AgentBench: Evaluating LLMs as Agents
AgentBench: Evaluating LLMs as Agents (Liu et al., THUDM, ICLR 2024)
Introduction
LLM의 능력이 빠르게 발전하면서 평가 방식도 함께 진화해왔다. MMLU(Hendrycks et al., 2021)와 HumanEval(Chen et al., 2021)이 “지식과 코드”를 측정했다면, 2023년 ChatGPT plugin, AutoGPT, BabyAGI가 등장하면서 새로운 질문이 떠올랐다.
“LLM이 자율 에이전트(agent)로 작동할 때 얼마나 잘 하는가?”
이 질문에 답할 도구는 거의 없었다. 기존 벤치마크는 두 가지 한계가 있다.
- 단발성 입출력 평가: MMLU·HumanEval 같은 정적 QA는 multi-turn interaction을 측정하지 못한다.
- 단일 환경 한정: TextWorld·Jericho 같은 텍스트 게임 환경은 좁고 closed action space에 갇혀 있다.
저자는 이 공백을 메우기 위해 AgentBench를 제안한다. AgentBench는 LLM을 agent로 평가하는 최초의 체계적·다환경 벤치마크다. 구체적으로는 다음과 같은 기여를 한다.
- 8개 환경 × 3가지 grounding 타입(Code, Game, Web)에서 cross-domain agent 능력 평가
- multi-turn interaction 형식으로 환경과의 자연스러운 상호작용을 측정
- 27개 LLM (상용 API + 오픈소스)을 평가하여 API 모델과 오픈소스의 격차를 정량화
- 모듈화된 평가 toolkit(Docker 기반 server-client 구조)을 공개
이 논문은 ICLR 2024에 발표되었고, 이후 거의 모든 종합 agent 벤치마크가 AgentBench의 multi-environment + multi-turn 구조를 차용한다.
Related Work
LLM 평가는 크게 세 갈래로 발전해왔다.
| 분류 | 대표 벤치마크 | 한계 |
|---|---|---|
| 전통적 QA | MMLU, HumanEval, BIG-Bench, HELM | open-ended generation, multi-round 평가 불가 |
| 텍스트 게임 | TextWorld, Jericho | closed action space, commonsense grounding에만 집중 |
| 임바디드 시뮬레이터 | ALFWorld, VirtualHome | multi-modal 셋업 필요, text-only LLM과 mismatch |
이런 분리된 환경들은 각각 특정 능력만을 측정한다. 실제 agent는 여러 환경에서 동일한 LLM을 일관되게 평가할 수 있어야 한다. AgentBench는 이 통합 평가를 처음으로 시도했다.
또한 기존 single-environment 벤치마크(WebShop, ALFWorld 등)는 한 가지 도메인에서만 잘하는 모델을 “agent”라고 부르는 모순을 낳았다. AgentBench는 8개의 이질적 환경을 동시에 평가함으로써 진정한 일반화 능력을 측정하려 한다.
AgentBench의 8가지 환경
AgentBench는 환경을 grounding 타입에 따라 3가지로 분류한다.
| Grounding | 환경 | 출처 |
|---|---|---|
| Code | Operating System (OS) | 신규 구축 |
| Code | Database (DB) | 신규 구축 (실제 MySQL) |
| Code | Knowledge Graph (KG) | Freebase 기반 |
| Game | Digital Card Game (DCG) | Aquawar (THU Agent Competition) |
| Game | Lateral Thinking Puzzles (LTP) | 신규 구축 (Haoda 류) |
| Game | House-Holding (HH) | ALFWorld |
| Web | Web Shopping (WS) | WebShop |
| Web | Web Browsing (WB) | Mind2Web |
각 환경의 인스턴스 수와 평균 라운드는 다음과 같다.
| 환경 | Dev | Test | 평균 라운드 | Metric |
|---|---|---|---|---|
| OS | 26 | 144 | ~8 | Success Rate |
| DB | 60 | 300 | ~5 | Success Rate |
| KG | 20 | 150 | ~15 | F1 |
| DCG | 12 | 20 | ~30 | Win Rate |
| LTP | 20 | 50 | ~25 | Game Progress |
| HH | 20 | 50 | ~35 | Success Rate |
| WS | 80 | 200 | ~5 | Reward Score |
| WB | 31 | 100 | ~10 | Step Success Rate |
이제 각 환경을 자세히 살펴본다.
Code-grounded: OS, DB, KG
Operating System (OS)
Ubuntu Docker 컨테이너 안에서 bash shell을 통해 작업한다. task는 두 유형으로 나뉜다.
- QA: OS 관련 질문(예:
/home디렉토리가 없는 user 수)에 commit으로 답 - Operation: 실제 상태 변경(예: 디렉토리 권한 변경) — verifiable check script로 채점
action space는 임의의 valid bash command 전체. 즉 모델은 어떤 명령이라도 자유롭게 쓸 수 있다. 평가는 최종 상태가 정답 상태와 일치하는지를 본다.
Database (DB)
실제 MySQL 인스턴스를 띄우고, 자연어 질문에 SQL을 실행해 답하는 task. 예시:
“What was the total number of medals won by United States?” (Olympics 테이블)
action space는 SELECT/INSERT/UPDATE/DELETE까지 포함된 valid SQL. 모델은 여러 차례 쿼리를 시도하며 결과를 보고 최종 답을 commit한다.
Knowledge Graph (KG)
Freebase 기반의 거대 KG에서 multi-hop reasoning을 수행한다. KG는 너무 커서 전체를 컨텍스트에 넣을 수 없으므로, 모델은 다음과 같은 KG-querying 도구를 호출한다.
get_relations(entity)get_neighbors(entity, relation)intersection(entity_set_1, entity_set_2)get_attributes(entity)
예시:
“Find tropical cyclones that are similar to Hurricane Marie and affected Eastern North America.”
평가 metric은 F1 — 정답 entity 집합과 모델 답의 일치도. 평균 15라운드로 가장 긴 추론을 요구하는 환경 중 하나다.
Game-grounded: DCG, LTP, HH
Digital Card Game (DCG)
Aquawar라는 카드 게임에서 4마리 fish 팀을 조작해 알고리즘 기반 상대팀과 turn-based 대전한다. 모델은 캐릭터 선택과 스킬 사용을 결정한다. metric은 Win Rate.
Lateral Thinking Puzzles (LTP)
“바다거북 수프” 류 수수께끼다. 사회자(judge)에게 yes/no/irrelevant 질문을 던져 미스터리를 푼다. 예시:
“A man sleeps with the lights off, and the next morning he commits suicide after opening windows. Why?”
action space는 자연어 yes/no 질문. metric은 Game Progress(단계 진행 비율).
House-Holding (HH)
ALFWorld의 텍스트 환경. 가상 가정에서 텍스트 명령으로 task를 수행한다.
“Clean some soapbar and put it in countertop”
action은 go to, take, clean, heat, cool, put 등 정의된 집합. 평균 35라운드로 가장 긴 호흡이 필요하다.
Web-grounded: WS, WB
Web Shopping (WS)
WebShop(Princeton NLP)의 시뮬레이션 e-commerce 사이트. 자연어 요청에 맞는 상품을 검색·선택·구매한다.
“Queen-size bedspread, redwood color, under $70”
action은 search[query]와 click[element] 두 가지. metric은 Reward Score(속성 매칭 비율).
Web Browsing (WB)
Mind2Web(Ohio State NLP)에서 가져온 실제 다양한 웹사이트 task.
“Find the latest r/announcements post with 10k+ upvotes and upvote it”
action은 DOM element 대상의 click/select/type. metric은 Step Success Rate(element accuracy + action F1).
평가 프레임워크
Multi-turn Interaction 구조
AgentBench는 CoT + ReAct를 결합한 변형을 사용한다. ReAct(Yao et al., 2023)에서 영감을 받아 Thought:(reasoning)과 Action:을 한 라운드 안에 함께 출력하게 한다.
대화는 환경(User) ↔ 에이전트(Agent)의 chat history로 alternating된다. 각 라운드는 다음 형태다.
USER: [환경의 observation 또는 피드백]
AGENT: Thought: [추론]
Action: [도구 호출 또는 명령]
USER: [환경의 응답]
AGENT: Thought: ...
Action: ...
...
컨텍스트가 길어지면 가장 오래된 메시지부터 prune하여 항상 3,500 토큰 이하로 유지한다. 잘린 라운드 수는 모델에 통지한다. 추론은 모두 temperature = 0(greedy)으로 재현성을 확보한다.
5가지 종료 사유 (Finish Reasons)
평가의 진단성을 위해 매 trajectory의 종료 사유를 5가지로 분류한다.
| 사유 | 의미 |
|---|---|
| Complete | 정상 완료 |
| Context Limit Exceeded (CLE) | 컨텍스트 초과 |
| Invalid Format (IF) | 응답 포맷 위반 (Thought·Action 형식 미준수) |
| Invalid Action (IA) | 정의된 액션 외 호출 |
| Task Limit Exceeded (TLE) | 최대 라운드 내 미해결 |
이 분류는 단순히 “성공/실패”가 아니라 왜 실패했는지를 알려준다. 예를 들어 IF/IA가 많으면 instruction following이 약한 것이고, TLE가 많으면 장기 추론에 실패한 것이다.
Overall Score (OA) 계산
8개 환경의 metric이 모두 다르므로, 단순 평균으로는 비교가 어렵다. AgentBench는 다음 정규화를 쓴다.
- 각 task의 전체 모델 평균 점수가 1.0이 되도록 점수를 resize
- 정규화된 점수를 8개 task에 걸쳐 평균 → 모델별 OA
이 reciprocal-mean weight는 한번 계산되면 고정되어, 후속 연구가 동일한 weight로 재평가할 수 있다.
직관적으로 OA = 1.0이면 “8개 환경에서 평균적인 LLM 수준”, OA = 4.0이면 “평균 LLM의 4배 능력”이다.
Experiments
평가 모델 (27개 LLM)
논문은 총 27개 LLM을 평가했다 (이후 GitHub 버전은 29개로 확장).
API-based (상용): GPT-4, GPT-3.5-turbo, text-davinci-003, text-davinci-002, Claude-2, Claude (v1.3), Claude-instant, chat-bison-001 (PaLM), 이후 Claude-3·GLM-4 추가
Open-source (OSS):
| 규모 | 모델 |
|---|---|
| 70B | Llama-2-70B-chat, Guanaco-65B |
| 30B대 | CodeLlama-34B-Instruct, Vicuna-33B, WizardLM-30B, Guanaco-33B |
| 13B대 | Vicuna-13B (v1.5), Llama-2-13B-chat, OpenChat-13B, WizardLM-13B, CodeLlama-13B-Instruct, Koala-13B |
| 7B대 | Vicuna-7B, Llama-2-7B-chat, CodeLlama-7B-Instruct, CodeGeeX2-6B, ChatGLM-6B |
| 기타 | Dolly-12B, OASST-12B |
종합 점수 (OA)
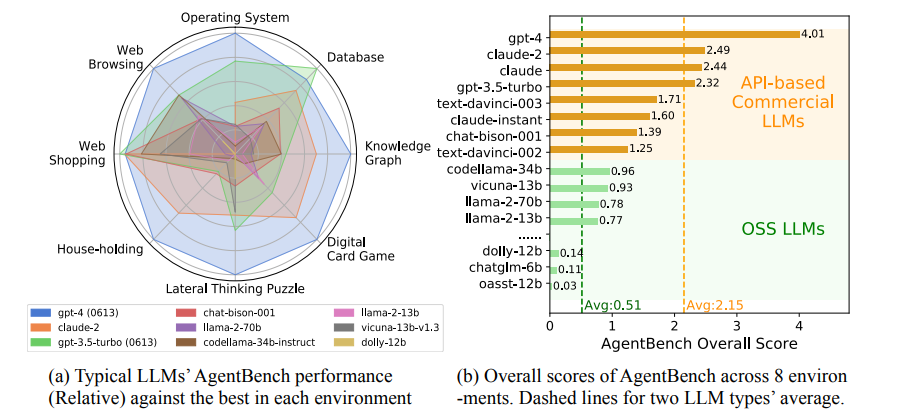
| Model | OA |
|---|---|
| GPT-4 | 4.01 |
| Claude-3 (Opus) | 3.11 |
| GLM-4 | 2.89 |
| Claude-2 | 2.49 |
| Claude (v1.3) | 2.44 |
| GPT-3.5-turbo | 2.32 |
| text-davinci-003 | 1.71 |
| CodeLlama-34B (best OSS) | 0.96 |
| Vicuna-13B (v1.5) | 0.93 |
| Llama-2-70B-chat | 0.78 |
| Llama-2-7B-chat | 0.34 |
| ChatGLM-6B | 0.11 |
| OASST-12B | 0.03 |
핵심 관찰은 다음과 같다.
- GPT-4는 압도적 1위(4.01)다. 최고 오픈소스(CodeLlama-34B, 0.96)와 약 4.2배 격차.
- API 평균 OA(약 2.32) vs OSS 평균 OA(약 0.51)도 4.5배 차이.
- 그러나 GPT-4조차 환경별로 편차가 크다 — 어떤 환경에서도 80%를 넘지 못한다.
환경별 최강 / 최약
| 환경 | Best | Worst |
|---|---|---|
| OS | GPT-4 (42.4%) | OASST (1.4%) |
| DB | GPT-3.5-turbo (36.7%) | Dolly/ChatGLM (0%) |
| KG | GPT-4 (58.8%) | Guanaco-65B (1.9%) |
| DCG | GPT-4 (74.5%) | 다수 (0%) |
| LTP | Llama-2-13B (26.4%) | 다수 (0%) |
| HH | GPT-4 (78.0%) | Dolly (0%) |
| WS | Claude-2 / text-davinci-003 (61.7%) | 다수 (0%) |
| WB | Llama-2-13B (27.0%) | 다수 (0–4%) |
흥미로운 점은 WB(Web Browsing)와 LTP에서 Llama-2-13B가 GPT-4를 능가한다는 것이다. 저자는 Mind2Web 데이터의 element 선택 prior가 일부 OSS 모델에 우호적일 수 있다고 해석한다.
주요 발견 (Findings)
1. GPT-4도 실용 임계선 아래
GPT-4가 1위이긴 하지만 OA 4.01은 “실제 production에 안정적으로 쓸 수 있는 수준”과 거리가 멀다. 저자는 다음과 같이 표현한다.
“Strong ability of acting as agents in complex environments, but still far from practical usability.”
2. Task Limit Exceeded가 지배적 실패
종료 사유를 분석하면 TLE(Task Limit Exceeded)가 압도적이다. 특히 KG에서는 평균 67.9%의 trajectory가 TLE로 종료된다. 저자의 결론은 명확하다.
“Poor long-term reasoning, decision-making, and instruction following abilities are the main obstacles for developing usable LLM agents.”
agent의 한계는 “한 번에 답을 못 함”이 아니라 장기 추론을 유지하지 못함이다.
3. Code-tuning은 양면 칼날
CodeLlama 시리즈 같은 code-tuned 모델은:
- 절차적 task (WS, OS, DB)에서 향상
- 전략적 추론 task (DCG)에서는 일반 모델보다 손해
저자는 흥미로운 가설을 제시한다.
“Code tuning might deeply influence a model’s way of inferential generation and thinking, even beyond topics just about coding.”
코드 학습이 단순히 “코드를 잘 짜게” 만드는 것이 아니라 추론 방식 자체를 바꾼다는 것이다. 절차적 task에는 유리하지만, 카드 게임 같은 전략적 사고에는 불리할 수 있다.
4. 고품질 alignment data의 중요성
Vicuna-13B(GPT-4/3.5의 ShareGPT 데이터로 튜닝)가 Llama-2-13B를 압도하고, 3배 큰 CodeLlama-34B와 비슷한 OA를 기록했다. 이는 단순히 “더 큰 모델”이 답이 아니라는 점을 시사한다.
“High-quality alignment is still a key to develop better LLM agents.”
5. 모델 크기 스케일링의 한계
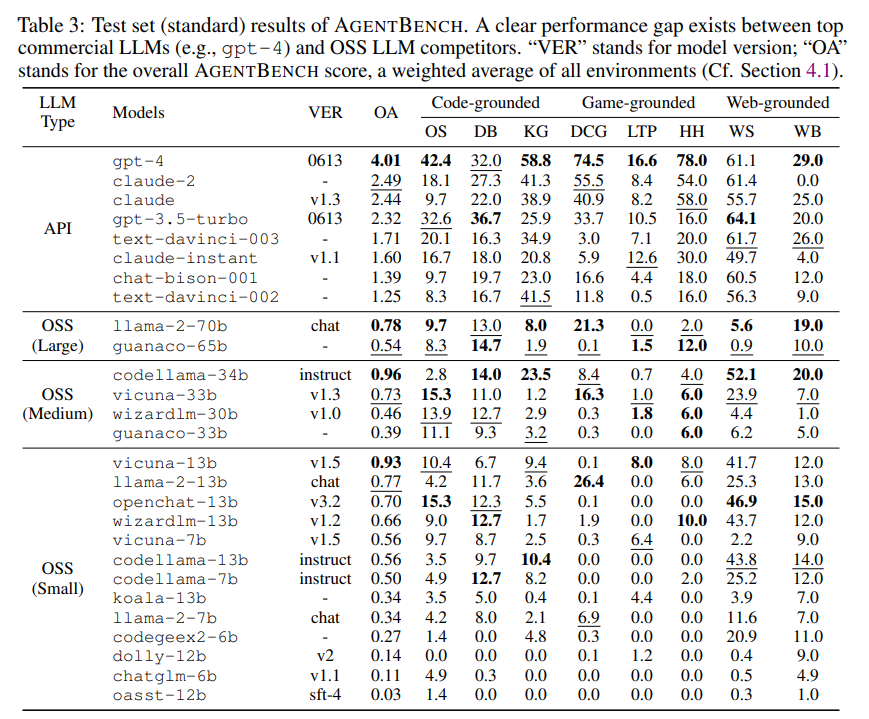
Llama-2-13B와 Llama-2-70B의 OA가 거의 유사하다. agent 능력은 단순한 파라미터 스케일링으로 자동 향상되지 않는다. 사전학습 코퍼스와 alignment 품질이 더 중요할 수 있다.
6. Long context의 영향은 제한적
CLE(컨텍스트 초과)는 대부분 task에서 0~3.5%에 그친다. 주로 text-davinci-002/003 같은 2,048 토큰 한계 모델에서만 두드러진다. 즉 컨텍스트 길이는 핵심 병목이 아니다 — 추론 능력 자체가 문제다.
7. Format 오류는 OSS의 고질병
Invalid Format(IF)이 DB·DCG처럼 엄격한 포맷을 요구하는 task에서 OSS 모델에 빈번하다. instruction following이 약한 모델은 agent로 쓰기 어렵다.
Discussion
저자가 인정한 한계
- 종합적 진단의 어려움: 실패는 여러 원인이 겹쳐서 발생하므로 단일 원인을 짚어내기 어렵다.
- Sampling 다양성 미평가: T=0으로 통제했지만 sampling을 켰을 때의 분포는 측정하지 못했다.
- 부분 평가의 한계: LTP·DCG는 자동 평가의 한계로 부분 진행도(progress)만 측정한다.
- 평가 비용: 모델당 약 11k inference call이 필요하다.
- 단순 prompting: 1-shot CoT만 사용했다. ReAct full, Reflexion 등 정교한 prompting은 future work.
후속 연구가 보강한 부분
AgentBench 이후 같은 팀과 외부 연구자들이 한계를 보강했다.
- VisualAgentBench (2024.08): multimodal LMM(Large Multimodal Model)으로 확장
- AgentBench FC (2025.10): function-calling 스타일 prompt + 완전 Docker 컨테이너화, AgentRL과 통합
- WebArena, OSWorld, SWE-bench 등 단일 도메인 심화 벤치마크들이 AgentBench의 환경별 한계를 깊게 파고 들었다
Conclusion
AgentBench는 “LLM as agent”라는 평가 패러다임 자체를 정착시킨 작품이다. 핵심 기여를 다시 정리하면:
- 종합 평가의 출발점: 8환경 multi-turn 평가의 표준 구조를 만들었다. 이후 거의 모든 agent 벤치마크가 이를 차용한다.
- API vs OSS 격차의 정량화: 4-5배 격차를 수치로 보여줘 오픈소스 진영의 catch-up 동기를 제공했다.
- 장기 추론의 중요성 발견: TLE 분석을 통해 “context length가 아니라 reasoning depth”가 진짜 병목임을 보였다.
- 고품질 alignment의 가치: Vicuna-13B 사례로 데이터 품질이 모델 크기보다 중요할 수 있음을 입증했다.
AgentBench가 던진 질문 — “어떻게 LLM을 agent로 평가할 것인가” — 는 지금도 유효하다. GAIA, SWE-bench, TravelPlanner, OSWorld 같은 후속 벤치마크들은 모두 AgentBench가 제시한 좌표 위에서 더 깊이 또는 더 넓게 측정한다.
이어서 읽기: GAIA: General AI Assistant 벤치마크, TelAgentBench: 통신 도메인 LLM 에이전트 평가
참고 문헌
- AgentBench: Evaluating LLMs as Agents (arXiv 2308.03688) — Liu et al., ICLR 2024
- AgentBench GitHub Repo
- 공식 사이트 llmbench.ai
- ICLR 2024 Paper Page
- HuggingFace Paper Page
- ReAct: Synergizing Reasoning and Acting in Language Models — Yao et al., ICLR 2023
- WebShop — Yao et al., NeurIPS 2022
- ALFWorld — Shridhar et al., ICLR 2021
- Mind2Web — Deng et al., NeurIPS 2023
Enjoy Reading This Article?
Here are some more articles you might like to read next: