LoRA vs Full Fine-tuning: An Illusion of Equivalence
Introduction
Pre-trained 모델을 downstream task에 fine-tuning하는 것은 computation-, data-efficient한 방법이다. 하지만 full fine-tuning은 모든 파라미터를 업데이트해야 하므로 시간과 비용적으로 부담이 크다. 이를 해결하기 위해 LoRA(Low-Rank Adaptation)와 같은 PEFT(Parameter-Efficient Fine-Tuning) 방법이 제시되었다. LoRA는 전체 파라미터의 극히 일부만 학습하면서도 full fine-tuning에 필적하는 성능을 보여주어 널리 사용되고 있다.
하지만 성능이 비슷하다고 해서 두 방법이 정말 같은 solution을 학습하는 걸까? 저자는 이 질문에 대해 weight matrix의 spectral properties(singular value decomposition)를 분석하여 답한다. 결론적으로, 같은 성능을 내더라도 LoRA와 full fine-tuning은 구조적으로 매우 다른 모델을 만든다.
핵심 발견:
- LoRA는 intruder dimensions을 도입한다 — pre-trained weight의 singular vector와 거의 직교(orthogonal)하는 새로운 high-ranking singular vector가 나타난다. Full fine-tuning에서는 이런 현상이 없다.
- Intruder dimensions은 forgetting을 유발한다 — intruder dimensions의 singular value를 줄이면 pre-training distribution의 모델링이 크게 개선되고, downstream 성능 저하는 미미하다.
- Continual learning에서 LoRA가 더 취약하다 — 여러 task를 순차적으로 학습할 때 intruder dimensions이 누적되어 성능이 떨어진다.
Background
LoRA: Low-Rank Adaptation
Pre-trained weight matrix \(W_0 \in \mathbb{R}^{m \times n}\)에 대해, full fine-tuning은 모든 원소를 업데이트하여 \(W = W_0 + \Delta W\)를 학습한다. 이때 학습 가능한 파라미터 수는 \(mn\)이다.
LoRA는 \(\Delta W\)를 두 개의 low-rank 행렬의 곱으로 분해한다.
\[\Delta W = \frac{\alpha}{r} BA, \quad B \in \mathbb{R}^{m \times r}, \; A \in \mathbb{R}^{r \times n}\]여기서 \(r \ll \min(m, n)\)이 rank이다. 학습 가능한 파라미터 수는 \((m + n)r\)로, \(mn\)에 비해 매우 작다. 예를 들어 \(m = n = 4096\)이고 \(r = 16\)이면, 파라미터가 \(16.8M\)에서 \(131K\)로 약 128배 줄어든다.
초기화 시 \(B = 0\), \(A \sim \mathcal{N}(0, \sigma^2)\)으로 설정하여 학습 시작 시 \(\Delta W = 0\)이 되도록 한다. Inference 시에는:
\[Y = W_{\text{tuned}} X = \left(W_0 + \frac{\alpha}{r} BA\right) X\]Scaling Parameter \(\alpha\)
\(\alpha\)는 LoRA update의 크기를 조절하는 파라미터이다. 많은 실무에서 \(\alpha = 2r\)로 설정하는데, 이는 rank가 바뀌어도 update 크기가 일정하게 유지되도록 하기 위함이다. 이 논문에서는 \(\alpha\)의 선택이 intruder dimensions의 수와 forgetting에 큰 영향을 미친다는 것을 보여준다.
Singular Value Decomposition (SVD)
임의의 행렬 \(M \in \mathbb{R}^{m \times n}\)은 다음과 같이 분해할 수 있다.
\[M = U \Sigma V^\top\]- \(U \in \mathbb{R}^{m \times m}\): 왼쪽 singular vectors (열벡터 \(u_1, \ldots, u_m\))
- \(\Sigma \in \mathbb{R}^{m \times n}\): singular values \(\sigma_1 \geq \sigma_2 \geq \ldots \geq 0\) (대각 행렬)
- \(V \in \mathbb{R}^{n \times n}\): 오른쪽 singular vectors
Singular value가 큰 singular vector일수록 행렬에서 더 중요한 방향을 나타낸다. 이 논문에서는 fine-tuning 전후의 singular vector 변화를 분석하여 LoRA와 full fine-tuning의 구조적 차이를 밝힌다.
Effective Rank
Effective rank는 singular value가 얼마나 집중되어 있는지를 측정한다. Frobenius norm의 90%를 차지하는 데 필요한 singular value의 개수로 정의한다. Effective rank가 낮으면 정보가 소수의 차원에 집중되어 있다는 뜻이다.
Structural Differences: Intruder Dimensions
핵심 관찰
저자는 Sharma et al. (2024)의 SVD 기반 pruning에서 영감을 얻어, fine-tuned weight matrix의 singular vector를 pre-trained weight matrix의 singular vector와 비교했다. 구체적으로, fine-tuned 모델의 각 singular vector \(y_j\)와 pre-trained 모델의 모든 singular vector \(x_i\) 사이의 최대 cosine similarity를 측정했다.
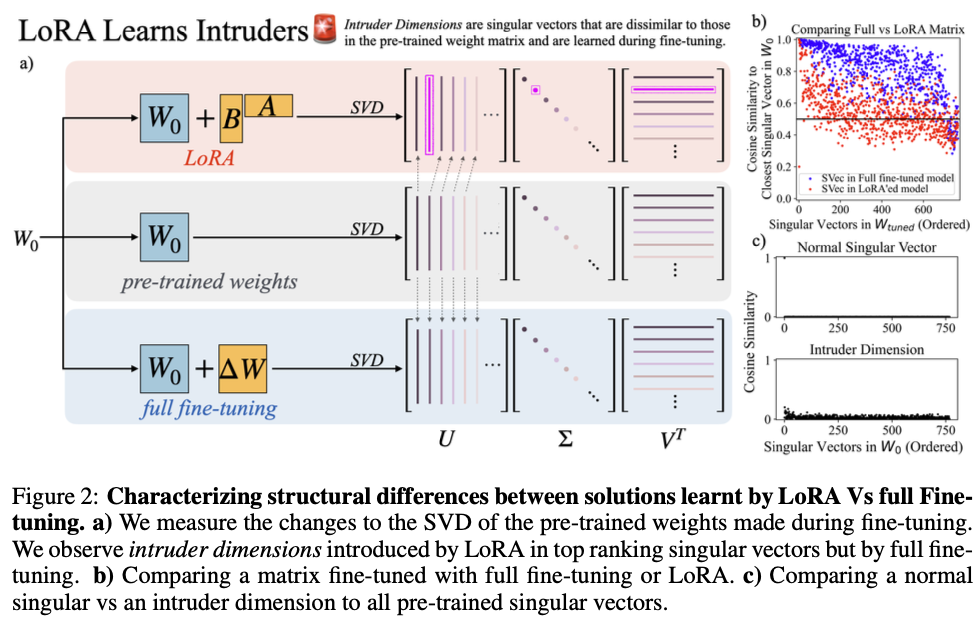
Fig. 2는 이 분석의 핵심 결과를 보여준다.
- (a) LoRA는 \(W_0 + BA\)로, full fine-tuning은 \(W_0 + \Delta W\)로 weight를 업데이트한다. 각각의 SVD를 구해서 pre-trained weight의 SVD와 비교한다.
- (b) Full fine-tuning의 singular vector는 pre-trained singular vector와 높은 cosine similarity를 가진다 (대각선 구조). 반면 LoRA(\(r = 64\))의 singular vector는 일부가 매우 낮은 cosine similarity를 보인다.
- (c) Intruder dimension은 모든 pre-trained singular vector와 낮은 cosine similarity를 가진다 (빨간 점).
Intruder Dimension의 정의
Definition 3.1. Fine-tuned weight matrix \(W_{\text{tuned}}\)의 singular vector \(y_j\)가 intruder dimension이라 함은, pre-trained weight matrix \(W_0\)의 모든 singular vector \(x_i\)에 대해 \(\max_i(\cos(y_j, x_i)) < \epsilon\)을 만족하는 것이다. 여기서 \(\epsilon\)은 similarity threshold이다.
직관적으로, intruder dimension은 pre-trained 모델이 전혀 알지 못하던 새로운 방향이다. Full fine-tuning은 기존 방향을 미세하게 조정하는 반면, LoRA는 완전히 새로운 방향을 추가한다.
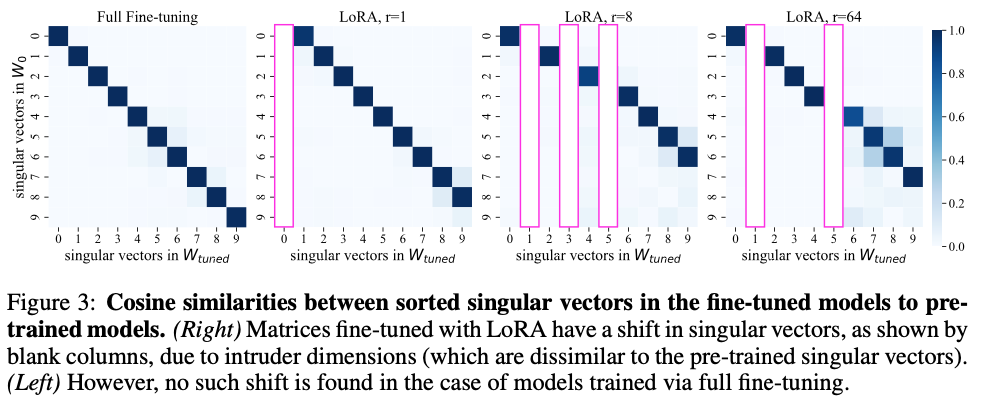
Fig. 3은 이 차이를 시각적으로 보여준다. Full fine-tuning (왼쪽)의 similarity matrix는 깨끗한 대각선 구조를 보인다. 즉, fine-tuned singular vector \(i\)가 pre-trained singular vector \(i\)에 잘 대응된다. 반면 LoRA (오른쪽)에는 빈 열(empty column)이 존재하는데, 이것이 intruder dimensions이다 — 어떤 pre-trained singular vector와도 대응되지 않는 새로운 방향이다.
실험 모델과 데이터셋
저자는 두 가지 모델로 실험했다.
- RoBERTa-base (125M): Encoder-only 모델. MNLI, QQP, SST-2, SiQA, WinoGrande, FEVER 등 6개 분류 태스크에서 fine-tuning
- LLaMA2-7B / LLaMA-7B: Decoder-only 모델. Alpaca(instruction tuning), MetaMathQA(수학), Magicoder(코드) 등에서 fine-tuning
실험 결과
1. LoRA는 high-ranking intruder dimensions을 가지지만, full fine-tuning은 그렇지 않다

Top-\(k\) singular vectors에 대해 Algorithm 1을 적용하면:
- LoRA: \(r \leq 16\)에서 모든 \(\epsilon\)에 대해 지속적으로 intruder dimensions이 존재한다.
- Full fine-tuning: 심지어 \(\epsilon = 0.6 \sim 0.9\)처럼 관대한 threshold에서도 intruder dimensions이 거의 없다.
- Rank가 올라갈수록 intruder dimensions이 줄어든다. \(r = 2048\)에서는 full fine-tuning과 유사해진다.
2. 수학/코드 같은 어려운 태스크에서도 intruder dimensions이 존재한다
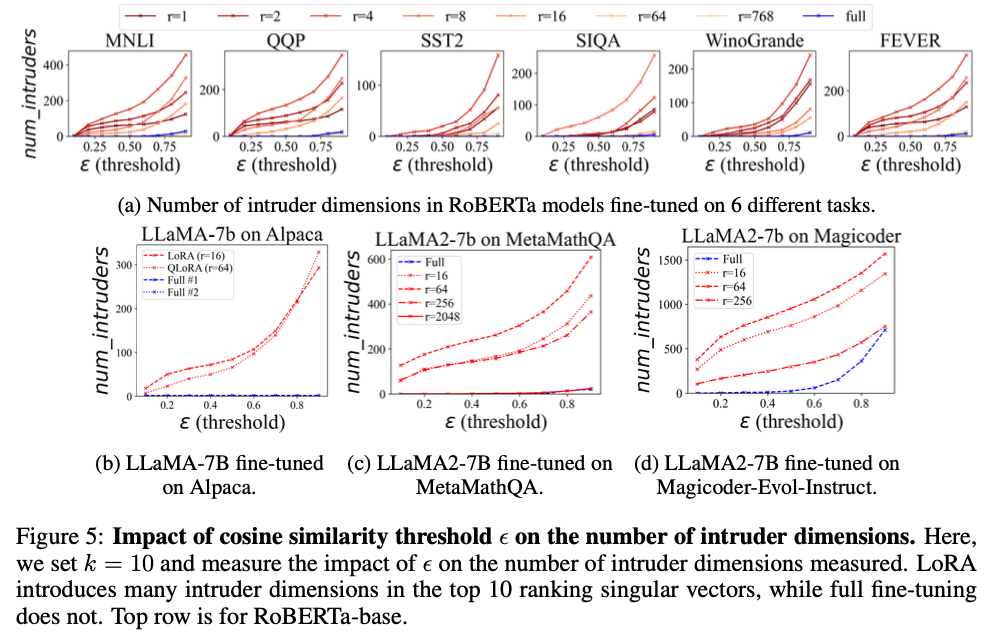
LLaMA2-7B를 MetaMathQA(수학)와 Magicoder(코드)로 fine-tuning한 경우에도 LoRA는 intruder dimensions을 보인다. 이는 pre-training domain과 target domain의 차이에서 비롯된다. 특히 코드처럼 pre-training과 매우 다른 도메인에서는 full fine-tuning도 일부 intruder dimensions을 보이지만, LoRA가 여전히 훨씬 많다.
3. Full fine-tuning은 LoRA보다 높은 effective rank를 가진다
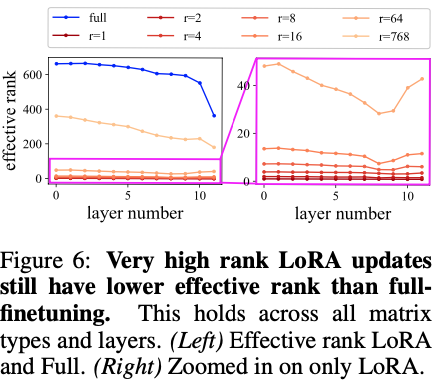
\(r = 768\)인 full-rank LoRA조차도 실제 effective rank는 약 300에 그친다. 즉, LoRA는 파라미터화된 capacity \(r\)을 전부 활용하지 못한다. 반면 full fine-tuning의 \(\Delta W\)는 더 높은 effective rank로 업데이트를 수행한다. 이 차이는 코딩 같은 어려운 태스크에서 더 두드러진다.
4. Intruder dimensions은 singular value의 크기와 무관하게 존재한다
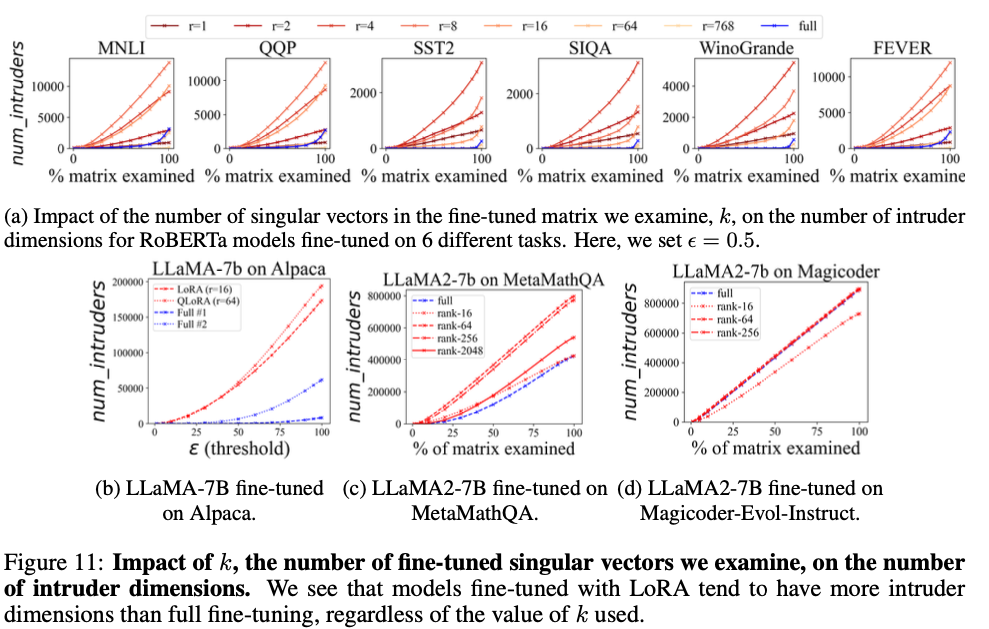
High singular value(중요한 방향)뿐 아니라 low singular value 영역에서도 LoRA는 full fine-tuning보다 항상 더 많은 intruder dimensions을 가진다.
5. \(\alpha = 2r\)로 설정하면 intruder dimensions이 줄고 effective rank가 늘어난다
많은 논문에서 \(\alpha = 2r\)로 설정한다. 저자는 \(\alpha = 2r\)과 \(\alpha = 8\)(고정)을 비교한 결과:
- \(\alpha = 8\): 모든 rank에서 intruder dimensions이 많고, effective rank가 낮다
- \(\alpha = 2r\): intruder dimensions이 적고, effective rank가 높다 — generalization도 더 좋다
이는 \(\alpha = 2r\) 설정의 중요성을 뒷받침한다.
6. Fine-tuning 데이터가 많을수록 intruder dimensions이 늘어난다
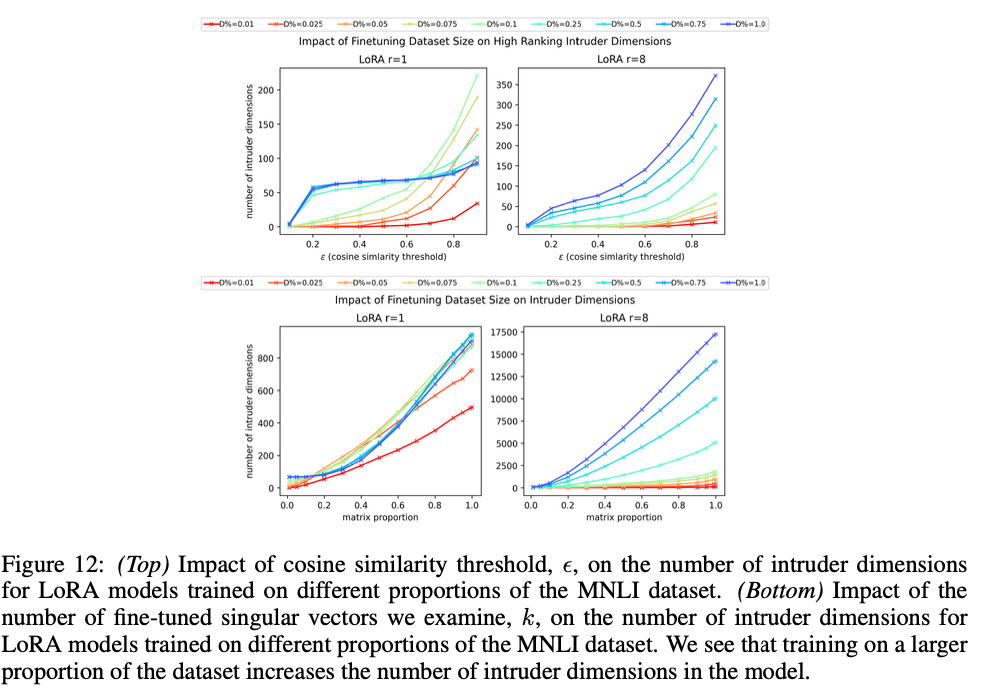
\(r = 8\)에서 여러 데이터셋을 학습시키면 intruder dimensions이 누적된다. \(r = 1\)에서는 표현력 한계 때문에 일정하지만, 충분한 rank가 있으면 데이터가 많을수록 새로운 intruder dimensions이 추가된다.
Intruder Dimensions의 진화
Intruder dimensions은 학습 초기부터 점진적으로 나타난다. 학습이 진행됨에 따라:
- Intruder dimension의 rank가 점점 높아진다 (더 중요한 위치를 차지한다)
- Singular value가 점점 커진다 (영향력이 증가한다)
- Pre-trained singular vectors와의 cosine similarity는 계속 낮게 유지된다
Model Differences: Forgetting과 Out-of-Distribution Generalization
LoRA는 full fine-tuning보다 덜 잊지만, 그 forgetting은 intruder dimensions에 집중된다
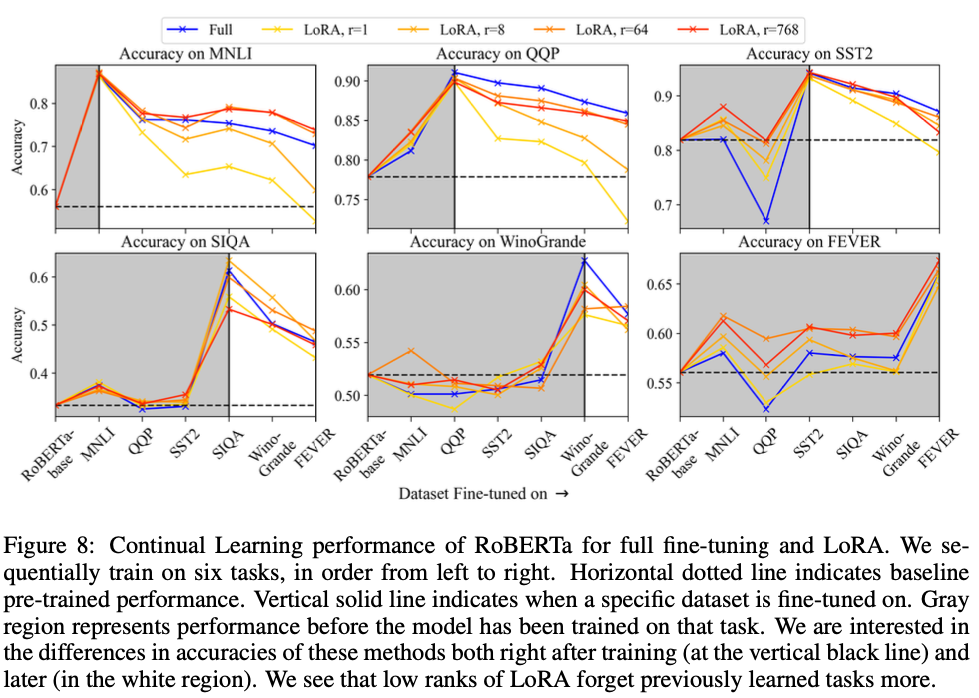
Fig. 6에서 forgetting(pre-training distribution의 pseudo loss 증가)을 측정한 결과:
- LLaMA2-7B: LoRA는 rank가 작을수록 더 많이 잊는다. Full fine-tuning이 가장 적게 잊는다.
- RoBERTa-base: 마찬가지로 LoRA의 rank가 낮을수록 pseudo loss가 크다.
놀라운 점은, learning rate가 클수록 intruder dimensions이 더 많이 생기고 (왼쪽), 그에 비례하여 forgetting도 증가한다는 것이다 (오른쪽). Intruder dimensions과 forgetting 사이의 Spearman correlation은 \(\rho = 0.971\) (\(p \ll 0.001\))로 매우 강한 상관관계를 보인다.
반면 intruder dimensions과 test accuracy 사이에는 통계적으로 유의미한 상관관계가 없다. 이는 intruder dimensions이 성능에는 불필요하지만 forgetting을 유발한다는 것을 의미한다.
Pre-training pseudo loss의 U-shaped curve
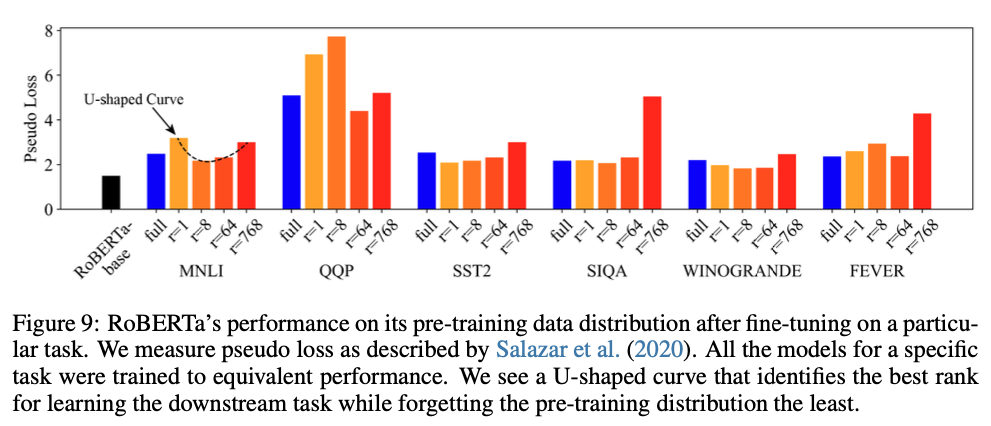
같은 test accuracy로 fine-tuning했을 때, pre-training pseudo loss가 rank에 대해 U자 곡선을 그린다. 이는:
- Rank가 너무 낮으면: intruder dimensions의 영향으로 forgetting이 크다
- Rank가 너무 높으면: overparameterization으로 target task에 overfitting
따라서 downstream task마다 최적의 rank가 존재한다.
Intruder Dimensions이 Forgetting을 야기하는가: Causal Intervention
상관관계를 넘어 인과관계를 확인하기 위해, 저자는 intruder dimensions에 직접 개입(intervention)하는 실험을 수행한다.
실험 방법
각 weight matrix에서 가장 high-ranking인 intruder dimension의 singular value를 조절한다. 구체적으로:
\[W = W_0 + \Delta W + (\lambda - 1) u_i \sigma_i v_i^\top\]여기서 \(i\)는 top intruder dimension의 인덱스이다.
- \(\lambda = 0\): intruder dimension 완전 제거
- \(\lambda = 1\): 변화 없음 (원본)
- \(\lambda > 1\): intruder dimension 증폭

결과
Fig. 8에서 \(\lambda\)를 0부터 1까지 변화시키면:
- Forgetting (빨간선): intruder dimensions을 줄이면 forgetting이 크게 감소한다
- Test accuracy (초록선): 거의 변하지 않거나 아주 약간 감소한다
구체적 수치:
- LLaMA2-7B (MetaMath, \(r = 256\)): \(\lambda = 0.3\)에서 test accuracy -0.1%, forgetting -33.3%
- RoBERTa (QQP, \(r = 8\)): \(\lambda = 0.7\)에서 test accuracy 동일, forgetting -33.2%
일부 경우에는 \(\lambda > 1\) (intruder dimension 증폭)에서 오히려 test accuracy가 향상되면서 forgetting이 악화되는 현상도 관찰된다.
중요한 점은, 이 효과가 intruder dimensions에만 해당한다는 것이다. Pre-trained singular vector에 가까운 normal dimensions의 singular value를 같은 방식으로 조절하면 forgetting에 큰 영향이 없고, 오히려 test accuracy가 떨어진다.
Continual Learning에서의 영향
실험 설정
Intruder dimensions이 누적되면 해로울 것이라는 가설을 검증하기 위해, RoBERTa를 6개 태스크에 순차적으로 fine-tuning한다: MNLI → QQP → SST-2 → SiQA → WinoGrande → FEVER.
각 태스크 학습 후 LoRA weights를 모델에 merge하고, adapter를 재초기화한 후 다음 태스크를 학습한다. 각 시점에서 모든 태스크의 성능을 측정한다.

결과
Fig. 9(a)에서:
- Full fine-tuning: 6개 태스크를 순차 학습해도 이전 태스크 성능이 비교적 잘 유지된다
- LoRA (\(r = 1, 8, 64\)): 모든 rank에서 full fine-tuning보다 빠르게 이전 태스크를 잊는다
- Low rank(\(r = 1\))이 가장 빠르게 성능이 저하된다
Fig. 9(b)에서 LoRA(\(r = 8\))의 similarity matrix를 보면, 각 태스크가 학습될 때마다 새로운 intruder dimensions이 추가되는 것을 확인할 수 있다. MNLI(1번째) → QQP(2번째) → … → FEVER(6번째)로 갈수록 intruder dimensions이 누적된다.
반면 Fig. 9(c)에서 full fine-tuning의 similarity matrix는 6개 태스크를 거쳐도 대각선 구조가 유지된다. Pre-trained structure를 보존하면서 적응하기 때문이다.
왜 Intruder Dimensions이 발생하는가
1. Low-rank constraint
LoRA의 update \(\Delta W = BA\)는 rank \(r\)로 제한된다. Pre-trained weight의 주요 방향과 잘 align되지 않는 경우, LoRA는 제한된 rank 안에서 task를 풀기 위해 기존에 없던 새로운 방향을 만들어낸다. Rank가 충분히 높으면 (\(r \geq 2048\)) 이 문제가 완화되어 full fine-tuning과 유사해진다.
2. Learning rate와 gradient projection
LoRA는 일반적으로 full fine-tuning보다 더 큰 learning rate를 사용한다. 또한 gradient가 low-rank space로 projection되므로, 업데이트 방향이 full-rank gradient와 달라진다. 이 두 요소가 합쳐져 pre-trained structure에서 크게 벗어나는 업데이트가 발생한다.
3. Product parameterization (\(BA\))
두 행렬의 곱은 spectral differences를 증폭시킨다. \(B\)만 학습시키고 \(A\)를 고정하면 intruder dimensions이 줄어드는 것이 이를 뒷받침한다.
Practical Implications
이 논문의 발견은 LoRA를 실무에서 사용할 때 다음과 같은 시사점을 준다.
- Rank 선택: 가능하면 높은 rank를 사용하라. Low rank는 intruder dimensions을 유발하고 forgetting을 악화시킨다.
- \(\alpha\) 설정: \(\alpha = 2r\)이 \(\alpha = \text{constant}\)보다 intruder dimensions이 적고 generalization이 좋다.
- Continual learning 주의: LoRA로 여러 태스크를 순차 학습하면 intruder dimensions이 누적되어 성능이 저하된다. 가능하면 adapter를 combine하지 말고 별도로 유지하라.
- 모델 선택 기준: 같은 test accuracy를 가진 두 모델 중, intruder dimensions이 적은 모델이 out-of-distribution에서 더 robust하다.
- Post-hoc mitigation: 이미 학습된 LoRA 모델에서 intruder dimensions의 singular value를 줄이면 (\(\lambda \approx 0.3 \sim 0.7\)), 성능 저하 없이 forgetting을 크게 줄일 수 있다.
Conclusion
저자는 LoRA와 full fine-tuning이 같은 성능을 내더라도 weight matrix의 spectral properties에서 구조적으로 매우 다르다는 것을 보여주었다. LoRA는 pre-trained singular vectors와 orthogonal한 intruder dimensions을 도입하며, 이것이 forgetting의 직접적 원인이 된다. Full fine-tuning은 pre-trained spectral structure를 유지하면서 효과적으로 적응한다.
이 발견은 “LoRA가 full fine-tuning과 동등하다”는 통념에 의문을 제기하며, 성능 지표만으로는 두 방법의 차이를 포착할 수 없다는 점을 강조한다. 특히 continual learning처럼 여러 task를 순차 학습하는 현실적 시나리오에서 intruder dimensions의 누적은 심각한 문제가 될 수 있다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: