Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method 설명
Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method
Introduction
많은 LLM 개발자들은 사용된 학습 코퍼스를 비공개로 처리한다. 이는 저작권, 윤리적 문제, 그리고 경쟁 우위 등의 이유 때문이다. 그런데 이런 상황에서 중요한 질문이 있다.
“주어진 텍스트가 특정 LLM의 학습 데이터에 포함되어 있었는지 알 수 있을까?”
이를 Pretraining Data Detection 또는 Membership Inference Attack(MIA)이라고 한다. 이 문제는 다음과 같은 이유로 중요하다.
- 저작권 보호: 내 글이 LLM 학습에 무단으로 사용되었는지 확인
- 벤치마크 오염 검증: 모델 평가에 사용되는 벤치마크 데이터가 학습에 포함되었는지 확인 (data contamination)
- 프라이버시: 개인정보가 학습 데이터에 포함되었는지 검증
기존 접근법의 한계
기존 방법들은 주로 LLM이 출력하는 토큰 확률 자체를 사용했다. 예를 들어, 텍스트의 perplexity가 낮으면 학습 데이터에 포함되었을 가능성이 높다고 판단하는 방식이다. 하지만 이 접근에는 문제가 있다.
- 자주 사용되는 일반적인 문장(예: “오늘 날씨가 좋다”)은 학습 데이터에 없더라도 perplexity가 낮을 수 있다
- 반대로 전문적인 텍스트는 학습 데이터에 있더라도 perplexity가 높을 수 있다
즉, 토큰 확률 자체만으로는 “이 텍스트를 학습했기 때문에 확률이 높은 건지”와 “원래 흔한 텍스트라서 확률이 높은 건지”를 구분할 수 없다.
핵심 아이디어: Divergence-from-Randomness
저자는 정보 검색(Information Retrieval) 분야의 Divergence-from-Randomness 프레임워크에서 영감을 받았다. 이 개념의 핵심은 다음과 같다.
특정 단어의 중요도를 판단할 때, 두 가지 빈도를 비교한다.
- Within-document term-frequency: 해당 문서 안에서 단어가 얼마나 자주 등장하는지
- Collection-wide frequency: 전체 문서 컬렉션에서 단어가 얼마나 자주 등장하는지
만약 어떤 단어가 전체 컬렉션에서는 드물지만 특정 문서에서 자주 나온다면, 그 단어는 해당 문서에서 특별히 중요한 정보를 담고 있다고 판단한다. TF-IDF와 비슷한 직관이다.
저자는 이를 LLM에 적용한다.
| IR 개념 | LLM에서의 대응 |
|---|---|
| Within-document frequency | LLM이 예측한 토큰 확률 \(p(x_i \mid x_{<i}; \mathcal{M})\) |
| Collection-wide frequency | 참조 코퍼스에서의 토큰 빈도 \(p(x_i; \mathcal{D}')\) |
LLM이 특정 토큰에 높은 확률을 부여했는데, 그 토큰이 일반적으로 드문 토큰이라면 → 이는 모델이 해당 텍스트를 “외웠기 때문”일 가능성이 높다. 반면, 높은 확률이 부여되었더라도 원래 흔한 토큰이라면 → 단순히 언어의 통계적 특성일 뿐이다.
이 두 분포의 divergence(발산)가 높을수록 해당 텍스트가 학습 데이터에 포함되었을 가능성이 높다.
방법론: DC-PDD (Divergence-based Calibration for Pretraining Data Detection)
문제 정의
텍스트 \(x\), 블랙박스 LLM \(\mathcal{M}\), 접근 불가능한 학습 코퍼스 \(\mathcal{D}\)에 대해, 검출 함수 \(\mathcal{A}\)를 다음과 같이 정의한다.
\[\mathcal{A}(x, \mathcal{M}) \rightarrow \{0, 1\}\]- \(1\): 텍스트 \(x\)가 \(\mathcal{D}\)에 포함됨 (member)
- \(0\): 포함되지 않음 (non-member)
이때 모델의 내부 파라미터에는 접근할 수 없고, 토큰 확률만 질의할 수 있다는 제약이 있다.
전체 파이프라인
DC-PDD는 4단계로 구성된다.
Step 1: Token Probability Distribution Computation
시작 토큰 \(x_0\)를 포함하여 텍스트를 \(x' = x_0 x_1 x_2 \ldots x_n\)으로 정의한다. LLM \(\mathcal{M}\)에 질의하여 각 토큰의 조건부 확률을 계산한다.
\[\{p(x_i \mid x_{<i}; \mathcal{M}) : 0 < i \leq n\}\]이것이 Token Probability Distribution이다. 모델이 텍스트를 “얼마나 잘 아는지”를 나타낸다.
Step 2: Token Frequency Distribution Computation
접근 가능한 대규모 참조 코퍼스 \(\mathcal{D}'\)를 사용하여 각 토큰의 빈도를 추정한다. \(\mathcal{D}'\)는 모델의 학습 코퍼스 \(\mathcal{D}\)와 다를 수 있다.
\[p(x_i; \mathcal{D}') = \frac{\text{count}(x_i)}{N'}\]여기서 \(N'\)는 참조 코퍼스의 전체 토큰 수이다. 만약 \(x_i\)가 참조 코퍼스에 존재하지 않는 경우, 라플라스 스무딩(Laplace Smoothing)을 적용한다.
\[p(x_i; \mathcal{D}') = \frac{\text{count}(x_i) + 1}{N' + |V|}\]| 여기서 $$ | V | $$는 vocabulary 크기이다. |
Step 3: Score Calculation via Cross-Entropy
두 분포를 비교하여 각 토큰의 calibrated score를 계산한다. Cross-entropy를 사용한다.
\[\alpha_i = -p(x_i; \mathcal{M}) \cdot \log p(x_i; \mathcal{D}')\]직관적으로 해석하면:
- \(p(x_i; \mathcal{M})\)이 높고 (모델이 이 토큰을 잘 예측) + \(p(x_i; \mathcal{D}')\)가 낮으면 (일반적으로 드문 토큰) → \(\alpha_i\)가 크다 → 학습 데이터에 포함되었을 가능성이 높다
- \(p(x_i; \mathcal{M})\)이 높더라도 \(p(x_i; \mathcal{D}')\)도 높으면 (흔한 토큰) → \(\alpha_i\)가 작다 → 단순히 흔한 표현일 뿐
Upper Bound (LUP)
특정 토큰이 점수에 과도한 영향을 미치는 것을 방지하기 위해 상한선 \(a\)를 설정한다.
\[\alpha_i = \begin{cases} \alpha_i, & \text{if } \alpha_i < a \\ a, & \text{if } \alpha_i \geq a \end{cases}\]이 upper bound \(a\)는 토큰별로 다르게 적용해야 최적의 성능을 낸다. 이에 대한 분석은 ablation에서 다룬다.
First Occurrence Sampling (FOS)
텍스트 내에서 같은 토큰이 여러 번 등장하면, 첫 번째 등장만 사용한다. 두 번째부터는 모델이 context에서 이미 본 토큰이므로 확률이 자연스럽게 높아지기 때문이다.
\[\text{FOS}(x) = \{x_j : x_j \notin \{x_1, \ldots, x_{j-1}\}\}\]최종 점수는 FOS에 속하는 토큰의 평균이다.
\[\beta = \frac{1}{|\text{FOS}(x)|} \sum_{x_j \in \text{FOS}(x)} \alpha_j\]Step 4: Binary Decision
임계값 \(\tau\)를 적용하여 최종 판단을 내린다.
\[\text{Decision}(x, \mathcal{M}) = \begin{cases} 0 \; (x \notin \mathcal{D}), & \text{if } \beta < \tau \\ 1 \; (x \in \mathcal{D}), & \text{if } \beta \geq \tau \end{cases}\]Experimental Results
실험 설정
데이터셋
- WikiMIA: Wikipedia 데이터 기반 벤치마크. 특정 시점 이전/이후의 Wikipedia 문서를 사용하여 member/non-member를 구분한다.
- 다양한 길이(32, 64, 128, 256 토큰)의 텍스트로 실험
대상 모델
- LLaMA: 7B, 13B, 30B, 65B
- Pythia: 다양한 크기
- GPT-Neo: 다양한 크기
비교 방법
- PPL (Perplexity): 텍스트의 perplexity가 낮으면 member로 판단
- Lowercase: 소문자 변환 후 perplexity 비교
- Zlib: zlib 압축 비율과 perplexity 비교
- Ref (Reference Model): 작은 참조 모델의 perplexity와 비교
- Min-K%: 가장 확률이 낮은 K%의 토큰만 사용
평가 지표
- AUC (Area Under the ROC Curve): threshold에 독립적인 전체 성능 지표
- TPR@5%FPR: False Positive Rate 5%에서의 True Positive Rate
Main Result
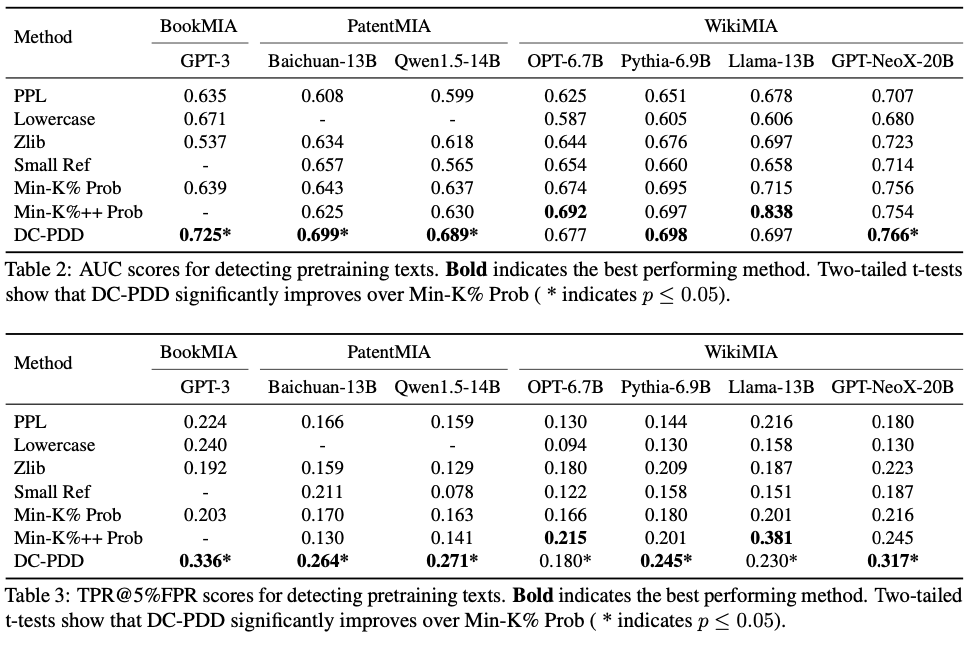
WikiMIA 벤치마크에서 DC-PDD(논문 제안 방법, 표에서 CLD)는 대부분의 모델과 텍스트 길이에서 기존 방법을 일관되게 상회한다. 특히:
- 긴 텍스트(256 토큰)에서 성능이 가장 좋다 — 토큰이 많을수록 통계적으로 안정적인 점수를 얻을 수 있기 때문
- 큰 모델(65B)에서도 잘 작동한다 — 기존 perplexity 기반 방법은 큰 모델에서 모든 텍스트에 대해 낮은 perplexity를 보여 구분이 어려운데, divergence 기반 calibration이 이를 보완한다
Ablation Studies
각 구성 요소의 기여
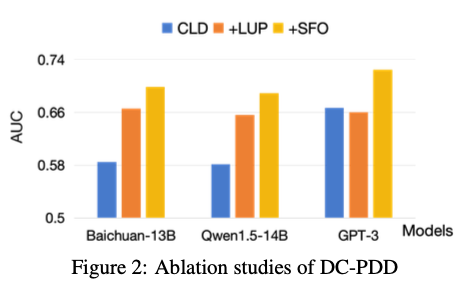
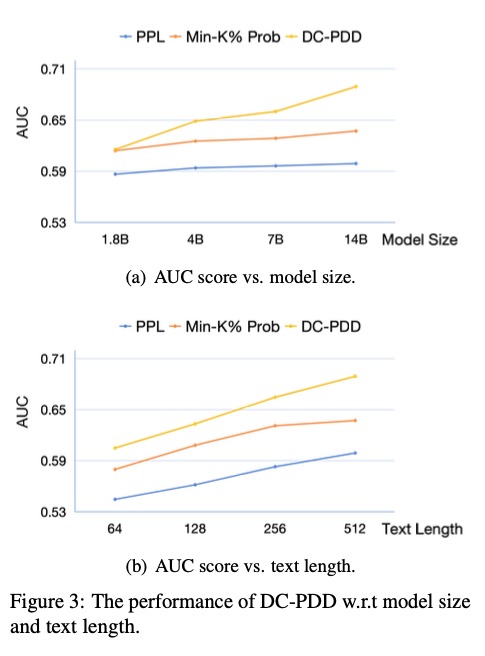
| 구성 요소 | 설명 | 효과 |
|---|---|---|
| CLD (기본) | Cross-entropy 기반 divergence 계산 | Baseline |
| +LUP (Upper Bound) | 토큰별 상한선 적용으로 이상치 영향 감소 | AUC 향상 |
| +SFO (First Occurrence) | 중복 토큰 제거로 context bias 제거 | 추가 AUC 향상 |
세 가지를 모두 합친 CLD+LUP+SFO가 최고 성능을 달성한다.
참조 코퍼스의 영향
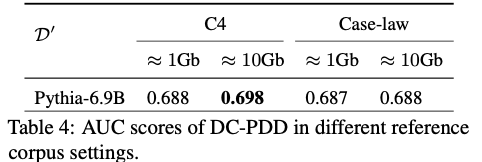
참조 코퍼스 \(\mathcal{D}'\)로 어떤 데이터를 사용하든 결과에 큰 차이가 없다. 이는 DC-PDD의 강점이다 — 모델의 학습 데이터와 정확히 같은 코퍼스가 없어도 일반적인 대규모 텍스트 코퍼스만 있으면 된다. 토큰의 “일반적인 빈도”만 추정하면 되기 때문에, 코퍼스의 도메인이 정확히 일치할 필요가 없다.
Upper Bound 설정
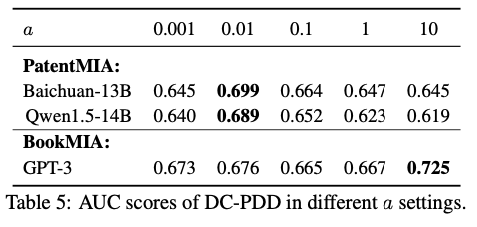
Upper bound \(a\)는 모든 토큰에 동일하게 적용하는 것보다 토큰별로 다르게 적용하는 것이 효과적이다. 드문 토큰은 큰 upper bound를, 흔한 토큰은 작은 upper bound를 사용해야 한다. 이는 드문 토큰의 divergence 값이 자연스럽게 크기 때문에, 일률적인 상한선을 적용하면 중요한 신호가 잘릴 수 있기 때문이다.
왜 이 방법이 잘 작동하는가
기존 방법들이 “모델이 이 텍스트를 얼마나 잘 예측하는가”만 보았다면, DC-PDD는 “모델이 이 텍스트를 일반적인 수준 이상으로 잘 예측하는가”를 본다.
예를 들어:
- “the”라는 토큰에 대해 모델이 95% 확률을 부여 → 기존 방법은 “잘 안다!”라고 판단 → 하지만 “the”는 누구나 잘 예측하는 토큰 → 오탐(false positive)
- DC-PDD는 “the”의 참조 코퍼스 빈도도 높으므로 divergence가 작다고 판단 → 올바르게 무시
반대로:
- 전문 용어 “WGMMA”에 대해 모델이 70% 확률을 부여 → 기존 방법은 “잘 모른다”로 판단 → 하지만 “WGMMA”는 일반적으로 매우 드문 토큰
- DC-PDD는 참조 코퍼스 빈도가 매우 낮으므로 divergence가 크다고 판단 → 학습 데이터에 포함되었을 가능성 높다
이처럼 토큰의 “일반적인 기대”를 기준으로 calibration하는 것이 DC-PDD의 핵심이다.
Conclusion
DC-PDD는 정보 검색의 Divergence-from-Randomness를 LLM의 학습 데이터 탐지에 적용한 방법이다. LLM의 토큰 확률을 참조 코퍼스의 토큰 빈도로 calibration하여, 모델이 “학습했기 때문에” 잘 예측하는 것과 “원래 쉬운 텍스트라서” 잘 예측하는 것을 구분한다. 참조 코퍼스의 종류에 robust하고, 블랙박스 모델에도 적용 가능하며, 기존 방법들을 일관되게 상회하는 성능을 보여준다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: