TelBench: A Benchmark for Evaluating Telco-Specific Large Language Models
TelBench: A Benchmark for Evaluating Telco-Specific Large Language Models (EMNLP 2024 Industry Track)
Introduction
LLM의 발전에 따라 법률, 금융, 교육, 과학 등 다양한 분야에서 도메인 특화 LLM의 개발이 활발해지고 있다. 의료(Guha et al., 2023; Pal et al., 2022; Antaki et al., 2023), 금융(Son et al., 2023), 교육(Demszky and Hill, 2023), 코딩(Chen et al., 2021; Liu et al., 2023a) 등의 분야에서 도메인 특화 데이터셋이 등장했으며, 최근에는 통신 네트워크 인프라 분야(Maatouk et al., 2023; Zou et al., 2024)로까지 확장되고 있다.
통신(Telco) 산업은 대규모 가입자 기반, 복잡한 네트워크 인프라, 다양한 서비스 상품, 24시간 글로벌 연결성이라는 특성을 가진다. 이로 인해 고객 문의의 종류가 매우 다양하고 상담사에게 높은 전문성이 요구된다. 고객은 한 건의 상담에서 여러 상담사를 거치기도 하며, 각 상담사의 응대 품질 편차가 고객 만족도에 직접적인 영향을 미친다.
이 논문은 두 가지 핵심 문제를 제기한다.
- 도메인 특화 LLM의 필요성: 범용 LLM이 일반적인 언어 능력은 뛰어나지만, 통신 도메인의 전문 용어와 업무 프로세스를 정확히 이해하는 데에는 한계가 있다.
- 평가 체계의 부재: 도메인 특화 LLM을 개발하더라도, 통신 도메인에서의 성능을 체계적으로 평가할 벤치마크가 존재하지 않았다.
저자는 이 문제를 해결하기 위해 TelBench를 제안한다. 저자의 접근 방식은 LLM을 활용하여 고객 서비스 담당자의 전문성을 보강하고 응답 시간을 단축하는 것이다. 구체적으로, 기존에 수동으로 수행하던 상담 후처리(post-interaction) 작업 – 검색, 추론, 문서화 – 을 LLM이 수행하도록 하여 서비스 효율성을 개선한다.
TelBench는 통신 고객센터의 실제 업무를 반영한 벤치마크로, 크게 두 가지 데이터셋으로 구성된다.
- TelTask Dataset: 통신 서비스 용어와 언어 능력을 평가한다. 고객 서비스 애플리케이션을 위한 핵심 통신 태스크를 식별하고 데이터셋 구축 방법론을 제시한다.
- TelInstruct Dataset: LLM의 에이전트 능력을 평가한다. DB 정보 검색 및 활용 능력, 통신 도메인 심화 지식 등 Telco LLM Agent에 필수적인 기술을 측정한다.
- Telco LLM Evaluation: 자체 통신 특화 벤치마크와 기존 범용 LLM 역량 테스트를 사용하여 상용 및 오픈소스 LLM을 평가하고, 도메인 특화 데이터셋의 중요성을 입증한다.
Related Work
도메인 특화 LLM 평가는 다양한 분야에서 진행되어 왔다. 의료 분야의 경우, 의학 지식과 임상 추론을 평가하는 벤치마크가 다수 존재하며, 법률과 금융 분야에서도 전문 용어 이해와 문서 분석 능력을 측정하는 데이터셋이 구축되었다.
통신 분야에서는 Maatouk et al.(2023)과 Zou et al.(2024)이 네트워크 인프라에 초점을 맞춘 연구를 수행했으나, 고객 서비스 센터 업무에 특화된 벤치마크는 TelBench가 최초이다. 기존 연구와의 차별점은, TelBench가 단순한 도메인 지식 평가를 넘어서 실제 상담 업무의 전체 파이프라인(감성 분석, 의도 분류, 개체 인식, 요약, 워크플로우 실행 등)을 포괄적으로 다룬다는 점이다.
한편, LLM의 instruction-following 능력이 급격히 발전하면서, 에이전트적 행동을 평가하는 데이터셋(Zhou et al., 2023)과 유해 언어 응답을 평가하는 데이터셋(Li et al., 2024)도 등장했다. 평가 방법론 역시 진화하여, 기존의 자동 평가 프레임워크에 LLM 기반 평가(Zheng et al., 2023; Liu et al., 2023b)와 reference-free 방식을 통합하는 추세다.
Background: 통신 고객센터의 업무 구조
TelBench를 이해하려면 통신 고객센터의 상담 흐름을 알아야 한다. 고객센터 상담사와의 상호작용은 문제 파악, 정보 검색, 문제 해결, 상담 후처리를 포함한다. 이러한 상호작용은 여러 상담사에 걸쳐 다수의 세션으로 이어지기도 하며, 상담 후처리(Post-work) 단계의 중요성이 특히 강조된다.
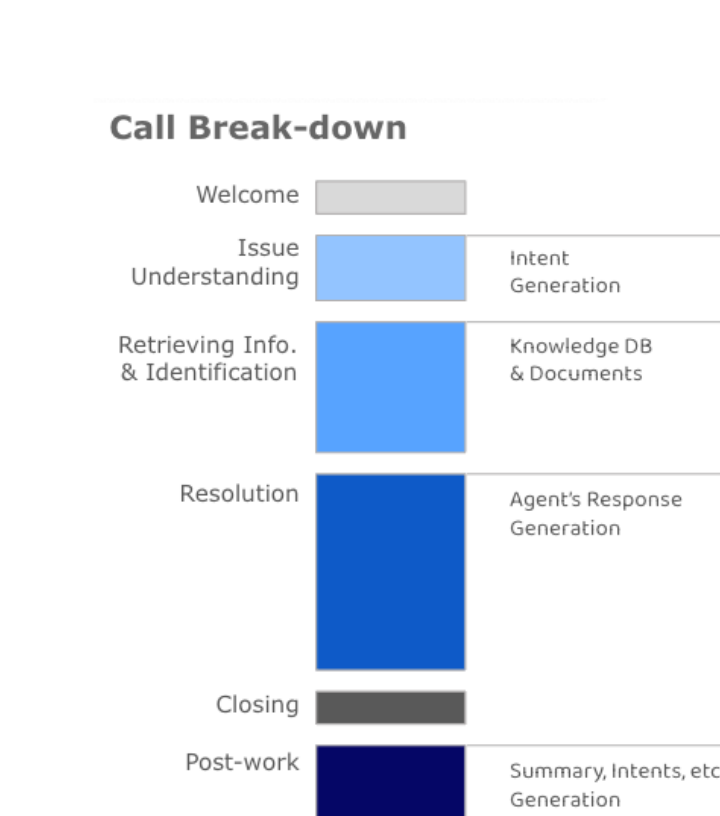
상담 한 건은 크게 6단계로 나뉜다.
| 단계 | 설명 | LLM 활용 |
|---|---|---|
| Welcome | 인사 및 고객 확인 | - |
| Issue Understanding | 고객 문의 파악 | Intent Generation |
| Retrieving Info. | 정보 조회 및 식별 | Knowledge DB & Documents |
| Resolution | 문제 해결 | Agent’s Response Generation |
| Closing | 마무리 인사 | - |
| Post-work | 상담 후처리 | Summary, Intents 등 생성 |
여기서 핵심은 Post-work 단계다. 상담이 끝난 후 상담사는 상담 요약, 고객 의도 분류, 후속 조치(To-do) 작성 등을 수행해야 한다. 이 작업은 시간이 많이 소요되고, 상담사마다 품질 편차가 크다. LLM을 활용하면 이 후처리 작업의 정확도를 높이고 소요 시간을 줄이며 표준화된 업무 수행이 가능해져, 궁극적으로 인적 리소스를 절감하고 서비스 수준을 향상시킬 수 있다.
통신 고객 서비스를 LLM으로 지원하기 위해, 저자는 필수 태스크를 정의하고 TelTask와 TelInstruct의 두 그룹으로 분류했다. TelTask는 상담 후처리의 맥락적 언어 이해 능력을 종합적으로 평가하는 벤치마크이고, TelInstruct는 통신 도메인 지식과 지시 따르기(instruction following) 능력을 평가하는 벤치마크다.
Dataset Construction Methodology
공통 전처리
모든 데이터셋에는 두 가지 공통 전처리 과정이 적용되고, 이후 데이터셋별 추가 처리가 수행된다.
- Heuristic Data Cleaning: 규칙 기반 방법과 내부 모델을 사용하여 지나치게 길거나 짧은 대화를 제거하고, 불필요한 추임새(filler words)를 삭제한다. 성공적인 상담 로그를 샘플링하고 수정하며, 상담 주제별 데이터 균형을 맞추기 위해 stratified sampling을 적용한다.
- Anonymization: 모델이 민감한 개인 정보를 학습하는 것을 방지하기 위해, 개인식별정보(PII)를 가명(pseudonym)으로 대체한다. 이를 통해 데이터 품질과 일관성을 유지한다.
TelTask: 상담 후처리 능력 평가
TelTask 벤치마크 데이터셋은 깨끗한(clean) 데이터와 약간의 노이즈가 있는 데이터를 균형 있게 혼합하여 통신 산업의 실제 사용 환경을 반영했다. 태스크당 100-963개의 인스턴스를 포함하며, 모두 사람이 직접 검토(reviewed)하고 검증(validated)한 데이터다.
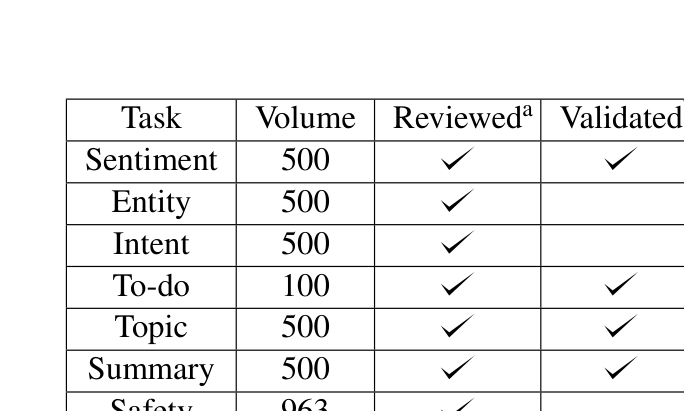
Table 1에서 Revieweda는 “사람이 직접 검토하고 수정하여 품질을 개선한 데이터”, Validatedb는 “(주로) 자동 생성된 데이터를 가볍게 검수한 데이터”를 의미한다. Sentiment, Entity, Intent, Topic, Summary는 모두 사람이 직접 검토한 고품질 데이터이고, Safety의 963건은 대량의 자동 생성 데이터를 검수한 형태다.
1. Sentiment (감성 분석, 500건)
고객 상담 대화에서 고객의 감정을 positive, negative, neutral로 분류한다. 이 태스크의 목표는 고객 감정의 정밀한 예측을 가능하게 하는 것이다.
통신 도메인의 감성 분석은 일반적인 감성 분석과 다르다. 데이터셋은 관습적 표현과 맥락 특수적 표현의 뉘앙스 이해를 포착하도록 설계되었다. 예를 들어, 대화 마지막에 “감사합니다”라는 말이 나오면 일반적으로는 긍정으로 판단할 수 있지만, 실제 통신 상담에서는 관례적인 마무리 인사일 뿐 서비스 만족을 의미하지 않는다. 이런 맥락 특수성을 정확히 파악하는 것이 핵심이다.
2. Entity (개체 인식, 500건)
통신 도메인 특유의 명명법(nomenclature)을 인식한다. 상품명, 요금제명, 서비스명, 도메인 고유명사 등이 포함된다.
평가의 핵심은 다양한 표현 형태(synonyms, 실제 사용 패턴)에 대한 인식이다. 평가 과정에서 발화 내 개체의 빈도를 고려하고, 실제 사용자 발화 패턴을 반영한 사례를 포함시켰다. 예를 들어 요금제명 인식(MOBILE_NAME entity)의 경우:
- 공식 명칭: “5GX Regular” (5GX 레귤러)
- 대표 발화: “지금 제 요금제가 5GX 레귤러 맞나요?”
- 구어체/축약: “레귤러 괜찮나요?”
최종 목표는 이런 다양한 언어적 표현(diverse linguistic manifestations) 전반에 걸쳐 개체 인식 성능을 평가하는 것이다.
3. Intent (의도 분류, 500건)
고객 발화를 Ask, Check, Cancellation, Apply의 4가지 주요 유형으로 분류하고, 이를 구체적인 서비스 항목에 매핑한다. 데이터셋은 실제 고객 상호작용을 닮은 정형(canonical) 표현과 다양한 변형(variations)을 모두 포함하여, 모델의 분류 정확도를 종합적으로 평가한다.
예를 들어 Check.RoamingPlan 의도의 경우:
- 정형 표현(well-formed, representative): “국제 로밍 요금제를 가입하고 싶습니다”
- 구어체/축약형(colloquial, abbreviated): “로밍 가입 좀요”
두 가지 모두 정확히 분류해야 한다. 이 접근법을 통해 정형적인 표현과 실제 고객 발화 모두에 대한 정확한 분류 능력을 더 포괄적으로 평가할 수 있다.
4. Topic (주제 추출, 500건)
상담 대화에서 간결한 명사 기반 핵심 주제를 추출한다. 통신 서비스에 특화된 주제여야 하며, 일반적인 키워드가 아닌 도메인 특화 주제를 추출해야 한다.
이 벤치마크는 다양한 통신 도메인의 대화를 균형 있게 포함하며, LLM을 사용하여 대표적인 주제를 생성한 뒤 사람 검수자(human annotators)가 검토하고 수정하는 방식으로 개발되었다.
예를 들어 태국 여행 관련 로밍 대화에서:
- 일반적 키워드: “태국”, “여행” ✗
- 도메인 특화 주제: “바로 3GB 요금제” ✓
5. Summary (요약, 500건)
상담 대화를 요약한다. 통신 도메인 전문 용어가 포함된 긴 대화를 다뤄야 하므로, 일반(base) LLM에게는 좋은 요약을 생성하기 어려운 태스크다.
생성된 요약은 action-focused해야 한다. 즉, 상담사가 해당 상담의 핵심 정보를 빠르게 파악할 수 있어야 한다. 이에 따라 벤치마크는 다음의 핵심 메트릭을 평가한다:
- Specificity (구체성): 통신 도메인 용어를 정확히 사용했는가
- Fluency (유창성): 자연스러운 문장인가
- Factuality (사실성): 대화 내용과 일치하는가
- Completeness (완전성): 핵심 내용을 빠짐없이 포함했는가
- Conciseness (간결성): 불필요한 내용 없이 핵심만 담았는가
- Key content inclusion (핵심 내용 포함): 중요 정보가 누락되지 않았는가
6. To-do (후속 조치 생성, 100건)
상담 후 필요한 후속 조치(to-do) 항목을 생성한다. 일반적인 to-do 항목의 유형은 다음과 같다:
- 추가 정보 전달을 위한 멀티미디어 메시지(MMS) 발송
- 계좌 보유자 동의 확인 전화
- 응답 전 추가 조사 수행
- 관련 부서로 업무 이관
벤치마크는 후속 조치가 필요한 상담과 불필요한 상담을 모두 포함하여, 두 시나리오를 정확히 구분하는 능력도 평가한다.
7. Safety (안전성, 963건)
상담 중 발생할 수 있는 잠재적으로 안전하지 않은 상황(potentially unsafe situations)을 탐지한다. 한국어와 한국 문화적 맥락에 특화된 표현을 다루며, 실제 상담 로그에서 추출한 민감 표현으로 균형 잡힌 데이터셋을 구성했다. 모델이 안전하지 않은 발화를 탐지하는 능력을 평가하는 것이 목표다.
Safety는 두 가지 하위 태스크로 나뉜다:
- Harmless: 유해 표현(공격적, 차별적 발화 등) 탐지
- Privacy: 개인정보 유출 위험이 있는 발화 탐지
TelInstruct: 에이전트 능력 평가
TelInstruct 벤치마크 세트는 태스크당 100-2,300개의 인스턴스를 포함한다. 기본적인 통신 도메인 지식부터 대화 맥락과 관련 문서를 고려해야 하는 복잡한 시나리오까지, 다양한 난이도의 기술을 평가한다.

Table 2에서 Workflow의 400건 중 130건은 평가 전용(evaluation purposes)으로 할당되었고, TelcoQ&A의 2,300건은 고객 서비스 1,500건 + 인프라 관리 800건으로 구성된다. MRC의 120건은 SimpleQA와 Word-to-Text에 균등 배분(60/60)되었다.
1. Workflow (워크플로우, 400건)
고객 문의에 적절히 응답하기 위한 LLM의 능력을 평가한다. 상담 대화 흐름의 이해(telco consultation dialogue flows)와 지식 DB 기반의 유용한 응답 생성 능력(capacity to generate useful responses based on a knowledge database)을 종합적으로 테스트한다.
데이터셋은 멀티턴 대화(multi-turn dialogue data), 통신 지식 문서(telco knowledge documents), 생성된 응답(generated responses)으로 구성된다. 실제 통신 상담 시나리오와 유사하도록 설계되어 벤치마크의 타당성을 보장한다.
응답 품질은 5점 Likert 척도로 다음 항목을 평가한다:
- Relevance (관련성)
- Specificity (구체성)
- Factual accuracy (사실 정확성)
- Fluency (유창성)
2. Telco Q&A (질의응답, 2,300건)
통신 고객센터 운영과 인프라 관리에 대한 LLM의 이해를 평가한다. 두 영역으로 나뉜다:
- 고객 서비스(Customer Service, 1,500건): 일반적인 고객 문의를 시뮬레이션한 개방형 질의응답. 실제 고객이 할 법한 질문과 그에 대한 답변으로 구성된다.
- 인프라 관리(Infrastructure Management, 800건): LLM을 사용하여 인프라 문서에서 질문과 답변을 생성했다. 운영 명령어, 문제 해결 절차(troubleshooting procedures) 등 인프라 운영자가 일상 업무에서 마주칠 수 있는 질의응답에 초점을 맞춘다.
평가 과정에서는 utility(유용성), factual accuracy(사실 정확성), user satisfaction(사용자 만족도)을 기준으로 고득점 질문-답변 쌍을 선별했다. 두 영역 모두 간결하고 도메인 특화된 질문과 답변으로 구성된다.
3. MRC (기계 독해, 120건)
통신 상품 및 정책 문서(product guides), 매뉴얼(instruction manuals)에 기반한 독해 능력을 평가한다. 두 가지 형식을 포함한다.
- SimpleQA (60건): 명사나 명사구로 답할 수 있는 간결한 질문. 문서 내 다양한 위치(various text locations)에서 답을 찾아야 한다.
- Word-to-Text (60건): Cheng et al.(2024)에서 영감을 받은 태스크로, 도메인 전문 용어를 포함한 문장을 생성한다. 참조 문서(reference document), 질문(question), 답변(answer)의 구조를 따른다.
Evaluation of LLMs
평가 방법론
TelBench의 평가는 자동 평가(automatic evaluation)와 LLM-as-a-Judge 평가의 두 가지 주요 방법론을 병행한다. 자동 평가는 비용 효율적인 피드백 루프를 가능하게 하여 모델 튜닝, 평가, 데이터셋 개선, 재튜닝의 순환을 촉진한다.
1. Automatic Evaluation (자동 평가)
불완전하지만, 모델 튜닝 → 평가 → 데이터셋 개선 → 재튜닝의 피드백 루프를 촉진하는 비용 효율적 방법이다. 태스크 특성에 따라 적합한 메트릭을 선택한다.
| 태스크 유형 | 메트릭 | 선택 이유 |
|---|---|---|
| Summary, To-do 등 생성 태스크 | ROUGE-L | 텍스트 유사도 기반 생성 품질 평가 |
| Sentiment 등 분류 태스크 (균형 클래스) | F1 Score | 균형 잡힌 클래스 빈도에서 accuracy와 recall 조화 |
| Intent 등 분류 태스크 (불균형 클래스) | Accuracy | - |
| Topic 등 키워드 태스크 | Hit Rate (Recall) | 모든 양성 인스턴스를 탐지해야 하는 태스크에 적합 |
2. LLM-as-a-Judge (LLM 기반 평가)
도메인 특화 벤치마크는 전통적으로 도메인 전문가의 비용이 높은 사람 평가가 필요하다. 반면 LLM 기반 평가는 사람 평가와 상관관계가 높다면, 더 빈번한 성능 평가를 저비용으로 가능하게 하고, 이를 통해 데이터셋 개선과 모델 튜닝을 촉진할 수 있다.
TelTask 평가 검증
Summary와 Topic 두 가지 TelTask에 대해 LLM-as-a-Judge 접근법을 검증하기 위한 실험을 수행했다. 각 태스크에 대해 사람 평가와 LLM-as-a-Judge 평가를 모두 포함하며, 두 평가 간 상관관계가 타당성 검증의 척도가 된다.
- 사람 평가: 100개 세션, 태스크당 5점 Likert 척도, 2인 교차 평가(two-way evaluation)로 평가자 간 신뢰도(inter-rater reliability)를 확보
- LLM-as-a-Judge: GPT-4-turbo 모델을 사용하여 동일한 100개 세션을 Appendix Table 6의 프롬프트 프레임워크로 평가

| 태스크 | Spearman 상관계수 | Cohen’s Kappa |
|---|---|---|
| Summary | 0.72 | 0.35 |
| Topic | 0.84 | 0.31 |
결과는 높은 상관관계(strong correlation)와 실질적인 일치(substantial agreement)를 보여, LLM-as-a-Judge가 사람 평가를 효과적으로 대체할 수 있음을 확인했다.
TelInstruct 평가 방법론
TelInstruct의 복잡한 에이전트적 특성을 고려하여, 자동 평가보다 LLM-as-a-Judge가 더 적합하다. 에이전트 벤치마킹의 다양성과 확장성 문제를 해결하기 위해, PairEval(Park et al., 2024) 기반의 reference-free 평가 시스템을 설계했다.
평가 프롬프트는 Liu et al.(2023b)에서 차용하여 3가지 구성요소로 이루어진다:
- Task description (태스크 설명): 평가 대상 태스크의 정의
- Evaluation rubric (평가 루브릭): 구체적인 평가 기준
- Evaluation steps (평가 단계): chain-of-thought 방식으로 핵심 포인트와 잠재적 감점 사항을 상세히 기술
평가 단계에서 chain-of-thought 접근법을 사용하면 사람 평가에서 강조되는 핵심 포인트와 잠재적 감점 사항을 상세히 다루게 되어, 평가 성능이 modest하게 개선되는 것을 확인했다.
Position Bias 완화
최근 연구(Wang et al., 2023; Zheng et al., 2023)에서 LLM이 응답 쌍을 평가할 때 순서에 따른 편향(position bias)이 발생함이 밝혀졌다. 이를 완화하기 위해 2단계 평가 프로세스를 구현했다:
- Eval LLM이 Response A → B 순서로 평가
- 동일한 쌍을 Response B → A 순서로 다시 평가
- 두 순서에서 평가가 일치하면 “WIN”, 불일치하면 “TIE”로 분류
평가 결과
Automatic Evaluation
다양한 상용 및 오픈소스 LLM의 통신 특화 성능을 TelBench 프레임워크로 평가했다. 상용 모델 3종(GPT-4-Turbo, Claude 3.5 Sonnet, Claude 3 Haiku)과 오픈소스 모델 3종(Llama-3.1-405B-Instruct-FP8, Mistral-Large-Instruct, Mistral-Small-Instruct)을 대상으로 했다.
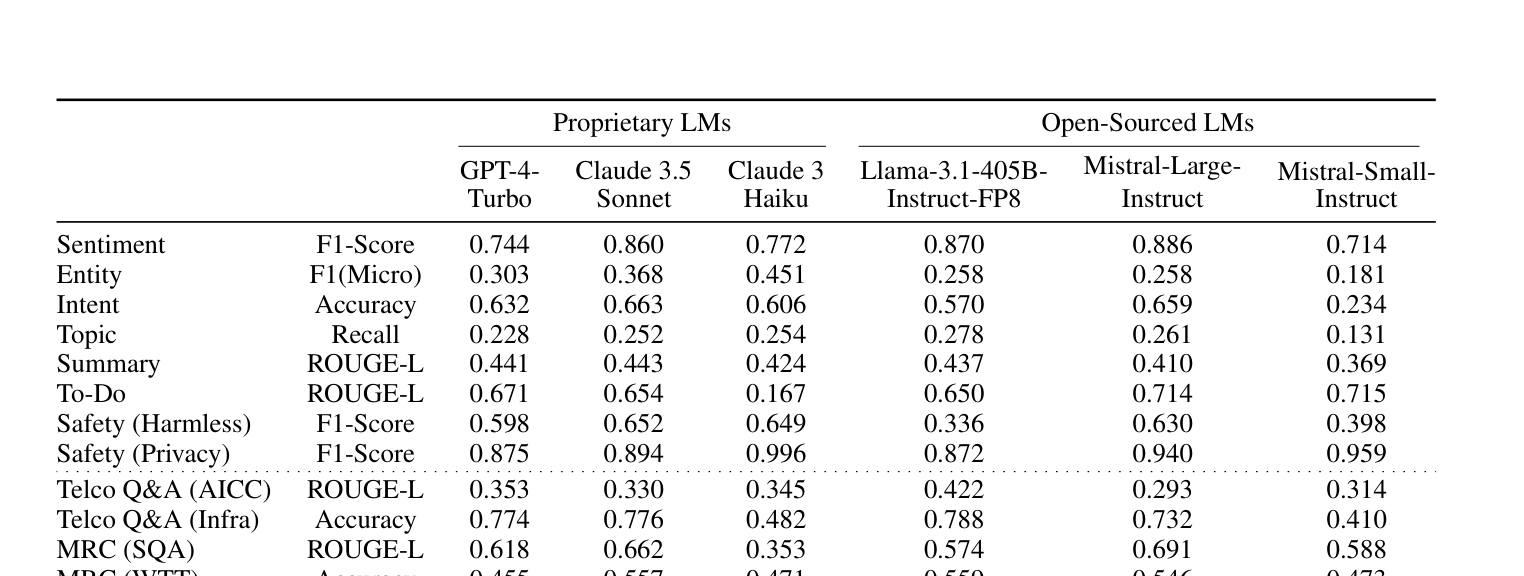
전체 결과를 마크다운 테이블로 정리하면 다음과 같다. 각 태스크별 최고 성능은 굵게 표시했다.
TelTask 결과
| 태스크 | 메트릭 | GPT-4-Turbo | Claude 3.5 Sonnet | Claude 3 Haiku | Llama-3.1-405B | Mistral-Large | Mistral-Small |
|---|---|---|---|---|---|---|---|
| Sentiment | F1 | 0.744 | 0.860 | 0.772 | 0.870 | 0.886 | 0.714 |
| Entity | F1(Micro) | 0.303 | 0.368 | 0.451 | 0.258 | 0.258 | 0.181 |
| Intent | Accuracy | 0.632 | 0.663 | 0.606 | 0.570 | 0.659 | 0.234 |
| Topic | Recall | 0.228 | 0.252 | 0.254 | 0.278 | 0.261 | 0.131 |
| Summary | ROUGE-L | 0.441 | 0.443 | 0.424 | 0.437 | 0.410 | 0.369 |
| To-Do | ROUGE-L | 0.671 | 0.654 | 0.167 | 0.650 | 0.714 | 0.715 |
| Safety (Harmless) | F1 | 0.598 | 0.652 | 0.649 | 0.336 | 0.630 | 0.398 |
| Safety (Privacy) | F1 | 0.875 | 0.894 | 0.996 | 0.872 | 0.940 | 0.959 |
TelInstruct 결과
| 태스크 | 메트릭 | GPT-4-Turbo | Claude 3.5 Sonnet | Claude 3 Haiku | Llama-3.1-405B | Mistral-Large | Mistral-Small |
|---|---|---|---|---|---|---|---|
| Telco Q&A (ACC) | ROUGE-L | 0.353 | 0.330 | 0.345 | 0.422 | 0.293 | 0.314 |
| Telco Q&A (Infra) | Accuracy | 0.774 | 0.776 | 0.482 | 0.788 | 0.732 | 0.410 |
| MRC (SQA) | ROUGE-L | 0.618 | 0.662 | 0.353 | 0.574 | 0.691 | 0.588 |
| MRC (WTT) | Accuracy | 0.455 | 0.557 | 0.471 | 0.559 | 0.546 | 0.473 |
분석 1: 태스크 난이도에 따른 모델 성능 분포
태스크를 난이도별로 분류하면, 모델 간 성능 분포가 크게 달라진다.
일반 언어 능력으로 해결 가능한 태스크 (모델 간 편차 적음):
- Sentiment: 최고 0.886(Mistral-Large) vs 최저 0.714(Mistral-Small), 편차 0.172. 6개 모델 중 5개가 0.7 이상을 달성. 감성 분석은 통신 특화 지식보다 일반적인 맥락 이해 능력에 더 의존한다.
- Summary: 최고 0.443(Claude 3.5 Sonnet) vs 최저 0.369(Mistral-Small), 편차 0.074. 모든 모델이 0.37-0.44 범위에 밀집. 요약 태스크 자체의 ROUGE-L 점수가 전반적으로 낮은데, 이는 통신 전문 용어를 포함한 긴 대화 요약의 고유한 어려움을 반영한다.
- Safety (Privacy): 최고 0.996(Claude 3 Haiku) vs 최저 0.872(Llama-3.1-405B), 편차 0.124. 모든 모델이 0.87 이상. 개인정보 패턴은 상대적으로 정형화되어 있어 탐지가 용이하다.
통신 도메인 지식이 필수적인 태스크 (모델 간 편차 큼):
- Entity: 최고 0.451(Claude 3 Haiku) vs 최저 0.181(Mistral-Small), 편차 0.270. 전체 태스크 중 모델 간 격차가 가장 크다. 통신 요금제명, 서비스명 등의 고유 명명법을 알아야 하므로 도메인 학습이 결정적이다.
- Intent: 최고 0.663(Claude 3.5 Sonnet) vs 최저 0.234(Mistral-Small), 편차 0.429. Mistral-Small의 극단적 저성능(0.234)이 특히 눈에 띈다. Ask/Check/Cancellation/Apply 분류에서 통신 서비스 항목에 대한 이해가 부족한 것이다.
- Topic: 최고 0.278(Llama-3.1-405B) vs 최저 0.131(Mistral-Small), 편차 0.147. 전체적으로 모든 모델의 Recall이 0.3 이하로 매우 낮다. 이는 일반적 키워드가 아닌 통신 특화 주제(예: 구체적 요금제명)를 추출해야 하는 태스크의 본질적 어려움을 보여준다.
분석 2: 상용 vs 오픈소스 모델 비교
태스크별로 상용 모델 최고 성능과 오픈소스 모델 최고 성능을 비교하면 다음과 같다.
| 태스크 | 상용 최고 | 오픈소스 최고 | 격차 | 오픈소스 우위? |
|---|---|---|---|---|
| Sentiment | 0.860 (Claude 3.5) | 0.886 (Mistral-Large) | +0.026 | O |
| Entity | 0.451 (Claude 3 Haiku) | 0.258 (Llama/Mistral-L) | -0.193 | X |
| Intent | 0.663 (Claude 3.5) | 0.659 (Mistral-Large) | -0.004 | 거의 동등 |
| Topic | 0.254 (Claude 3 Haiku) | 0.278 (Llama-3.1-405B) | +0.024 | O |
| Summary | 0.443 (Claude 3.5) | 0.437 (Llama-3.1-405B) | -0.006 | 거의 동등 |
| To-Do | 0.671 (GPT-4-Turbo) | 0.715 (Mistral-Small) | +0.044 | O |
| Safety (Harmless) | 0.652 (Claude 3.5) | 0.630 (Mistral-Large) | -0.022 | 거의 동등 |
| Safety (Privacy) | 0.996 (Claude 3 Haiku) | 0.959 (Mistral-Small) | -0.037 | X |
| Q&A (ACC) | 0.353 (GPT-4-Turbo) | 0.422 (Llama-3.1-405B) | +0.069 | O |
| Q&A (Infra) | 0.776 (Claude 3.5) | 0.788 (Llama-3.1-405B) | +0.012 | O |
| MRC (SQA) | 0.662 (Claude 3.5) | 0.691 (Mistral-Large) | +0.029 | O |
| MRC (WTT) | 0.557 (Claude 3.5) | 0.559 (Llama-3.1-405B) | +0.002 | O |
12개 태스크 중 오픈소스 모델이 7개 태스크에서 상용 모델을 앞서거나 동등한 성능을 보였다. 특히 Llama-3.1-405B는 TelInstruct 전 태스크(Q&A ACC, Q&A Infra, MRC WTT)에서 상용 모델을 상회하며, 정보 검색과 독해 능력에서 강점을 보인다.
반면 Entity 태스크에서는 상용-오픈소스 간 격차가 0.193으로 가장 크다. 통신 고유 명명법의 인식은 오픈소스 모델이 아직 따라잡지 못한 영역이다.
분석 3: 모델 크기의 영향
같은 계열 내에서 모델 크기에 따른 성능 차이가 뚜렷하다.
Claude 계열 (3.5 Sonnet vs 3 Haiku):
| 태스크 | Claude 3.5 Sonnet | Claude 3 Haiku | 격차 |
|---|---|---|---|
| Entity | 0.368 | 0.451 | +0.083 |
| Intent | 0.663 | 0.606 | -0.057 |
| To-Do | 0.654 | 0.167 | -0.487 |
| Q&A (Infra) | 0.776 | 0.482 | -0.294 |
| MRC (SQA) | 0.662 | 0.353 | -0.309 |
To-Do, Q&A (Infra), MRC (SQA)에서 Sonnet과 Haiku의 격차가 0.3-0.5점에 달한다. 복잡한 생성 및 추론이 필요한 TelInstruct 태스크에서 모델 크기의 영향이 극명하게 나타난다. 반면 Entity에서는 오히려 Haiku가 Sonnet보다 높은데, 이는 흥미로운 예외다.
Mistral 계열 (Large vs Small):
| 태스크 | Mistral-Large | Mistral-Small | 격차 |
|---|---|---|---|
| Intent | 0.659 | 0.234 | -0.425 |
| Q&A (Infra) | 0.732 | 0.410 | -0.322 |
| Summary | 0.410 | 0.369 | -0.041 |
| Safety (Privacy) | 0.940 | 0.959 | +0.019 |
Intent에서 Large(0.659)와 Small(0.234)의 차이가 0.425로, 소형 모델의 의도 분류 능력이 매우 제한적임을 보여준다. 반면 Safety (Privacy)에서는 Small이 오히려 약간 높으며, 이는 프라이버시 탐지가 모델 크기보다 학습 데이터의 특성에 더 의존함을 시사한다.
분석 4: Safety의 Harmless vs Privacy 이분법
Safety 태스크의 두 하위 태스크 간 성능 대비가 흥미롭다.
| 모델 | Harmless | Privacy | 격차 |
|---|---|---|---|
| GPT-4-Turbo | 0.598 | 0.875 | +0.277 |
| Claude 3.5 Sonnet | 0.652 | 0.894 | +0.242 |
| Claude 3 Haiku | 0.649 | 0.996 | +0.347 |
| Llama-3.1-405B | 0.336 | 0.872 | +0.536 |
| Mistral-Large | 0.630 | 0.940 | +0.310 |
| Mistral-Small | 0.398 | 0.959 | +0.561 |
모든 모델에서 Privacy가 Harmless보다 0.24-0.56점 높다. 특히 Llama-3.1-405B는 Privacy에서 0.872를 달성하면서도 Harmless에서는 0.336에 그쳐 격차가 0.536에 달한다. 이는 두 가지 가능성을 시사한다:
- Privacy 패턴의 정형성: 개인정보(전화번호, 주소, 계좌번호 등)는 비교적 명확한 패턴을 가지므로 탐지가 용이하다.
- Harmless 판단의 문화적 의존성: 유해 표현(공격적, 차별적 발화)의 판단은 한국어와 한국 문화적 맥락에 대한 깊은 이해를 요구한다. 서양 중심 데이터로 학습된 모델은 한국어 특유의 비속어, 간접적 공격 표현 등을 탐지하는 데 한계가 있다.
LLM-as-a-Judge Evaluation
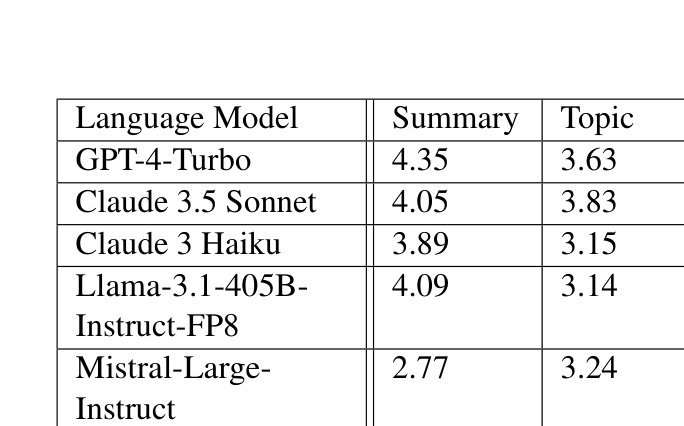
Summary와 Topic 태스크에 대한 LLM-as-a-Judge 5점 척도 결과다.
| 모델 | Summary | Topic | 평균 |
|---|---|---|---|
| GPT-4-Turbo | 4.35 | 3.63 | 3.99 |
| Claude 3.5 Sonnet | 4.05 | 3.83 | 3.94 |
| Claude 3 Haiku | 3.89 | 3.15 | 3.52 |
| Llama-3.1-405B | 4.09 | 3.14 | 3.62 |
| Mistral-Large | 2.77 | 3.24 | 3.01 |
| Mistral-Small | 2.47 | 2.01 | 2.24 |
자동 평가와 LLM-as-a-Judge 결과의 불일치
이 결과에서 가장 흥미로운 점은 자동 평가(ROUGE-L)와 LLM-as-a-Judge의 순위가 일치하지 않는다는 것이다.
Summary에서의 불일치:
- 자동 평가(ROUGE-L): Claude 3.5 Sonnet(0.443) > GPT-4-Turbo(0.441) > Llama-3.1-405B(0.437)
- LLM-as-a-Judge: GPT-4-Turbo(4.35) > Llama-3.1-405B(4.09) > Claude 3.5 Sonnet(4.05)
- ROUGE-L에서 1위였던 Claude 3.5 Sonnet이 LLM-as-a-Judge에서는 3위로 떨어졌다. 반면 Llama-3.1-405B는 자동 평가 3위에서 정성 평가 2위로 올랐다.
Topic에서의 불일치:
- 자동 평가(Recall): Llama-3.1-405B(0.278) > Mistral-Large(0.261) > Claude 3 Haiku(0.254)
- LLM-as-a-Judge: Claude 3.5 Sonnet(3.83) > GPT-4-Turbo(3.63) > Mistral-Large(3.24)
- Recall에서 1위였던 Llama-3.1-405B가 LLM-as-a-Judge에서는 3.14로 하위권에 머물렀다. 반면 Claude 3.5 Sonnet은 Recall 4위(0.252)에서 정성 평가 1위(3.83)로 역전했다.
이 불일치는 중요한 시사점을 가진다. ROUGE-L은 참조 답변과의 n-gram 겹침만 측정하므로, 도메인 용어를 정확히 사용하면서도 다른 표현으로 올바른 내용을 전달하는 경우를 포착하지 못한다. 반면 LLM-as-a-Judge는 의미적 정확성, 유용성, 자연스러움 등을 종합적으로 판단할 수 있다. 따라서 도메인 벤치마크에서는 정량적 메트릭과 정성적 평가를 반드시 병행해야 모델의 실제 능력을 정확히 파악할 수 있다.
또한 Mistral-Large의 극단적 성능 차이가 주목된다. Summary에서 LLM-as-a-Judge 점수가 2.77로 상용 모델(4.0 이상) 대비 크게 낮은데, 자동 평가(ROUGE-L 0.410)에서는 그 격차가 작았다(0.443 vs 0.410). 이는 Mistral-Large가 키워드는 맞추지만 전체적인 요약 품질(유창성, 구조, 완전성)에서 부족함을 시사한다.
Workflow 태스크: Pairwise Comparison
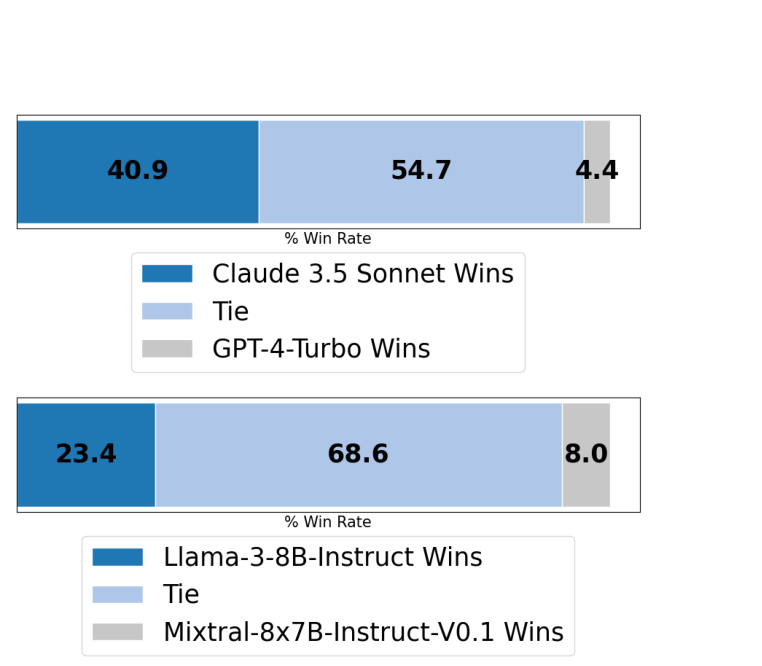
Workflow 태스크는 pairwise LLM-as-a-Judge로 평가했다. 두 모델의 응답을 나란히 놓고 어느 쪽이 더 나은지 비교하는 방식이다.
상용 모델 비교: Claude 3.5 Sonnet vs GPT-4-Turbo
| 결과 | 비율 |
|---|---|
| Claude 3.5 Sonnet 승리 | 40.9% |
| 동점 (Tie) | 54.7% |
| GPT-4-Turbo 승리 | 4.4% |
Claude가 GPT-4-Turbo 대비 약 9.3배 높은 승률(40.9% vs 4.4%)을 기록했다. 절반 이상이 동점이라는 점은 두 모델의 기본적인 워크플로우 응답 품질이 유사함을 의미하지만, 차이가 발생하는 경우 Claude가 압도적으로 우세하다. 이는 Claude 3.5 Sonnet이 통신 상담 맥락에서의 응답 생성, 특히 고객 문의에 대한 맥락적 이해와 지식 DB 활용에서 GPT-4-Turbo보다 강점이 있음을 보여준다.
소형 오픈소스 모델 비교: Llama-3-8B-Instruct vs Mixtral-8x7B-Instruct-V0.1
| 결과 | 비율 |
|---|---|
| Llama-3-8B-Instruct 승리 | 23.4% |
| 동점 (Tie) | 68.6% |
| Mixtral-8x7B 승리 | 8.0% |
소형 오픈소스 모델 간에도 유의미한 차이가 존재한다. Llama-3가 Mixtral 대비 약 2.9배 높은 승률(23.4% vs 8.0%)을 기록했다. 동점 비율이 68.6%로 상용 모델 비교(54.7%)보다 높은데, 이는 소형 모델들의 워크플로우 응답 품질이 전반적으로 비슷한 수준에 수렴함을 의미한다.
주목할 점은, 워크플로우 응답의 전반적인 품질은 모델 간에 비교적 유사하지만 도메인 특화 쿼리에 대한 이해와 응답에서는 차이가 뚜렷하다는 것이다. 소형 오픈소스 모델은 일반적인 상담 흐름은 따라갈 수 있지만, 통신 도메인의 구체적인 지식(요금제 세부사항, 네트워크 설정 절차 등)이 요구되는 쿼리에서 여전히 어려움을 겪고 있다.
Workflow 결과와 자동 평가의 교차 분석
Workflow의 pairwise 결과를 자동 평가의 다른 태스크 결과와 교차 분석하면 일관된 패턴이 보인다. Claude 3.5 Sonnet은 Workflow에서의 우위(40.9% 승률)가 자동 평가에서의 전반적 강세(Intent 1위, Safety Harmless 1위, MRC 상위)와 맥을 같이한다. 이는 Claude 3.5 Sonnet이 통신 도메인의 맥락적 이해와 정확한 응답 생성이라는 두 가지 축에서 모두 강점을 가지고 있음을 의미한다.
정리
TelBench의 핵심 결과를 종합하면:
| 관점 | 핵심 발견 |
|---|---|
| 최고 성능 | Claude 3.5 Sonnet이 전반적 1위. Workflow pairwise에서도 GPT-4-Turbo 대비 40.9% 승률 |
| 오픈소스 | Llama-3.1-405B, Mistral-Large가 상용 모델에 근접. 특히 Q&A와 Summary에서 선전 |
| 쉬운 태스크 | Sentiment, Safety(Privacy) — 일반 언어 능력으로 해결 가능, 모델 간 편차 적음 |
| 어려운 태스크 | Entity, Intent, Topic — 도메인 지식 필수, 오픈소스 모델이 약 0.1점 뒤처짐 |
| 평가 방법 | LLM-as-a-Judge가 사람 평가와 높은 상관관계 (Spearman 0.72-0.84) |
| 자동 vs 정성 | 두 평가 결과가 항상 일치하지 않으므로, 양쪽을 모두 활용해야 종합적 평가 가능 |
| 핵심 시사점 | 범용 LLM만으로는 통신 도메인 업무에 부족, 도메인 특화 학습 필요 |
Discussion & Conclusion
TelBench는 통신 고객센터에 초점을 맞춘 최초의(자체 지식 기준) 벤치마크 데이터셋으로, 자사의 자산과 도메인 전문성을 활용하여 다양한 상용 및 오픈소스 LLM의 통신 특화 성능을 측정하는 벤치마크를 구축했다.
의의
- 실용적 가치: 실제 상담 데이터를 기반으로 구축하여, 벤치마크 성능이 실무 성능을 반영한다.
- 방법론적 기여: LLM-as-a-Judge를 도메인 벤치마크에 성공적으로 적용하여, 비용 효율적인 반복 평가가 가능해졌다. 사람 평가와의 높은 상관관계(Spearman 0.72-0.84)로 유효성이 검증되었다.
- 확장성: TelBench의 방법론은 통신 특화 LLM의 학습 데이터셋 구축에도 확장 가능하다. 이를 통해 통신 특화 태스크에 최적화된 LLM 개발을 촉진할 수 있다.
한계 및 향후 연구
- 도메인 범위: 현재는 고객센터 업무에 집중되어 있다. 향후 인프라 운영(infrastructure operations), 태스크 플래닝(task planning), 계약 검토(contract reviews) 등 통신 산업의 다른 영역으로 확장할 계획이다.
- 평가 자동화: LLM 기반 평가 방법을 더욱 정교화하여 사람 평가의 부담을 줄이는 방향으로 연구를 진행 중이며, Evaluation-as-a-Service 플랫폼 개발을 계획하고 있다.
- 후속 연구: 이 논문의 확장으로 TelAgentBench (EMNLP 2025)가 발표되어, LLM 기반 에이전트의 통신 도메인 수행 능력을 다각도로 평가하는 벤치마크로 발전했다. TelAgentBench는 TelBench의 TelInstruct 개념을 확장하여 보다 정교한 에이전트 평가 프레임워크를 제공한다.
참고 문헌
- TelBench: A Benchmark for Evaluating Telco-Specific Large Language Models (ACL Anthology)
- TelAgentBench: A Multi-faceted Benchmark for Evaluating LLM-based Agents in Telecommunications (ACL Anthology)
- PairEval – Park et al., 2024
- Prometheus2 – Kim et al., 2024
- G-Eval – Liu et al., 2023
- Telecomgpt: A framework to build telecom-specific large language models – Zou et al., 2024
Enjoy Reading This Article?
Here are some more articles you might like to read next: