CodeAttack: Code-based Adversarial Attacks for Pre-trained Programming Language Models
CodeAttack: Code-based Adversarial Attacks for Pre-trained Programming Language Models (Jha & Reddy, Virginia Tech, AAAI 2023)
Introduction
CodeBERT, GraphCodeBERT, CodeT5 같은 사전학습 프로그래밍 언어(PL) 모델은 코드 번역, 버그 수정, 코드 요약 같은 소프트웨어 엔지니어링 작업을 자동화한다. 이 모델들은 수억 줄의 코드로 훈련돼 놀라운 성능을 보인다.
그런데 이 모델들은 한 가지 근본적인 특성 위에 서 있다. 코드를 사람이 이해하는 방식대로 처리한다는 것이다. 변수명, 함수명, 주석 같은 자연 채널(natural channel)에 강하게 의존한다.
Jha & Reddy(2023)는 바로 이 특성을 공략한다. CodeAttack은 코드의 자연 채널에서 최솟값의 변경만으로 SOTA PL 모델의 성능을 크게 떨어뜨리는 블랙박스 적대 공격이다.

위 그림을 보면, getQueryString → getQuery로 함수명 하나만 바꾸었을 뿐인데 코드 요약 결과가 “Get the query string from the request.”에서 “die Query - Query - Query - Query”로 완전히 망가진다. 사람이 보기엔 거의 같은 코드지만, 모델은 전혀 다른 출력을 낸다.
| 방법 | 특성 | 결과 |
|---|---|---|
| TextFooler | NLP 용 동의어 치환 | 키워드를 audiences, canceling 등으로 교체 → 코드 불일치 |
| BERT-Attack | BERT 기반 무작위 치환 | ;, . 같은 기호 삽입 → 문법 파괴 |
| CodeAttack | 코드 구조 인식 치환 | byte → bytes 수준 → 눈에 안 띄고 효과적 |
Background
코드의 이중 채널 (Dual Channel)
Casalnuovo et al.(2020)이 제안한 개념으로, 소스 코드는 두 가지 채널을 동시에 가진다:
| 채널 | 대상 | 역할 |
|---|---|---|
| 형식 채널 (formal) | 컴파일러/인터프리터 | 정확한 실행 의미(semantics) 전달 |
| 자연 채널 (natural) | 사람 | 변수명, 함수명, 주석으로 의도 전달 |
PL 모델들은 자연 채널에서 동작한다. 대용량 코드 데이터로 훈련되면서 변수명과 함수명의 패턴을 학습하지만, 이것은 컴파일러처럼 엄밀한 구문 분석이 아니다. 이 간극이 공격의 문을 연다.
PL 모델의 취약성
NLP 모델에서 적대 공격은 잘 알려진 문제다. TextFooler, BERT-Attack 등이 텍스트 분류기를 공략한다. 그런데 코드는 자연어보다 훨씬 구조적이다. NLP 공격 방법을 그대로 쓰면 코드 문법이 깨지거나(BERT-Attack), 코드답지 않은 단어가 삽입된다(TextFooler). 코드 특화 공격이 필요한 이유다.
Method: CodeAttack
위협 모델
공격자의 능력: 입력 코드 시퀀스를 수정할 수 있다. 단, 모델 파라미터, 아키텍처, 그래디언트, 학습 데이터는 볼 수 없다. 오직 입력을 넣고 출력 확률을 받는 블랙박스 접근만 가능하다.
공격자의 목표: 최솟값의 변경으로 모델 출력 품질을 최대한 떨어뜨린다. 적대 코드 \(X_{adv}\)는 다음 조건을 모두 만족해야 한다:
\[X_{adv} \neq X, \quad X_{adv} = X + \delta \text{ s.t. } \|\delta\| < \theta, \quad \text{Sim}(X_{adv}, X) \geq \epsilon\]그리고 출력 품질 감소를 최대화한다:
\[\Delta_{atk} = \arg\max_{\delta} \left[ Q(F(X)) - Q(F(X_{adv})) \right]\]여기서 \(Q(\cdot)\)는 CodeBLEU(코드 작업) 또는 BLEU(요약 작업)로 측정한다.
알고리즘 개요
CodeAttack은 두 단계로 구성된다.
Step 1: 취약 토큰 탐색 (Finding Vulnerable Tokens)
코드 중 어떤 토큰을 바꿔야 효과가 가장 클까? 모델이 예측할 때 강하게 의존하는 토큰을 찾는다.
토큰 \(x_i\)를 [MASK]로 치환한 뒤 출력 로짓 변화를 측정한다:
\(o_t\)는 원본 입력의 올바른 출력 토큰 \(y_t\)에 대한 로짓, \(o'_t\)는 마스킹 후 로짓이다. \(I_{x_i}\)가 클수록 이 토큰이 모델 예측에 영향을 크게 미치는 취약 토큰이다.
취약 토큰들을 \(I_{x_i}\) 내림차순으로 정렬해 상위 \(k\)개를 선택한다.
Step 2: 취약 토큰 치환 (Substituting Vulnerable Tokens)
마스킹된 CodeBERT로 대체 후보를 생성한 뒤, 코드 특화 제약(code-specific constraints)으로 필터링한다.
코드 토큰은 4가지 클래스로 분류된다:
| 클래스 | 종류 |
|---|---|
| Keywords | 예약어 (if, for, class, …) |
| Identifiers | 변수명, 클래스명, 메서드명 |
| Operators | 괄호({}, (), []), 기호(+, *, ;, ., …) |
| Arguments | 정수, 실수, 문자열, 문자 리터럴 |
제약 1: 치환 토큰 클래스가 원본과 같아야 한다.
\[C(v_i) = C(s_i) \quad \text{and} \quad |C(v_i)| = |C(s_i)|\]식별자(Identifier)는 식별자로만, 키워드는 키워드로만 교체한다.
제약 2: 연산자 개수 변화는 최대 ±1개만 허용한다.
\[|Op(v_i)| - 1 \leq |Op(s_i)| \leq |Op(v_i)| + 1\]이 두 제약이 코드 일관성(code consistency)과 코드 유창성(code fluency)을 보장한다. 최대 40%의 토큰만 변경하고, 원본과의 코사인 유사도 임계값(0.5)을 유지한다.
Algorithm 1: CodeAttack 전체 흐름
입력: 코드 X, 피해자 모델 F, 최대 섭동 θ, 유사도 ε, 성능 하락 목표 ϕ
출력: 적대 코드 Xadv
Xadv ← X
// Step 1: 취약 토큰 탐색
for xi in X:
Ixi 계산 (Eq. 7)
V ← 영향 점수 내림차순 정렬
// Step 2: 치환
for vi in V:
S ← Filter(vi, 코드 제약 Eq. 8, 9)
for sj in S:
Xadv = [..., sj, ...]
if Q(F(X)) - Q(F(Xadv)) ≥ ϕ and Sim(X, Xadv) ≥ ε:
return Xadv // 성공
Xadv ← [최선의 단일 치환 적용]
return Xadv
Experiments
실험 설정
- 다운스트림 태스크: 코드 번역(C# ↔ Java), 코드 수정(Java), 코드 요약(Python/Java/PHP)
- 피해자 모델: CodeT5, CodeBERT, GraphCodeBERT, RoBERTa
- 베이스라인: TextFooler, BERT-Attack
- 지표: \(\Delta_{drop}\) (CodeBLEU/BLEU 감소량), Success%, #Queries, #Perturbation, CodeBLEUq
메인 결과 (Table 2)
코드 번역 (C# → Java):
| 피해자 모델 | 방법 | Before | After | Δdrop | Success% | #Queries | #Perturb |
|---|---|---|---|---|---|---|---|
| CodeT5 | TextFooler | 73.99 | 68.08 | 5.91 | 28.3% | 94.95 | 2.90 |
| BERT-Attack | 73.99 | 63.01 | 10.98 | 75.8% | 163.5 | 5.28 | |
| CodeAttack | 73.99 | 61.72 | 12.27 | 89.3% | 36.84 | 2.55 | |
| CodeBERT | TextFooler | 71.16 | 60.45 | 10.71 | 49.2% | 73.91 | 1.74 |
| BERT-Attack | 71.16 | 58.80 | 12.36 | 70.1% | 290.1 | 5.88 | |
| CodeAttack | 71.16 | 54.14 | 17.03 | 97.7% | 26.43 | 1.68 | |
| GraphCodeBERT | TextFooler | 66.80 | 46.51 | 20.29 | 38.7% | 83.17 | 1.82 |
| BERT-Attack | 66.80 | 36.54 | 30.26 | 94.3% | 175.8 | 6.73 | |
| CodeAttack | 66.80 | 38.81 | 27.99 | 98.0% | 20.60 | 1.64 |
코드 수정 (Java → Java):
CodeAttack은 세 모델 모두에서 99%+ 성공률을 달성했으며, 평균 1.6~2.1개 토큰 변경만으로 충분했다.
코드 요약 (PHP → NL):
| 피해자 모델 | 방법 | Before (BLEU) | After (BLEU) | Δdrop | Success% |
|---|---|---|---|---|---|
| CodeT5 | TextFooler | 20.06 | 14.96 | 5.70 | 64.6% |
| BERT-Attack | 20.06 | 11.96 | 8.70 | 78.4% | |
| CodeAttack | 20.06 | 11.06 | 9.59 | 82.8% | |
| CodeBERT | CodeAttack | 19.76 | 10.88 | 8.87 | 88.3% |
| RoBERTa | CodeAttack | 19.06 | 10.98 | 8.08 | 87.5% |
요약 태스크에서 BLEU 점수가 약 50% 감소했다. byte → bytes 수준의 식별자 하나 바꾸었을 뿐인데.
핵심 관찰:
- CodeAttack은 9개 중 6개 케이스에서 베이스라인을 능가
- BERT-Attack이 일부 케이스에서 \(\Delta_{drop}\)이 높지만 쿼리 수가 10배 이상 필요 (163→26, 290→26)
- CodeAttack은 평균 1~3개 토큰만 바꾸고도 고성공률 달성
- GraphCodeBERT가 가장 취약 — 데이터 플로우 그래프에서 식별자 관계를 학습하기 때문에, 식별자 변경이 치명적
공격 품질: 구문 정확성
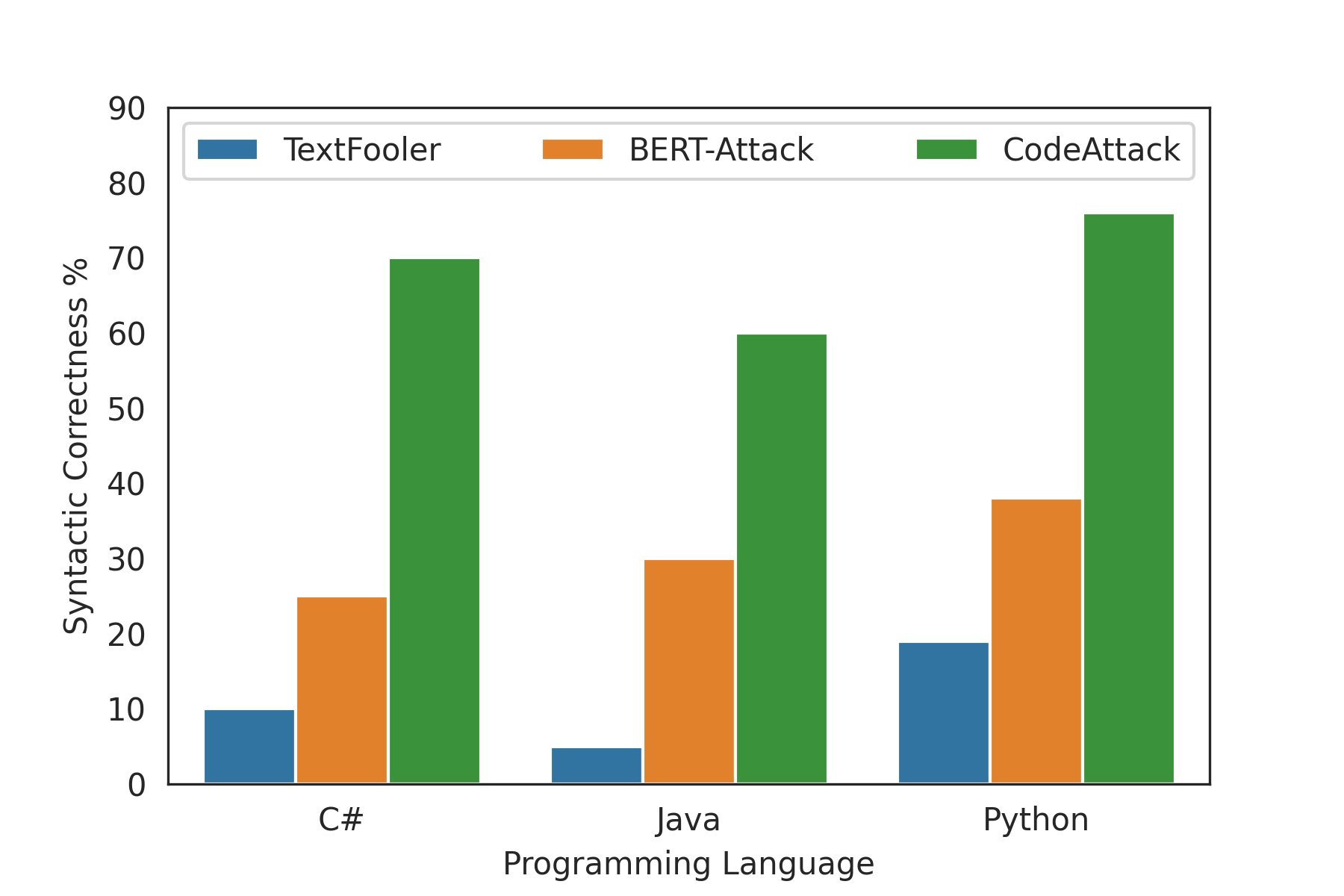
3명의 인간 평가자가 적대 코드의 구문 정확성을 수동으로 검증했다:
| 언어 | TextFooler | BERT-Attack | CodeAttack |
|---|---|---|---|
| C# | ~10% | ~25% | 70% |
| Java | ~5% | ~30% | 60% |
| Python | ~19% | ~38% | 76% |
CodeAttack의 적대 코드는 사람이 봐도 문법적으로 자연스럽다. TextFooler는 코드 키워드를 자연어 동의어로 바꾸고(public → audiences), BERT-Attack은 기호를 무작위로 삽입한다. 반면 CodeAttack은 같은 클래스의 코드 토큰으로만 교체한다.
인간 평가 결과:
- 적대 코드의 72.1%가 인간에게 원본으로 오인됨
- 적대 코드 이해도 평균 4.14/5 (1=전혀 못 읽음, 5=완전히 이해)
- 원본-적대 코드 일관성 평균 0.71/1.0
사람은 거의 구분하지 못하지만 모델은 완전히 속는다.
Ablation: 구성요소별 기여
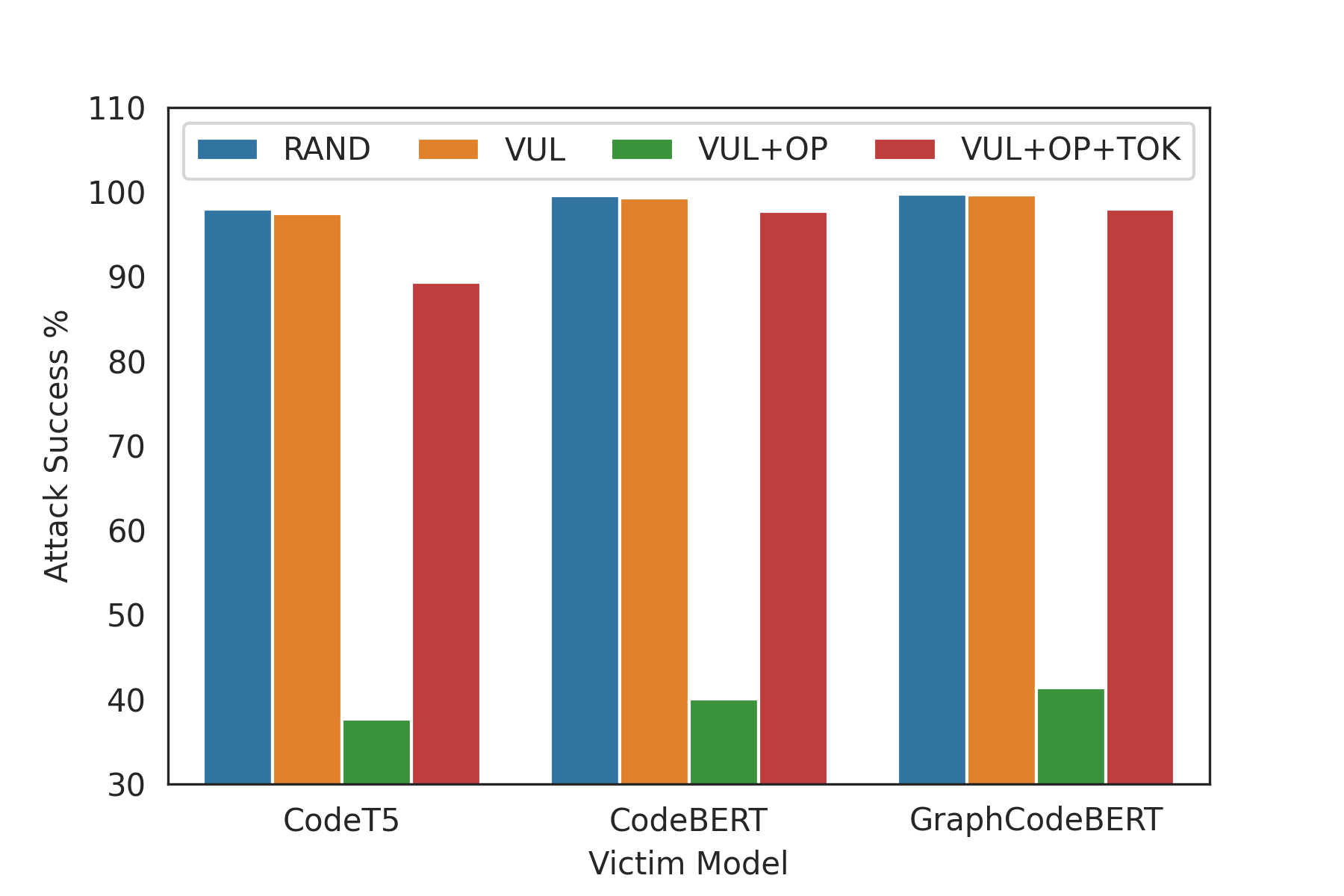
4가지 변형을 비교한 코드 번역(C#→Java) 결과:
| 변형 | 설명 | 특징 |
|---|---|---|
| RAND | 무작위 토큰 치환 | 취약 토큰 탐색 없음 |
| VUL | 취약 토큰 + 제약 없음 | 코드 클래스 무시 |
| VUL+OP | 취약 토큰 + 연산자 제약만 | 변경 범위 매우 제한 |
| VUL+OP+TOK | 취약 토큰 + 두 제약 | CodeAttack 최종 모델 |
- RAND와 VUL은 성공률은 높지만 적대 코드 품질(CodeBLEUq)이 낮음
- VUL+OP는 성공률이 40%대로 급락 — 연산자만 바꾸는 건 변화가 너무 미미
- VUL+OP+TOK가 성공률과 코드 품질의 최선의 트레이드오프
Conclusion
CodeAttack은 두 가지 핵심을 보여준다.
-
PL 모델의 자연 채널 의존성이 취약점이다: 코드를 “자연어처럼” 이해하는 모델들은 코드 의미(semantics)가 아닌 자연 채널(변수명 패턴 등)에서 속는다. 실행하거나 컴파일해서 검증하지 않는 이상, 식별자 하나만 바꿔도 모델이 무너진다.
-
코드 특화 제약이 공격을 더 강하게 만든다: NLP 공격 방법을 코드에 그대로 쓰면 코드가 망가진다. CodeAttack처럼 코드 토큰 클래스와 연산자 제약을 지키면, 사람이 보기에 자연스러우면서도 더 효과적인 적대 예제를 만들 수 있다.
한계점:
- 블랙박스이지만 출력 로짓에 접근 가능해야 함 (순수 API 접근보다는 조건이 있음)
- 코드 요약에서 쿼리 수가 300~1912로 번역/수정보다 많이 필요
- 컴파일/실행 검증을 추가하면 방어 가능 → 모델 추론 파이프라인에 정적 분석 통합이 대안
- 자연 채널 공격이므로 형식 채널(실행 의미)에는 영향 없음
참고 문헌
- CodeAttack: Code-based Adversarial Attacks for Pre-trained Programming Language Models (Jha & Reddy, AAAI 2023)
- GitHub: reddy-lab-code-research/CodeAttack
- CodeBERT: A Pre-Trained Model for Programming and Natural Languages (Feng et al., 2020)
- CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models (Wang et al., 2021)
- GraphCodeBERT: Pre-training Code Representations with Data Flow (Guo et al., 2020)
- TextFooler (Jin et al., 2020)
Enjoy Reading This Article?
Here are some more articles you might like to read next: