TelAgentBench: A Multi-faceted Benchmark for Evaluating LLM-based Agents in Telecommunications
TelAgentBench: A Multi-faceted Benchmark for Evaluating LLM-based Agents in Telecommunications (EMNLP 2025 Industry Track)
Introduction
LLM의 역량이 다양해지면서, 자율 에이전트로의 활용이 빠르게 확산되고 있다. Toolformer(Schick et al., 2023), ReAct(Yao et al., 2023), MRKL(Karpas et al., 2022) 등의 프레임워크는 LLM에게 Action, Reasoning, RAG(Retrieval-Augmented Generation) 등의 핵심 에이전트 역량을 부여했다.
통신 산업은 전통적인 이동통신 사업자(MNO)를 넘어, 생활 밀착형 서비스까지 통합하는 방향으로 확장 중이다. 예를 들어, 로밍 고객의 전체 여행 일정을 생성하거나(항공편 예약부터 레스토랑 예약까지), 대화를 요약하는 서비스가 등장하고 있다. 이러한 복잡성은 견고한 AI 기반 고객 서비스 솔루션을 필요로 하며, 현대의 에이전트 LLM은 이를 위한 기반 기술로 부상하고 있다.
그러나 기존 벤치마크에는 두 가지 근본적 한계가 있다.
- 범용 벤치마크의 도메인 부적합: 기존 에이전트 벤치마크(BFC, BiGGen Bench, MMAU 등)는 도메인 특화 환경을 반영하지 못한다.
- 비영어권 평가의 부재: 대부분의 벤치마크가 영어 중심이며, 한국어와 같은 비영어 환경에서의 현실적 성능을 평가하지 못한다.
저자는 이를 해결하기 위해 TelAgentBench를 제안한다. TelAgentBench는 통신 도메인의 5가지 핵심 에이전트 역량을 평가하는 한국어 벤치마크다.
이 논문의 주요 기여는 다음과 같다.
- 통신 서비스를 위한 다면적 에이전트 벤치마크: Reasoning, Planning, Action(tool-use), RAG, Instruction Following의 5가지 핵심 역량을 식별하고, 1,700개 이상의 인스턴스로 구성된 벤치마크를 구축했다.
- 프라이버시와 한국어 맥락을 위한 합성 벤치마크: 개인정보 위험을 완화하면서 평가의 현실성을 확보하기 위해 합성 데이터를 생성했다. 한국어 언어적 맥락에서의 성능 평가 필요성을 반영하여 한국 최초의 통신 도메인 벤치마크를 구축했다.
- 15개 주요 LLM의 다면적 성능 분석: thinking(명시적 추론) 모델과 non-thinking 모델 간의 유의미한 성능 격차를 발견하여, 복잡한 에이전트 태스크에서 명시적 추론의 중요성을 실증적으로 입증했다.
Related Work
에이전트 LLM 평가는 단순한 NLP 태스크에서 더 복잡한 에이전트 기술 평가로 진화해왔다. 초기에는 지식 검색과 의도 분류 같은 기본 NLP 태스크에 집중했으나, 에이전트적 역량의 발전에 따라 function calling(BFC, Year et al., 2024), instruction following(IFEval, Zhou et al., 2023), planning(TravelPlanner, Xie et al., 2024), retrieval(RAGAS, Es et al., 2025), multi-step reasoning(HotpotQA, Yang et al., 2018; StrategyQA, Geva et al., 2021) 등 세분화된 벤치마크가 등장했다.
BigGen Bench(Kim et al., 2025)와 같은 종합 벤치마크도 있지만, 대부분의 평가가 도메인에 무관(domain-agnostic)하고 특정 산업 환경에 기반하지 않는다. 의료(MedAgentBench, Jiang et al., 2025)와 법률(LegalAgentBench, Li et al., 2024) 분야에서는 도메인 특화 벤치마크가 등장했지만, 구축에 상당한 도메인 전문성과 리소스가 필요하여 여전히 희소하다.
통신 분야에서는 TeleQnA(Maatouk et al., 2024)가 기본 역량(e.g., intent classification)을 평가하지만 에이전트적 평가에는 미치지 못하며, 선행 연구인 TelBench(Lee et al., 2024)가 워크플로우를 통한 에이전트 역량의 초기 탐색을 제시했다. TelAgentBench는 이를 확장하여 체계적인 에이전트 평가 프레임워크를 제공한다.
TelAgentBench Dataset Construction
전체 구조
TelAgentBench는 비즈니스 요구사항 관찰을 기반으로, 산업 현장에서의 평가를 촉진하기 위해 5가지 핵심 에이전트 역량을 식별하고 벤치마크를 구축했다. 이 5가지 역량은 실세계 에이전트 배포의 전체 파이프라인을 포괄한다: 초기 추론과 계획(Reasoning, Planning)부터 도구 지원 행동과 검색 기반 근거 확보(Action, RAG), 그리고 사용자 제약 준수(Instruction Following)까지.
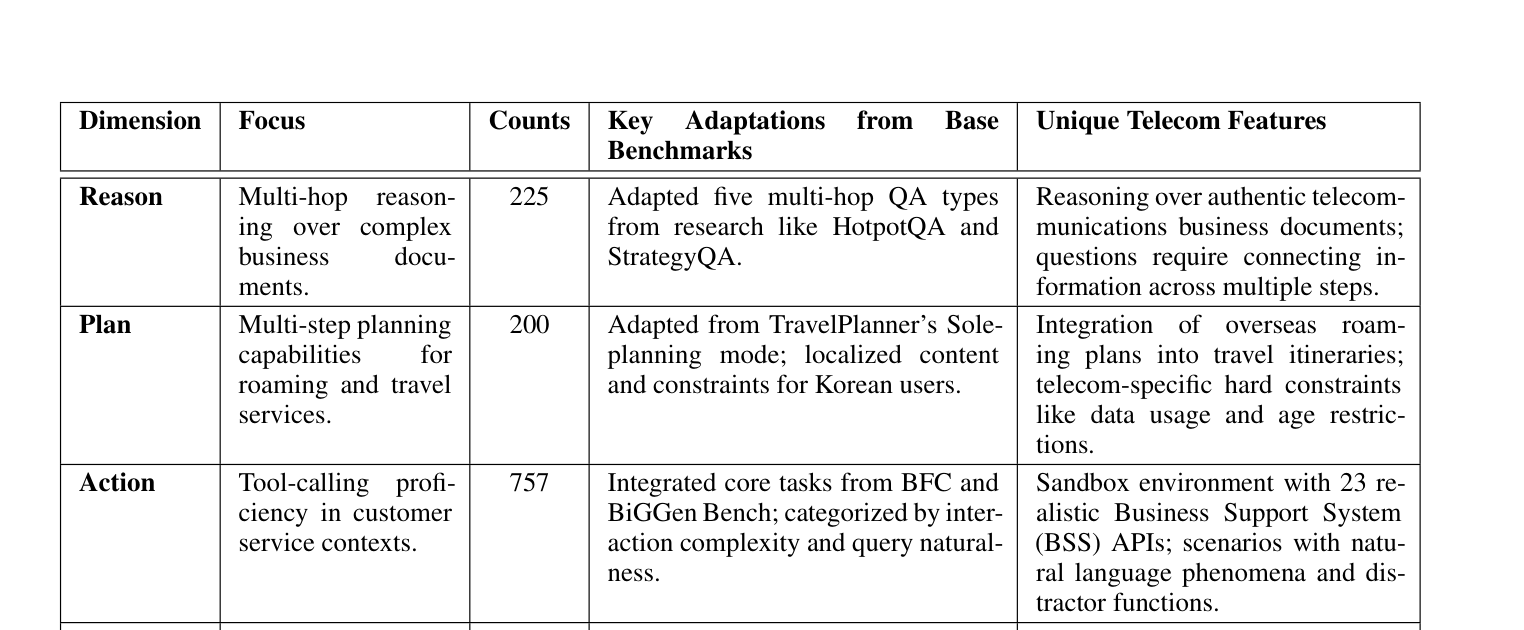
| Dimension | Focus | Counts | Base Benchmarks | 통신 도메인 특화 요소 |
|---|---|---|---|---|
| Reason | 복잡한 비즈니스 문서에 대한 multi-hop 추론 | 225 | HotpotQA, StrategyQA | 실제 통신 비즈니스 문서 기반, 다단계 정보 연결 필요 |
| Plan | 로밍/여행 서비스의 multi-step 계획 | 200 | TravelPlanner | 해외 로밍 계획을 여행 일정에 통합, 데이터 사용량/연령 제한 등 통신 특화 제약 |
| Action | 고객 서비스 맥락의 tool-calling 능력 | 757 | BFC, BiGGen Bench | 23개 BSS API의 샌드박스 환경, 자연어 현상과 방해 함수 포함 |
| RAG | 지식 기반의 검색 증강 생성 품질 | 258 | RAGAS | 비즈니스 문서 기반 생성, 방해(distractor) 문서로 검색 정밀도 테스트 |
| IF | 한국어 언어적 뉘앙스를 포함한 지시 따르기 | 300 | IFEval, Multi-IF | 통신 특화 지시(마크다운 테이블 포맷, 민감정보 처리 등), 한국어 경어체 |
4단계 데이터 구축 프로세스
TelAgentBench는 일관된 4단계 방법론으로 5개 하위 데이터셋을 구축했다. 이 설계 원칙은 통신 서비스 맥락에 특화되어 있지만, 다른 도메인으로의 적용과 확장도 가능하도록 설계되었다.
Step 1: Planning and Foundational Design
실세계 통신 서비스 사용 사례를 분석하여 평가 시나리오를 설계한다. 요금제 변경/신청, 로밍 혜택 문의, 요금 상담 등 핵심 고객 서비스 업무를 식별하고, BFC, TravelPlanner 등 기존 범용 벤치마크를 통신 도메인의 비즈니스 워크플로우, 규정, 데이터 제약에 맞게 적응시켰다.
Step 2: Building a Domain-Specific Environment
도메인 특화 환경을 구축한다.
- 도구 실행 환경: 핵심 고객 서비스 태스크(조회, 신청, 변경 등)를 분석하여 대표 API 목록을 도출하고, 입출력 사양과 호출 제약을 정의. API 호출이 상태 일관성을 유지하도록 가상 고객 정보, 요금제, 사용량 데이터를 포함한 시뮬레이션 DB를 구축
- 지식 검색 환경: 약관, 제품 매뉴얼, FAQ 등 비즈니스 문서를 수집하고 정제하여 시맨틱 단위로 분절, 검색 가능한 knowledge base를 구축. 해외 로밍 서비스 지원을 위해 여행 관련 데이터(레스토랑, 숙소 등)도 크롤링하여 DB에 통합
Step 3: Initial Data Generation and Expansion
소수의 고품질 시드 인스턴스를 언어학자(linguists)가 작성하고, 이를 체계적으로 확장한다. 패러프레이징, 질문 다양화, 템플릿 다양화, 생성 모델 활용을 통해 볼륨과 표현 다양성을 증가시킨다. 이 확장 과정에서 발생할 수 있는 모호성이나 중복을 방지하기 위해 교차 검토(cross review)를 수행한다.
Step 4: Expert Validation and Refinement
최종 단계는 HITL(Human-in-the-Loop) 절차를 통한 전문가 검증과 정제다. 통신 서비스 에이전트와 언어 전문가가 웹 기반 검증 도구를 통해 모든 인스턴스를 검토하고 검증한다. 검증 항목은 다음과 같다:
- Realism (현실성): 실세계 업무에 대한 적합성
- Accuracy (정확성): 사실적, 수치적, 정책적 정확성
- Reproducibility (재현성): 자동화된 채점의 실현 가능성
5가지 평가 차원 상세
1. TelAgent Reason (225건)
통신 정책 문서에 대한 multi-hop 추론 능력을 평가한다. 핵심 태스크는 복잡한 질문에 대해 여러 정보를 종합하고 연결하여 정답을 도출하는 것이다. 기존의 HotpotQA와 StrategyQA에서 5가지 multi-hop QA 유형을 통신 도메인에 적응시켰다.
| 유형 | 설명 | 예시 |
|---|---|---|
| Bridge | 한 문서의 답이 다른 문서의 질문이 되는 연쇄 추론 | “인터넷 전화 서비스와 번들로 제공되는 단말기의 가격은?” |
| Intersection | 여러 조건을 동시에 만족하는 답을 찾는 교차 추론 | “단말기 보조금과 무료 설치를 모두 제공하는 요금제는?” |
| Factuality | 사실 여부를 확인하는 검증 추론 | “유선전화 가입 시 모든 혜택을 동시에 받을 수 있는가?” |
| Superlative & Comparative | 비교/최상급 판단 | “T-로밍 요금제 중 GB당 가장 저렴한 것은?” |
| Procedural Arithmetic | 절차적 계산이 필요한 산술 추론 | “80,000원 요금제에 2년 약정 할인과 온라인 가입 할인을 모두 적용하면?” |
데이터는 단일 문서(100건)와 복수 문서(125건) 태스크로 구성되며, 각 질문은 2-4개의 추론 단계(hops)를 필요로 한다. 각 샘플은 질문, 정답, 중간 추론 단계(hops)를 포함한다.
2. TelAgent Plan (200건)
통신 맥락에서의 multi-step 계획 능력을 평가한다. TravelPlanner의 Sole-planning 모드와 Direct 전략을 적응시켜, 해외 로밍 계획을 여행 일정에 통합하는 시나리오를 구성했다.
TravelPlanner의 환경 제약은 유지하되, 통신 특화 하드 제약(hard constraints)을 커스터마이징했다:
- 데이터 사용량: 최대 로밍 허용량
- 가족 공유: 로밍 데이터 공유 자격
- 로밍 예산: 요금제 가격 상한
- 연령 제한: 청소년 전용 요금제 자격
난이도는 제약 조건의 수로 결정되며, 3단계(Easy/Medium/Hard)와 3가지 여행 기간(3일/5일/7일)으로 구성된다.
Easy 예시: “서울에서 마닐라로 3일 2박 혼자 여행. 하루 2GB 데이터 필요. 예산 200만원.”
Hard 예시: “파리와 에딘버러 더블 데이트 여행, 4명, 7일 6박. 파리 3박 에딘버러 3박. 루브르, 에딘버러 성 등 방문. 부티크 호텔, 반려동물 불가. 예산 1,500만원. 6만원대 청소년 로밍 요금제 추천.”
환경 DB는 7,801개 엔트리로 구성된다: FlightSearch(2,397), RestaurantSearch(1,412), AttractionSearch(936), AccommodationSearch(579), distanceMatrix(2,397), CitySet(50), RoamingPlan(30).
3. TelAgent Action (757건)
통신 고객 서비스에서의 function-calling(도구 호출) 능력을 평가한다. 기존 BFC와 BiGGen Bench를 통신 시나리오에 적응시켰다.
현실적인 평가 환경을 위해, 23개 BSS(Business Support System) API를 포함한 샌드박스 환경을 개발했다. API는 6개 카테고리로 나뉜다:
- Billing: 실시간 요금 조회
- Add-on Services: 로밍 가입/해지
- Data/Coupons: 데이터 한도 조회
- Rate Plans: 상품 정보 조회
- Family Information: 가족 데이터 사용량 조회
- Miscellaneous: 개인 정보 조회
이를 기반으로 10개 서브 태스크와 757개 벤치마크 인스턴스를 구축했다. 함수 사용 복잡도(simple, parallel, multiple, parallel multiple)와 맥락적 도전(relevance 판별, 누락 파라미터 처리)으로 분류된다.
더 강건한 평가를 위해, 저난이도 태스크에는 최대 7개, 고난이도 태스크에는 23개의 후보 함수 목록을 제공하며, 모델이 사용하지 말아야 할 방해 함수(distractor functions)도 포함하여 실제 프로덕션 샌드박스 환경을 시뮬레이션한다.
주요 서브 태스크:
| 태스크 | Size | Functions | 설명 |
|---|---|---|---|
| Simple (live/non-live) | 110 | 1 | 단일 함수 호출 |
| Parallel (live/non-live) | 38 | 1 | 같은 함수를 2회 이상 병렬 호출 |
| Multiple (live/non-live) | 110 | 7 | 여러 함수 중 적절한 것을 선택 |
| Parallel Multiple (live/non-live) | 36 | 7 | 여러 함수를 병렬로 호출 |
| Multi-step (partial/whole, live/non-live) | 92 | 7/23 | 여러 함수를 순차적으로 호출 |
| Item recommendation (live/non-live) | 52 | 1/2 | 사용자 선호/상황에 맞는 요금제 추천 |
| Irrelevance | 118 | - | 무관한 함수만 제공될 때 거부 |
| Relevance | 117 | - | 여러 함수 중 올바른 것만 선택 |
| Multi-turn Base | 46 | 23 | 멀티턴 대화에서 2개 이상 함수 호출 |
| Miss param | 38 | 23 | 누락 파라미터를 인식하고 추가 정보 요청 |
4. TelAgent RAG (258건)
비즈니스 KIS(Knowledge and Information System) 자료(약관, 멤버십 서비스 설명 등)를 활용한 검색 증강 생성 품질을 평가한다.
데이터 생성 과정:
- 가중 샘플링 알고리즘으로 고품질 데이터를 선별
- GPT-4와 자체 모델로 질문을 생성 (과적합 방지)
- HITL로 도메인 전문가와 언어 전문가가 관련성과 정확성을 검증
- 정답과 함께 방해 문서(distractor documents)를 추가하여 검색 정밀도를 테스트
각 샘플에는 5개의 문서가 제공된다. 방해 문서 선정은 두 가지 분포를 따른다:
- Best retrieval system의 top-5 결과: 유사하지만 정답이 아닌 문서
- RAFT(Zhang et al., 2024) 기반 epsilon-greedy 전략: top-k 관련 문서 + (5-k)개의 랜덤 방해 문서
데이터는 InfraRAG(50건, 인프라 하드웨어 기반)와 TelRAFT & TelRAG(208건, 고객 대면 AICC 질문 기반)로 구성된다.
5. TelAgent IF (300건)
한국어 언어적 뉘앙스와 통신 도메인 특화 요구사항을 포함한 instruction following 능력을 평가한다. IFEval(Zhou et al., 2023)을 확장하여 대화 시퀀스와 한국어 특성을 포함시키고, Multi-IF(Yun He, 2024)를 통합하여 멀티턴 평가를 구현했다.
이 벤치마크의 특징은 통신 도메인 데이터를 활용한 복합 커맨드(compound commands)의 구성이다. 단순한 지시 따르기를 넘어, 한국어 경어체(습니다/합니다/입니다), 음절 수 제약, 테이블 포맷팅, 민감정보 처리 등 한국어와 통신 특화 요구사항을 통합한다.
통신 특화 지시 유형(Table 13):
| 유형 | 지시 내용 | 예시 |
|---|---|---|
| Rate Plan Summary | 마크다운 테이블 포맷 | 요금제 정보를 테이블로 정리 (이름, 가격, 데이터량) |
| Customer Service Format | 경어체 사용 | 모든 문장을 ‘-습니다/합니다’ 체로 작성 |
| FAQ Response | 질문 반복 + 답변 | 질문을 먼저 반복하고, 콜론 뒤에 정확한 정보 기재 |
| Exclude Sensitive Info | 민감정보 제거 | 이름, 전화번호, 주소, 카드번호 제거 |
| Decline Impossible Requests | 키워드 포함 거절 | SK 텔레콤 서비스 범위 밖 요청에 정중히 거절 |
| Include Key Telco Terms | 핵심 정보 포함 | 요금제명/가격/데이터량 등 핵심 정보 반드시 포함 |
데이터는 General 도메인(200건, 3턴)과 Telco 도메인(100건, 2턴)으로 나뉜다.
Evaluation of LLMs
15개 주요 LLM(상용 9개, 오픈소스 6개)을 평가했다. Thinking 모델(명시적 추론을 사용하는 모델, [T]로 표기)과 non-thinking 모델을 구분하여 비교한다.
평가 방법론
각 차원별로 특화된 평가 메트릭을 사용한다.
| 차원 | 메트릭 | 평가 방법 |
|---|---|---|
| Reason | Average Accuracy | 4단계 매칭 시스템 (Exact → Normalized → Similarity → Core Content) |
| Plan | Average Pass-rate | Micro Pass Rate (개별 제약 만족 비율) + Macro Pass Rate (모든 제약 만족 플랜 비율) |
| Action | Average Accuracy | AST 매칭(단일턴) + Stateless Simulation Framework(멀티턴) |
| RAG | Average Faithfulness | Answer Correctness(k_rouge) + Faithfulness + Answer Relevancy |
| IF | Average Accuracy | IFEval의 prompt-level/instruction-level strict/loose accuracy 평균 |
Action 평가의 Stateless Simulation Framework
멀티턴 Action 태스크는 기존 BFC의 AST 매칭만으로는 평가가 어렵다. 저자는 stateless simulation framework를 도입했다. 핵심 아이디어는 도구 응답을 사전 정의된 ground truth로 시뮬레이션하여, 각 턴을 독립적으로 평가하되 상태 전이는 시뮬레이션하는 것이다.
각 턴의 평가 과정:
- Model Inference: 현재 대화 히스토리로 모델을 쿼리
- Response Parsing: 출력을 도구 호출 목록으로 파싱 (BFCL의 엄격한 AST에 더해, 통신 프로덕션 환경의 텍스트-코드 혼합 응답을 수용하는 유연한 문자열 기반 파싱 채택)
- Tool Simulation: 파싱된 도구 호출이 API 세트에 부합하는지 검증, ground truth와 AST 매칭
- Progress Logging:
matched,missing,progress(k/K),completed기록
턴 종료 조건:
- 성공: 모든 필요한 도구 호출을 정확히 완료 (k = K)
- Miss-param 성공: 도구 호출이 불필요한 턴(K=0)에서 적절히 추가 정보를 요청
- 실패: Premature Stop(k < K), 잘못된 호출(K=0인데 호출), Step Limit 초과(최대 20회)
RAG 평가의 3가지 핵심 메트릭
RAGAS에서 영감을 받아, 통신 특화 프롬프팅과 함께 3가지 메트릭으로 RAG 성능을 다면적으로 평가한다.
- Answer Correctness (k_rouge): precision 기반 F1 스코어링. LLM 판정자가 생성된 답변의 각 문장을 TP/FP/FN으로 분류하고, 추가로 korean_rouge_l 문자열 매칭을 수행
- Faithfulness: 생성된 답변이 소스 문서에 충실한 정도. Statement Decomposition → Document Verification → Weighted Scoring의 계층적 검증 프로세스
- Answer Relevancy: 생성된 답변의 관련성. LLM이 역질문(Question Generation)을 생성하고, Noncommittal Detection으로 회피적 응답을 식별하며, KoSimCSE-roberta-multitask으로 코사인 유사도를 계산
평가 결과
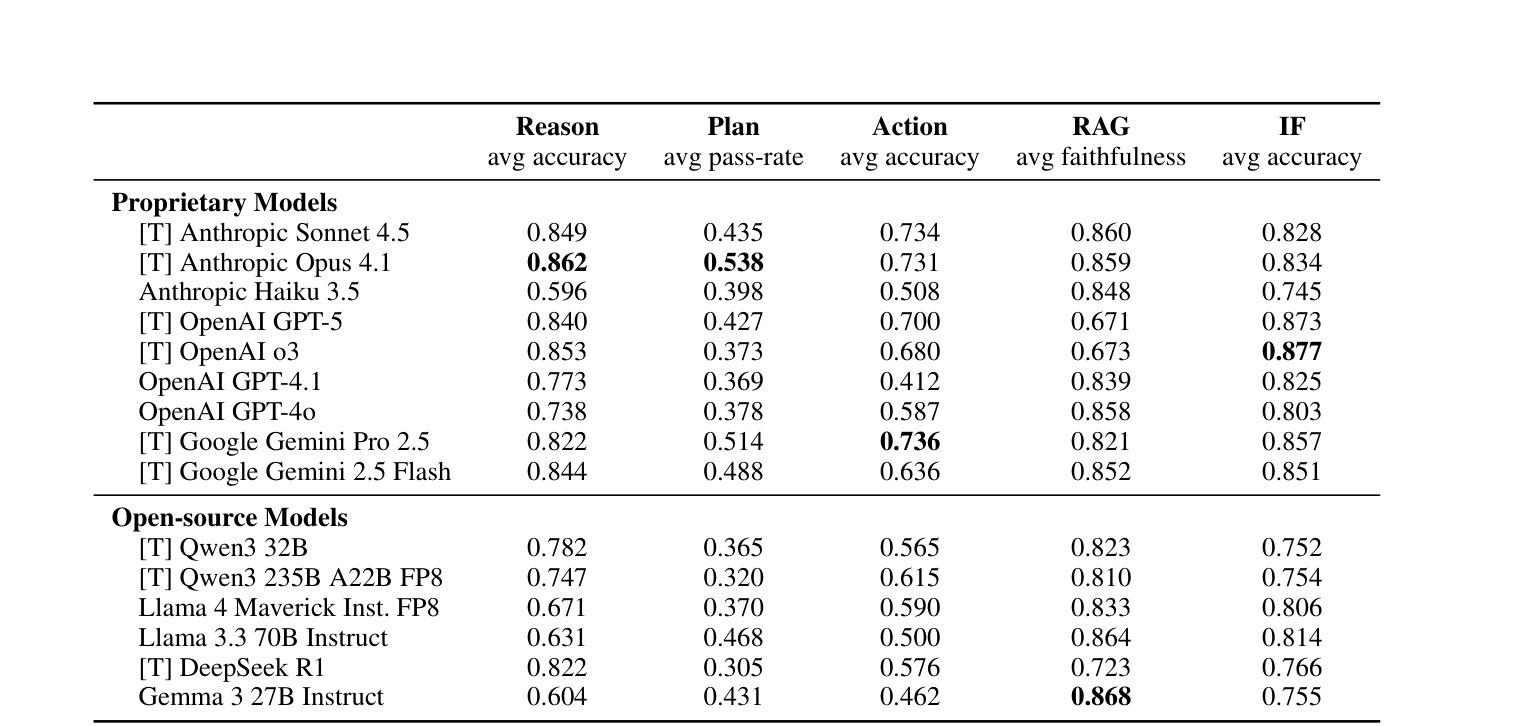
15개 LLM의 5개 차원별 종합 결과다. [T]는 thinking 모델을 의미한다.
전체 결과 테이블
상용 모델 (Proprietary)
| 모델 | Reason | Plan | Action | RAG | IF |
|---|---|---|---|---|---|
| [T] Anthropic Sonnet 4.5 | 0.849 | 0.435 | 0.734 | 0.860 | 0.828 |
| [T] Anthropic Opus 4.1 | 0.862 | 0.538 | 0.731 | 0.859 | 0.834 |
| Anthropic Haiku 3.5 | 0.596 | 0.398 | 0.508 | 0.848 | 0.745 |
| [T] OpenAI GPT-5 | 0.840 | 0.427 | 0.700 | 0.671 | 0.873 |
| [T] OpenAI o3 | 0.853 | 0.373 | 0.680 | 0.673 | 0.877 |
| OpenAI GPT-4.1 | 0.773 | 0.369 | 0.412 | 0.839 | 0.825 |
| OpenAI GPT-4o | 0.738 | 0.378 | 0.587 | 0.858 | 0.803 |
| [T] Google Gemini Pro 2.5 | 0.822 | 0.514 | 0.736 | 0.821 | 0.857 |
| [T] Google Gemini 2.5 Flash | 0.844 | 0.488 | 0.636 | 0.852 | 0.851 |
오픈소스 모델 (Open-source)
| 모델 | Reason | Plan | Action | RAG | IF |
|---|---|---|---|---|---|
| [T] Qwen3 32B | 0.782 | 0.365 | 0.565 | 0.823 | 0.752 |
| [T] Qwen3 235B A22B FP8 | 0.747 | 0.320 | 0.615 | 0.810 | 0.754 |
| Llama 4 Maverick Inst. FP8 | 0.671 | 0.370 | 0.590 | 0.833 | 0.806 |
| Llama 3.3 70B Instruct | 0.631 | 0.468 | 0.500 | 0.864 | 0.814 |
| [T] DeepSeek R1 | 0.822 | 0.305 | 0.576 | 0.723 | 0.766 |
| Gemma 3 27B Instruct | 0.604 | 0.431 | 0.462 | 0.868 | 0.755 |
분석 1: Thinking vs Non-Thinking 모델의 성능 격차
이 논문의 가장 핵심적인 발견이다. 명시적 추론(thinking)을 사용하는 모델이 전 차원에 걸쳐 일관되게 높은 성능을 보인다.
각 모델 패밀리 내에서 thinking vs non-thinking을 비교하면:
| 비교 | Reason | Plan | Action | IF |
|---|---|---|---|---|
| [T] Opus 4.1 vs Haiku 3.5 | 0.862 vs 0.596 (+0.266) | 0.538 vs 0.398 (+0.140) | 0.731 vs 0.508 (+0.223) | 0.834 vs 0.745 (+0.089) |
| [T] GPT-5 vs GPT-4.1 | 0.840 vs 0.773 (+0.067) | 0.427 vs 0.369 (+0.058) | 0.700 vs 0.412 (+0.288) | 0.873 vs 0.825 (+0.048) |
| [T] GPT-5 vs GPT-4o | 0.840 vs 0.738 (+0.102) | 0.427 vs 0.378 (+0.049) | 0.700 vs 0.587 (+0.113) | 0.873 vs 0.803 (+0.070) |
Action에서 격차가 가장 극적이다. GPT-5와 GPT-4.1의 차이가 0.288에 달하며, 이는 도구 호출에서 명시적 추론이 특히 중요함을 보여준다.
전체적으로, 상용 thinking 모델과 non-thinking 모델 간의 평균 성능 격차는 약 12%에 달한다.
분석 2: 차원별 심층 분석
TelAgent Reason
Thinking 모델이 높은 정확도로 우수한 성능을 보였다. 구체적으로, thinking 변형 모델(Sonnet 4.5, Opus 4.1, o3)은 높은 점수를 달성하며, 단일 문서와 복수 문서 맥락 모두에서 정밀한 정보 추출과 논리적 추론 능력을 입증했다.
5가지 multi-hop QA 유형 중 Procedural Arithmetic이 가장 도전적이었다. 할인율 계산, 중복 혜택 적용 등 절차적 산술이 필요한 이 유형에서 대부분의 모델이 성능 저하를 보였다. 그럼에도 상위 thinking 모델(Sonnet 4.5, Opus 4.1, DeepSeek R1)은 안정적인 성능을 유지하며, 모든 추론 유형에서 일관되게 높은 정확도를 보여 thinking의 효과를 입증했다.
상용 모델과 오픈소스 모델 간의 대비도 뚜렷하다. 상용 thinking 모델은 단일 문서(single-document)에서 90% 이상, 복수 문서(multi-document)에서도 85% 이상의 정확도를 달성한 반면, 오픈소스 non-thinking 모델은 두 설정 모두에서 60-70% 대에 머물렀다. DeepSeek R1은 오픈소스 중 유일하게 0.822로 상용 thinking 모델에 근접했으며, 이는 thinking 역량 자체가 모델 크기보다 중요한 요인임을 시사한다.
또한, 상용 모델은 충분한 맥락을 확보하기 위해 thinking 모델에서 15.4%, non-thinking에서 2.7%의 비율로 추가 정보를 요청했다. 반면 오픈소스 모델은 각각 3.2%, 0.0%로 낮았다. 이는 Kalai et al.(2025)의 관찰 – 모델이 “모르겠다”고 답하기보다 추측하여 벤치마크 점수를 높이려는 경향 – 과 일치하며, Gemini 2.5 Flash의 경우 이 경향이 특히 두드러져 상대적으로 낮은 성능을 기록했다.
TelAgent Plan
상용 모델이 오픈소스 모델보다 평균 약 5.9% 높은 성능을 보였다. 상용 모델 중에서는 Anthropic Opus 4.1이 0.538로 최고 성능을 기록했으며, commonsense 제약과 hard 제약 모두에서 탁월하여, 포괄적이면서 세부 지시에도 충실한 계획을 수립하는 능력을 보였다. 최고 pass-rate를 달성한 것은 이 모델이 상식적 판단(commonsense)과 구체적 규칙 준수(hard constraint)를 균형 있게 수행할 수 있음을 의미한다.
Google Gemini Pro 2.5도 0.514로 강력한 성능을 보여, 복잡한 제약 조합 처리에서의 강점을 입증했다. 오픈소스 모델 중에서는 Llama 3.3 70B Instruct가 0.468로 최고였다.
Plan은 thinking 모델과 non-thinking 모델 간 차이가 일관되지만, 오픈소스 thinking 모델이 오히려 non-thinking보다 낮은 경우도 관찰되었다. DeepSeek R1이 0.305로 전체 최하위를 기록한 것이 대표적이다. 이는 추론 능력이 뛰어나더라도 복잡한 여행-로밍 통합 계획의 실행으로 이어지지 못하는 한계를 보여준다.
TelAgent Action
Thinking 역량을 갖춘 모델이 전반적으로 최고 성능을 보였으며, 특히 명시적 추론이 행동에 필요한 조건 분석(condition analysis)에서 결정적 역할을 한다. 도메인 특화 제약(output strictness)이 필요한 태스크에서, thinking 모델이 더 안정적이고 신뢰성 있는 태스크 완료를 보여준다.
난이도에 따른 상용-오픈소스 격차 변화가 가장 인상적인 발견이다:
| 난이도 | 예시 태스크 | 상용 non-thinking vs 오픈소스 격차 |
|---|---|---|
| Simple | 단일 함수 호출 | 3.6% |
| Medium (Multiple) | 7개 후보 중 정확한 함수 선택 | 11.6% |
| Hard (Parallel Multiple) | 여러 함수를 동시에 병렬 호출 | 15.2% |
난이도가 올라갈수록 격차가 4배 이상 벌어진다. 이는 단순한 함수 호출은 대부분의 모델이 수행할 수 있지만, 여러 함수를 동시에 정확히 선택하고 병렬로 호출하는 복합 태스크에서 상용 모델의 학습 데이터 우위가 결정적으로 작용함을 보여준다.
Live vs Non-Live 환경에서도 차이가 나타난다. Non-Live 환경의 Item Recommendation 태스크가 가장 도전적이었다. 이 태스크에서는 사용자의 선호, 상황, 제약을 종합하여 적절한 요금제를 추천해야 하는데, 정확한 함수 호출을 결정하기 위한 맥락 정보가 제한적이기 때문이다. 예를 들어, “34살인데 내년에 YOUNG 요금제를 못 쓰게 되니까 비슷한 무제한 요금제가 있나요?”와 같은 질의는 연령 제한, 요금제 비교, 추천이라는 복합적 판단을 요구한다.
TelAgent RAG
RAG는 5개 차원 중 상용-오픈소스 격차가 가장 작은 차원이며, 유일하게 오픈소스가 상용을 앞서는 차원이다.
상용 모델 중 모든 Claude 계열이 우수한 Faithfulness를 보였으며, AICC와 Infra 태스크 모두에서 84% 이상을 달성했다. 반면, OpenAI의 thinking 모델(GPT-5, o3)은 약 67%로 상대적으로 낮은 점수를 보였다. 이는 thinking 모델의 추론 trace가 소스 문서에서 벗어나는(diverge) 경향 때문으로 분석된다. 소스 문서의 내용을 충실히 인용하기보다, 추론 과정에서 자체적인 해석을 추가하여 faithfulness가 떨어지는 것이다. 흥미롭게도, non-thinking OpenAI 모델(GPT-4.1, GPT-4o)은 안정적인 성능을 유지했는데, 이는 추론 과정이 단순할수록 소스에 더 충실한 응답을 생성하는 역설적 현상을 보여준다.
오픈소스 모델의 격차가 빠르게 좁혀지고 있다:
- Llama-3.3-70B-Instruct: 평균 Faithfulness 83%, Sonnet 4.5/Opus 4.1에 필적
- Llama-4-Maverick: 경쟁력 있는 83% 기록
- Gemma 3 27B: 전체 1위 0.868 달성
이들 모델은 Answer Relevancy와 Correctness에서도 유사한 점수를 보여, 대규모 컨텍스트 윈도우(10만 토큰 이상)와 효과적인 instruction tuning이 RAG 특화 최적화 없이도 높은 faithfulness를 달성할 수 있음을 시사한다.
주목할 점으로, GPT-5가 상용 모델 중 가장 낮은 RAG 성능(0.671)을 보였다. 분석 결과, API가 추론 토큰 한도(reasoning token limits)로 인해 조기 종료(premature termination)되는 경향이 발견되었으며, 이는 지정된 제약 내에서 과도한 thinking 토큰을 소비하기 때문이다. 이 이슈는 개발자 커뮤니티에서도 널리 보고된 바 있다.
TelAgent IF
Thinking 모델과 non-thinking 모델 간 약 5.19%의 성능 격차가 관찰되었다. 이 격차는 복잡한 다중 지시(multi-instruction)와 멀티턴 상호작용에서 더 두드러지며, 단계별 추론이 복잡한 지시 처리에 효과적임을 시사한다.
상용-오픈소스 간 성능 차이는 약 5.76%였다. 상세히 분석하면:
단일 지시 vs 다중 지시: 대부분의 모델이 단일 지시보다 다중 지시에서 더 낮은 성능을 보였다. 오픈소스 모델의 격차가 상대적으로 더 컸는데, 이는 여러 제약을 동시에 만족시키는 능력에서 학습 데이터 품질의 차이가 드러남을 의미한다.
단일턴 vs 멀티턴: 모든 모델이 단일턴에서 실질적으로 더 높은 성능을 보였으며, 모델에 따라 최대 20.8%의 격차가 나타났다. 이는 멀티턴 대화 처리가 본질적으로 더 도전적이며, 이전 턴의 지시를 기억하면서 새로운 지시도 따라야 하는 누적적 지시 관리(cumulative instruction management)가 요구되기 때문이다. 예를 들어 3턴 General 도메인에서는:
- 1턴: “이력서 자기소개 문장 작성, 빈칸 채우기”
- 2턴: “적절한 제목을 이중 꺾쇠괄호로 작성”
- 3턴: “경어체(-습니다/합니다/입니다)로 작성하고 150단어 이내로 제한”
3턴에서는 1-2턴의 지시를 모두 유지하면서 새로운 포맷과 길이 제약까지 충족해야 한다.
General vs Telco 도메인: 대부분의 모델이 telco 도메인보다 general 도메인에서 더 높은 정확도를 달성했다. 통신 특화 콘텐츠가 더 큰 어려움을 제기하는 것이다. 통신 도메인의 지시에는 “요금제명/가격/데이터량을 반드시 포함”, “민감정보 제거”, “SK 텔레콤 서비스 범위 밖 요청에 정중히 거절” 등 도메인 특화 규칙이 포함되어, 일반적인 instruction following보다 높은 도메인 이해를 요구한다. 상용 모델은 도메인 간 성능 격차가 작은 반면, 오픈소스 모델은 더 큰 불일치를 보여, 상용 모델이 더 다양한 도메인 데이터로 학습되었음을 시사한다.
분석 3: 상용 vs 오픈소스 모델 비교
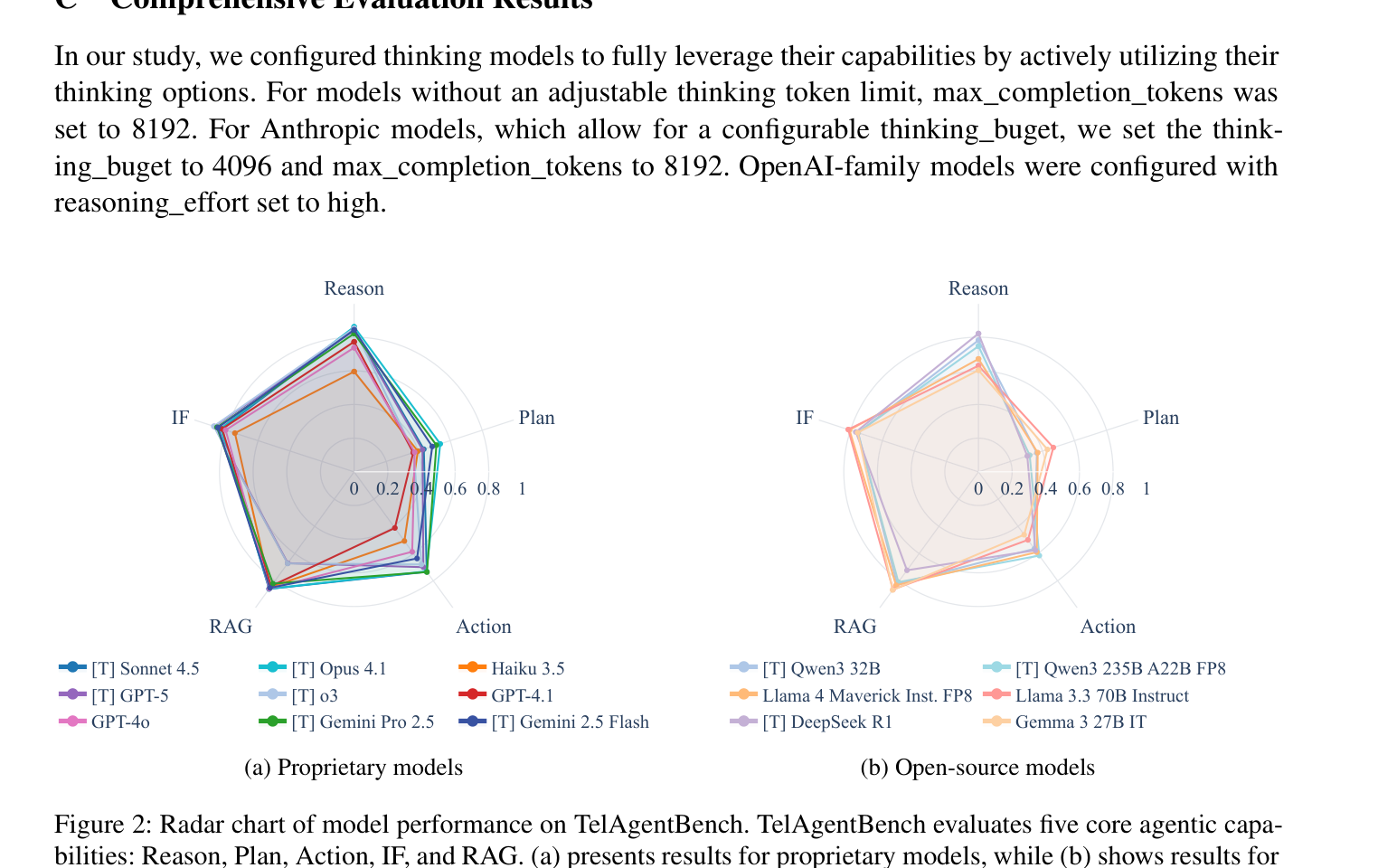
레이더 차트에서 상용 모델(왼쪽)은 전반적으로 넓고 균형 잡힌 면적을 보이는 반면, 오픈소스 모델(오른쪽)은 차원별 편차가 더 크다.
차원별 상용-오픈소스 최고 성능 비교:
| 차원 | 상용 최고 | 오픈소스 최고 | 격차 |
|---|---|---|---|
| Reason | 0.862 ([T] Opus 4.1) | 0.822 ([T] DeepSeek R1) | -0.040 |
| Plan | 0.538 ([T] Opus 4.1) | 0.468 (Llama 3.3 70B) | -0.070 |
| Action | 0.736 ([T] Gemini Pro 2.5) | 0.615 ([T] Qwen3 235B) | -0.121 |
| RAG | 0.860 ([T] Sonnet 4.5) | 0.868 (Gemma 3 27B) | +0.008 |
| IF | 0.877 ([T] o3) | 0.814 (Llama 3.3 70B) | -0.063 |
RAG에서만 오픈소스 모델(Gemma 3 27B, 0.868)이 상용 모델을 앞선다. 나머지 4개 차원에서는 상용 모델이 우세하며, 특히 Action에서 격차(0.121)가 가장 크다. 복잡한 도구 호출에서 상용 모델의 우위가 가장 뚜렷하다.
분석 4: 모델별 강점과 약점 프로파일
각 모델의 5차원 성능을 분석하면, 단일 모델이 모든 차원에서 최고 성능을 보이지 않으며, 실제 서비스 배포 시 태스크 특성에 맞는 모델 선택이 중요함을 알 수 있다.
| 모델 | 최강 차원 | 최약 차원 | 특이점 |
|---|---|---|---|
| [T] Opus 4.1 | Reason(0.862), Plan(0.538) | Action(0.731) | Plan에서 압도적 1위, 5개 차원 중 4개에서 상위 3위 이내. 종합 최강 |
| [T] Sonnet 4.5 | RAG(0.860), Action(0.734) | Plan(0.435) | RAG 상용 1위, Action 2위. Plan은 중하위 |
| [T] GPT-5 | IF(0.873), Reason(0.840) | RAG(0.671) | RAG 최하위(추론 토큰 과소비로 조기 종료). IF에서는 강세 |
| [T] o3 | IF(0.877) | Plan(0.373) | IF 전체 1위, 지시 따르기 최강. Plan은 하위 |
| [T] Gemini Pro 2.5 | Action(0.736) | RAG(0.821) | Action 전체 1위, 도구 호출 최강. 5차원 모두 상위권으로 균형 잡힌 프로파일 |
| [T] DeepSeek R1 | Reason(0.822) | Plan(0.305) | Plan 전체 최하위, Reason은 상위권. 추론은 강하지만 복합 계획으로의 전이가 약함 |
| Gemma 3 27B | RAG(0.868) | Action(0.462) | RAG 전체 1위(오픈소스), 27B로 405B급 RAG 성능. Action 최하위권 |
| Llama 3.3 70B | RAG(0.864), Plan(0.468) | Action(0.500) | 오픈소스 Plan 1위, RAG 2위. non-thinking인데 Plan이 강한 예외적 사례 |
이 분석에서 도출되는 실용적 모델 선택 가이드라인:
- 고객 상담 에이전트 (Action + IF 중심): [T] Gemini Pro 2.5 또는 [T] Sonnet 4.5
- 지식 검색 서비스 (RAG 중심): Gemma 3 27B (비용 효율적) 또는 [T] Sonnet 4.5
- 여행/로밍 계획 (Plan 중심): [T] Opus 4.1 (유일하게 0.5 이상)
- 정책 문서 QA (Reason 중심): [T] Opus 4.1 또는 [T] o3
- 종합 에이전트: [T] Gemini Pro 2.5 (5차원 모두 상위권, 가장 균형 잡힌 프로파일)
분석 5: 차원 간 상관관계
5개 차원의 성능이 서로 어떻게 연관되는지 분석하면, 에이전트 역량의 구조적 관계를 이해할 수 있다.
Reason과 Action의 강한 양의 상관관계: 추론 능력이 높은 모델이 도구 호출에서도 우수한 성능을 보이는 경향이 뚜렷하다. [T] Opus 4.1(Reason 0.862, Action 0.731), [T] GPT-5(0.840, 0.700), [T] Gemini Pro 2.5(0.822, 0.736) 등이 이를 보여준다. 반면 Gemma 3 27B(Reason 0.604, Action 0.462)는 두 차원 모두 하위권이다. 이는 도구 호출이 단순한 API 매칭이 아니라, 사용자 의도 파악 → 적절한 도구 선택 → 파라미터 결정이라는 추론 과정을 내포하기 때문이다.
RAG와 다른 차원의 약한 상관관계: RAG 성능은 다른 차원과 상관이 약하다. Gemma 3 27B는 RAG 1위(0.868)이면서 Reason(0.604), Action(0.462) 하위권이고, GPT-5는 Reason(0.840) 상위권이면서 RAG(0.671) 최하위다. RAG 성능은 추론이나 도구 호출 능력보다 컨텍스트 윈도우 크기와 instruction tuning 품질에 더 의존하는 것으로 보인다.
Plan의 독립적 특성: Plan은 가장 낮은 전체 평균(0.40 내외)을 보이며, 다른 차원의 성능과 뚜렷한 상관관계가 없다. DeepSeek R1은 Reason 0.822로 높지만 Plan 0.305로 전체 최하위이며, Llama 3.3 70B는 Reason 0.631로 중하위이지만 Plan 0.468로 오픈소스 1위다. 이는 multi-step 계획이 단순 추론과 질적으로 다른 능력 – 제약 조합의 탐색, 실현 가능성 판단, 전체 일정의 일관성 유지 – 을 요구하기 때문이다.
TelBench에서 TelAgentBench로의 발전
TelBench (EMNLP 2024)가 상담 후처리와 기본 에이전트 역량을 평가했다면, TelAgentBench는 이를 5가지 핵심 에이전트 역량의 체계적 평가로 확장했다.
| 관점 | TelBench (2024) | TelAgentBench (2025) |
|---|---|---|
| 평가 초점 | 상담 후처리 + 기본 에이전트 | 5가지 핵심 에이전트 역량 |
| 데이터셋 | TelTask(7개) + TelInstruct(3개) | Reason + Plan + Action + RAG + IF |
| 인스턴스 수 | -3,500건 | -1,700건 (더 정밀한 평가) |
| 에이전트 평가 | Workflow (기초적) | Tool-calling, Multi-step Planning, RAG 등 심화 |
| 평가 대상 | 6개 모델 | 15개 모델 (thinking/non-thinking 구분) |
| 핵심 발견 | 도메인 특화 학습의 필요성 | thinking vs non-thinking 모델의 성능 격차 |
| 환경 | 실제 상담 데이터 기반 | 합성 데이터 + 시뮬레이션 환경 |
Discussion & Conclusion
TelAgentBench는 통신 서비스 생태계 내에서 에이전트 LLM을 평가하기 위한 도메인 특화, 산업 기반 벤치마크다. 5가지 핵심 에이전트 역량을 1,700개 이상의 한국어 인스턴스로 평가하며, 15개 모델에 대한 교차 분석을 통해 다음의 핵심 통찰을 제공한다:
- Thinking 모델의 우위: 명시적 추론을 사용하는 모델이 전 차원에서 일관되게 높은 성능을 보이며, 특히 Action(도구 호출)에서 그 격차가 가장 크다.
- 난이도에 따른 격차 확대: 쉬운 태스크에서는 상용-오픈소스 격차가 3.6%에 불과하지만, 고난이도에서는 15.2%까지 벌어진다.
- RAG에서의 오픈소스 선전: RAG 차원에서만 오픈소스 모델(Gemma 3 27B)이 상용 모델을 상회하며, 대규모 컨텍스트 윈도우의 효과를 시사한다.
- 멀티턴의 도전: 모든 모델이 단일턴 대비 멀티턴에서 최대 20.8% 낮은 성능을 보이며, 장기 대화 관리의 어려움을 보여준다.
Limitations
- 한국어 텍스트 한정: 현재 한국어만 지원하며, 다국어 및 교차 언어 평가로의 확장이 필요하다.
- 단일 통신사 관점: 단일 통신사의 운영 환경을 반영하므로, 다른 통신사의 워크플로우를 과소 대표할 수 있다. 다양한 지역별 사용 사례를 포함하여 공정한 교차 시장 평가를 촉진할 필요가 있다.
- 모델 발전 속도: 최신 모델을 반영하고 있지만, LLM 생태계의 빠른 발전으로 인해 벤치마크의 지속적 업데이트가 필요하다.
범용 하위 집합을 HuggingFace에 공개하여 후속 연구와 다른 도메인으로의 확장을 촉진한다.
참고 문헌
- TelAgentBench: A Multi-faceted Benchmark for Evaluating LLM-based Agents in Telecommunications (ACL Anthology)
- TelAgentBench Dataset (HuggingFace)
- TelBench: A Benchmark for Evaluating Telco-Specific Large Language Models (ACL Anthology)
- TravelPlanner – Xie et al., 2024
- Berkeley Function Calling Leaderboard – Yan et al., 2024
- RAGAS – Es et al., 2025
- IFEval – Zhou et al., 2023
- ReAct – Yao et al., 2023
Enjoy Reading This Article?
Here are some more articles you might like to read next: