. 이를 방지하기 위해:
- \(y_c\)가 \(y_r\)보다 길면, 같은 길이 이하의 다른 high-score response로 대체한다
- 점수 차이가 너무 작으면(비슷한 quality) 해당 pair를 제외한다
Judge Preference Dataset Creation
Judge를 개선하기 위한 preference pair를 만드는 것이 이 논문의 핵심 기여이다.
Step 1: 어려운 데이터 우선 선택
모든 데이터에 대해 Judge preference를 만드는 것은 비효율적이다. 대신 Judge confidence가 낮은 데이터를 우선 선택한다. 구체적으로, \(N\)번의 Judge 평가 점수의 분산(variance)이 가장 높은 instruction-response pair를 선택한다. 분산이 높다는 것은 Judge가 “확신하지 못한다”는 뜻이므로, 이런 데이터에서 Judge를 개선하는 것이 가장 효과적이다.
Step 2: Pairwise Meta-Judge Evaluation
선택된 데이터의 \(N\)개 judgement에서 두 개를 골라 pair \((j^m, j^n)\)을 구성한다. Meta-Judge 프롬프트를 사용하여 “어떤 judge가 더 정확한 평가를 했는가”를 판단한다.
Position bias 해결: LLM은 첫 번째에 나온 것을 선호하는 경향이 있다. 이를 해결하기 위해 두 judge의 순서를 바꿔서 두 번 평가한다.
- 1차: \((j^m, j^n)\) 순서로 Meta-Judge에게 질의
- 2차: \((j^n, j^m)\) 순서로 Meta-Judge에게 질의
두 번의 결과가 일치하면 accept, 불일치하면 reject한다. 이렇게 하면 position bias가 상쇄된다.
Position별 가중치는 전체 데이터에서의 position bias를 반영한다.
\[\omega_1 = \frac{\text{win}_{\text{2nd}}}{\text{win}_{\text{1st}} + \text{win}_{\text{2nd}}}, \quad \omega_2 = \frac{\text{win}_{\text{1st}}}{\text{win}_{\text{1st}} + \text{win}_{\text{2nd}}}\]이를 이용해 각 pair의 battle result를 계산한다.
\[r_{mn} = \begin{cases} 1 & \text{meta-judge가 } j_m\text{을 선호} \\ -1 & \text{meta-judge가 } j_n\text{을 선호} \\ 0 & \text{무승부 또는 parsing 실패} \end{cases}\] \[B_{mn} = \omega_1 \cdot \mathbb{1}[r^{mn} = 1] + \omega_2 \cdot \mathbb{1}[r^{nm} = -1]\]Step 3: Elo Score로 Judge 랭킹
모든 pairwise battle 결과를 종합하여 각 judge의 Elo score를 계산한다. Elo score가 가장 높은 judge를 chosen, 가장 낮은 judge를 rejected로 선택하여 Judge Preference Pair를 구성한다.
Elo score를 사용하는 이유: 단순한 win rate보다 상대적 강도를 더 정확히 반영한다. 강한 상대를 이긴 것이 약한 상대를 이긴 것보다 가치 있다.
학습: DPO로 Actor와 Judge 동시 개선
Actor preference pair와 Judge preference pair를 합쳐서 DPO(Direct Preference Optimization)로 모델을 학습한다. 한 번의 학습으로 Actor와 Judge 능력이 동시에 개선된다.
Experiments
실험 설정
Llama-3-8B-Instruct를 base 모델로 사용한다. Iteration별 학습 구성:
| Iteration | Actor Pair | Judge Pair | 설명 |
|---|---|---|---|
| Iter 1 | \(M_0\) → \(M_1\) | ✅ 포함 | SFT 모델에서 시작, DPO로 Actor+Judge 학습 |
| Iter 2 | \(M_1\) → \(M_2\) | ✅ 포함 | Iter 1 모델 기반으로 다시 Actor+Judge 학습 |
| Iter 3 | \(M_2\) → \(M_3\) | ❌ 미포함 | Actor pair만 학습 (Judge 개선 효과 확인용) |
| Iter 4 | \(M_3\) → \(M_4\) | ❌ 미포함 | Actor pair만 학습 |
Iter 1-2에서 Judge pair를 포함하고, Iter 3-4에서 제외하여 Judge 학습의 효과를 분리하여 측정한다.
Instruction Following Evaluation
Meta-Rewarding은 win rate를 크게 향상시킨다

AlpacaEval 2.0에서 GPT-4 대비 win rate를 측정한 결과, iteration이 진행될수록 성능이 지속적으로 향상된다. 특히 Length-Controlled(LC) win rate에서 두드러진다. LC win rate는 response 길이에 의한 bias를 보정한 지표로, 순수한 response quality를 측정한다.
Meta-Judge와 Length Control이 핵심이다

Table 1에서 주목할 점:
- Self-Reward (Judge pair 없음): iteration이 진행되어도 LC win rate 향상이 미미하다
- Meta-Rewarding (Judge pair 포함): LC win rate가 꾸준히 향상된다
- Length Control 없음: raw win rate는 올라가지만, response 길이도 같이 늘어난다. LC win rate는 오히려 하락할 수 있다
이는 Judge 능력을 개선하는 것과 길이 편향을 통제하는 것이 둘 다 필수적임을 보여준다.
거의 모든 instruction 카테고리에서 성능 향상

카테고리별 분석에서 Meta-Rewarding은 coding, reasoning, math, writing 등 거의 모든 카테고리에서 baseline 대비 성능이 향상된다. 특히 복잡한 reasoning 태스크에서의 향상이 두드러진다.
복잡하고 어려운 질문에서도 효과적
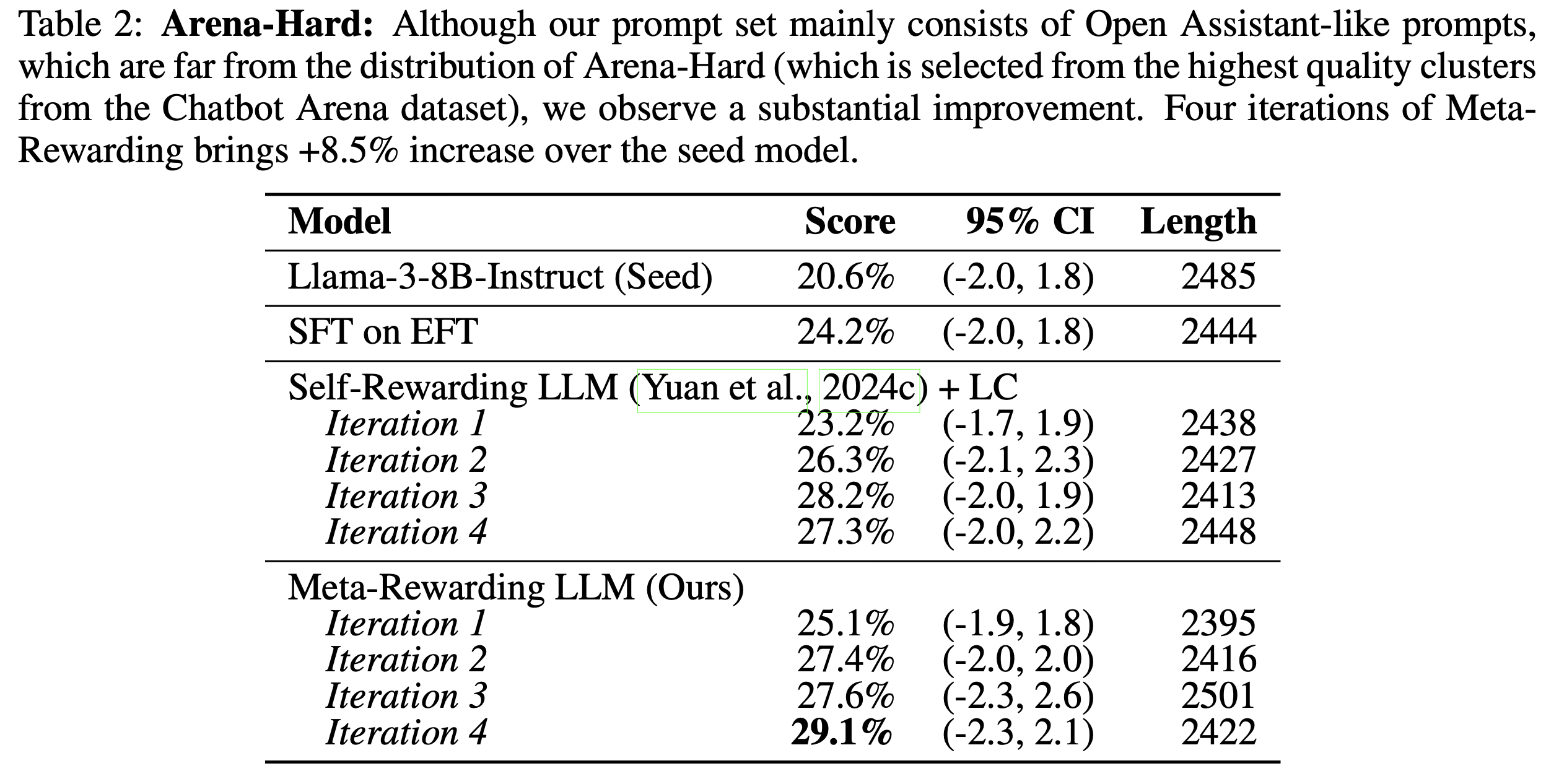
Arena-Hard 벤치마크에서도 높은 성능을 보인다. Arena-Hard는 실제 사용자의 어려운 질문들로 구성된 벤치마크로, 단순한 instruction following보다 깊은 이해력과 추론 능력을 요구한다.
Multi-turn 능력을 희생하지 않는다
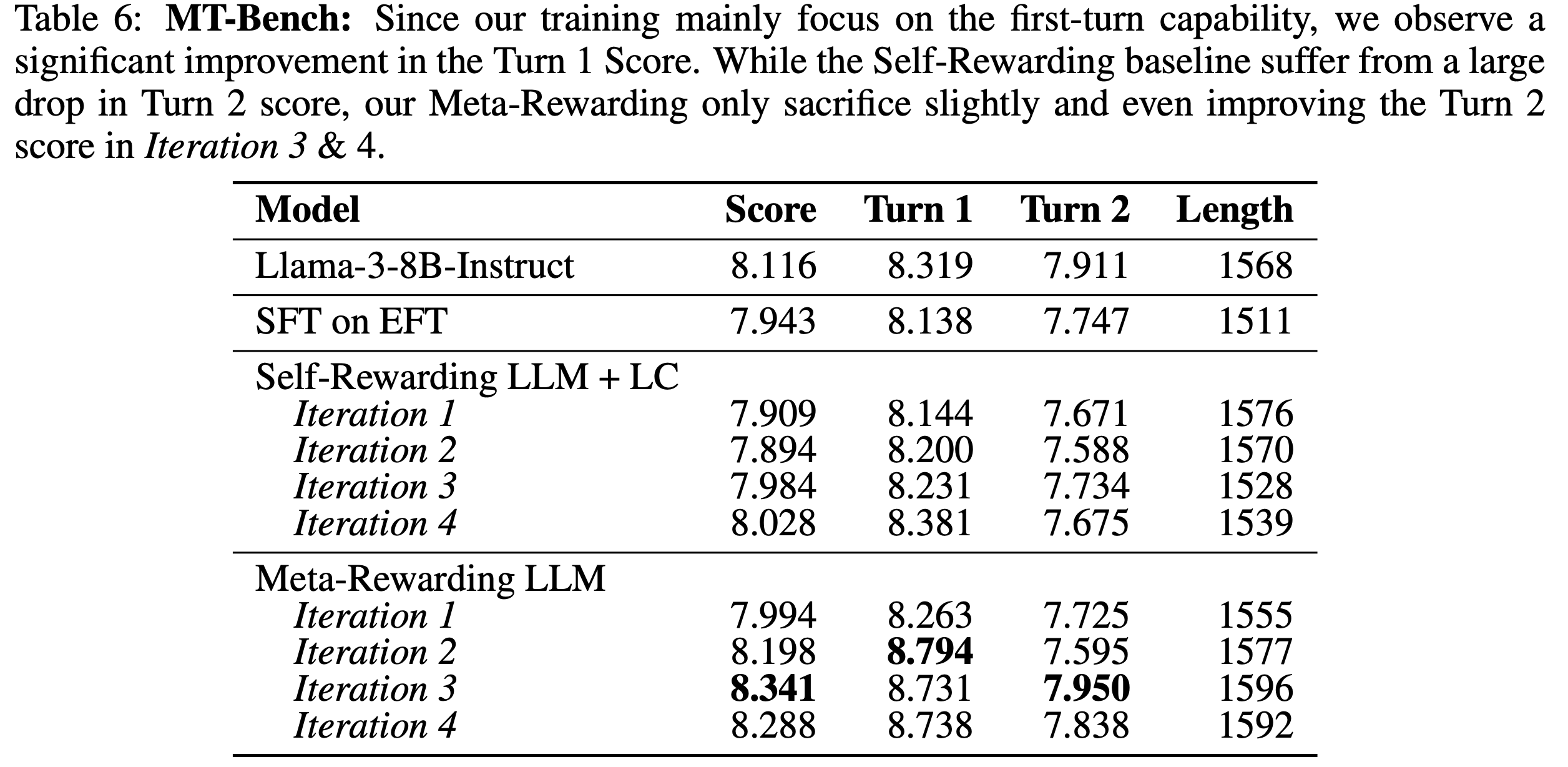
Meta-Rewarding은 single-turn 데이터만으로 학습했음에도, multi-turn 대화 성능이 유지되거나 오히려 개선된다. 이는 Judge 능력의 개선이 전반적인 언어 이해력 향상으로 이어지기 때문으로 추정된다.
Reward Modeling Evaluation
Meta-Rewarding의 핵심 가설은 “Judge 능력이 개선된다”는 것이다. 이를 직접 검증한다.
Judge 학습 후 평가 정확도가 향상된다

RewardBench에서 측정한 결과, Meta-Rewarding으로 학습한 모델은 GPT-4의 판단과의 상관관계가 향상된다. 이는 Judge preference pair가 실제로 Judge 능력을 개선시킨다는 직접적 증거이다.
사람의 판단과도 상관관계가 개선된다
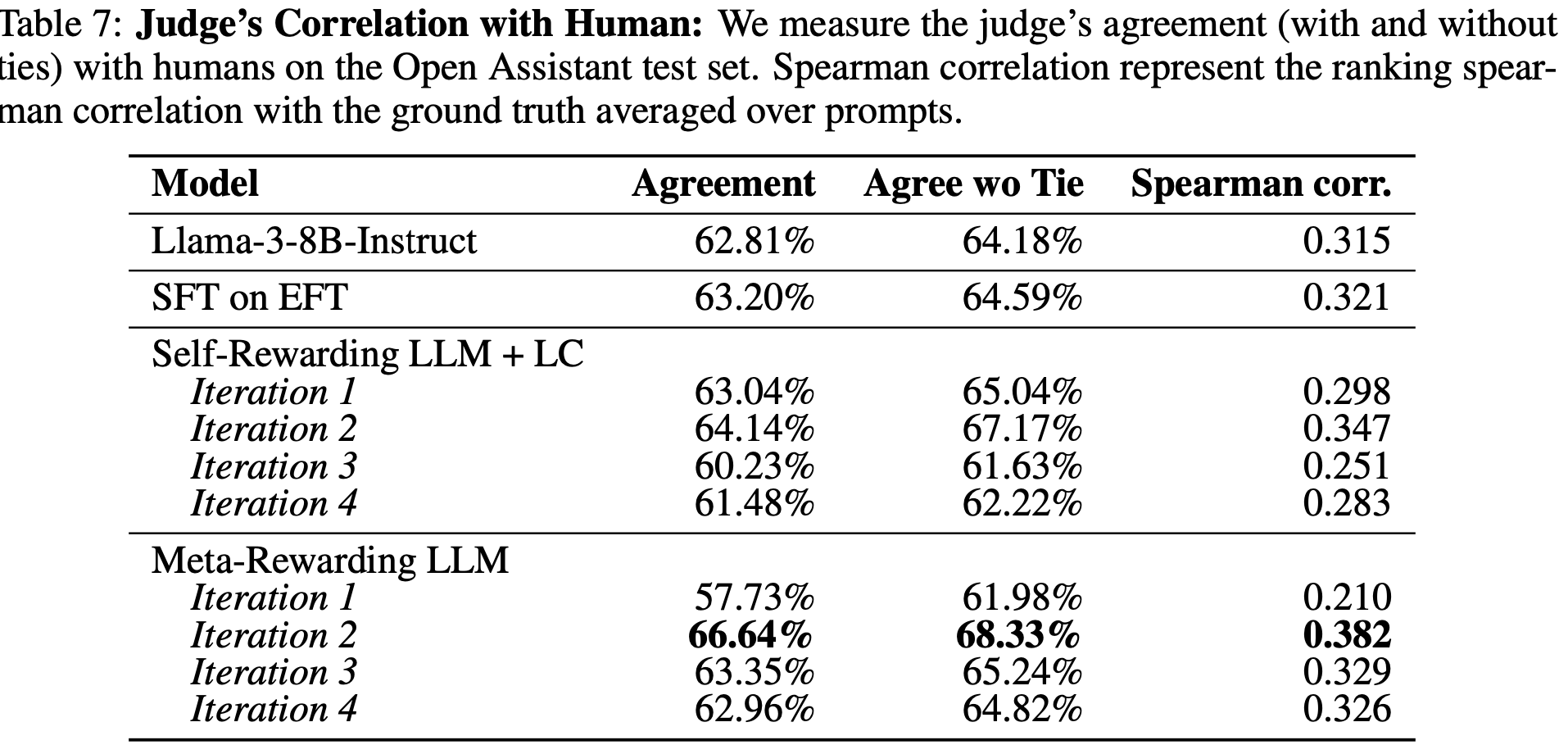
GPT-4뿐 아니라 사람 evaluator의 판단과의 상관관계도 개선된다. 이는 모델이 단순히 GPT-4를 따라하는 것이 아니라, 실제로 더 좋은 판단력을 학습한 것임을 의미한다.
Ablations and Analysis
Length Control이 없으면 verbosity가 증가한다

Length Control 메커니즘을 제거하면, iteration이 진행될수록 response 길이가 계속 증가한다. 이는 LLM의 known bias — 긴 response에 더 높은 점수를 주는 경향 — 가 self-training 과정에서 증폭되기 때문이다. Length Control은 이 positive feedback loop를 차단한다.
Meta-Judge에도 bias가 존재한다
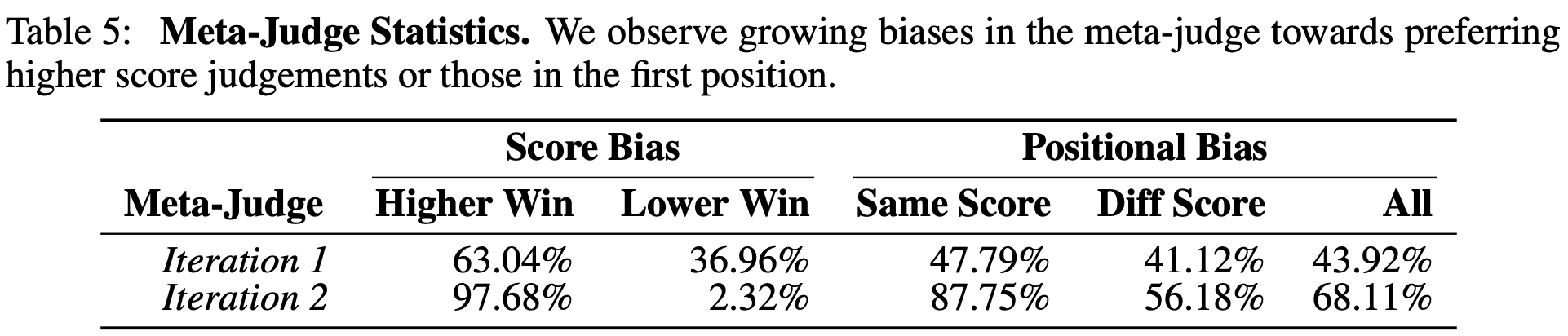
Meta-Judge는 높은 점수를 준 judge를 선호하는 경향이 있다. 즉, “더 관대한 judge가 더 좋다”고 판단하는 편향이 존재한다. 이는 Meta-Judge의 한계이며, 향후 개선이 필요한 부분이다.
Score 분포가 학습 중 편향된다

학습이 진행됨에 따라 Judge의 점수 분포가 5점(만점)에 집중되는 현상이 발견된다. 이는 Actor가 점점 더 좋은 response를 생성하면서 자연스러운 현상일 수 있지만, Judge의 변별력이 떨어지는 것도 의미한다. 5점 척도보다 더 세밀한 평가 체계가 필요할 수 있다.
Limitations
저자가 밝힌 한계:
- Meta-Judge bias: Meta-Judge가 관대한 judge를 선호하는 편향이 있다. 이로 인해 Judge가 점점 관대해질 수 있다.
- Score collapse: 학습이 진행되면 점수 분포가 만점에 집중되어 변별력이 떨어진다.
- Tie 편향: Judge가 quality 차이가 작은 response들을 tie로 판단하는 경향이 있어, 세밀한 구분이 어렵다.
- Single-turn만 학습: 현재는 single-turn instruction만 사용하므로, multi-turn 대화에 특화된 학습은 이루어지지 않는다.
Conclusion
Meta-Rewarding은 LLM의 자기 개선에서 Judge 능력의 개선이라는 누락된 고리를 추가한 방법론이다. Actor, Judge, Meta-Judge 세 역할을 하나의 모델이 수행하면서, 사람의 개입 없이 반복적으로 성능을 향상시킬 수 있다. 특히 Length Control과 Position bias 해결 등 실용적인 기법들이 잘 결합되어 있어, 실제 LLM alignment에 적용 가능한 방법론이다.
핵심 메시지: 좋은 Actor를 만들려면, 먼저 좋은 Judge를 만들어야 한다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: