FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (Dao et al., Stanford, NeurIPS 2022)
Introduction
현재 NLP와 Vision 분야에서 transformer는 활발히 사용되고 있다. 하지만 transformer의 핵심인 attention은 시퀀스 길이 \(N\)에 대해 \(O(N^2)\)의 시간과 메모리를 사용한다. 이를 해결하기 위해 sparse-approximation, low-rank approximation 등 다양한 approximate attention 방법이 제안되었지만, 이론적인 FLOP 감소에도 불구하고 실제 wall-clock 속도는 크게 개선되지 않는 경우가 많았다.
저자는 이 괴리의 원인을 IO(메모리 읽기/쓰기)에서 찾는다. GPU 연산은 충분히 빠르지만, 느린 HBM(High Bandwidth Memory)에서 데이터를 읽고 쓰는 것이 실제 병목이다. 기존 attention 구현은 중간 행렬 \(S, P \in \mathbb{R}^{N \times N}\)을 HBM에 저장하고 다시 읽어야 하므로 \(O(N^2)\)의 메모리 접근이 발생한다.
FlashAttention은 이 문제를 tiling과 recomputation으로 해결한다. \(S, P\)를 HBM에 저장하지 않고, 블록 단위로 SRAM에서 연산을 수행하여 HBM 접근을 최소화한다. 그 결과 FLOPs는 오히려 증가하지만, IO가 줄어들어 실제 속도는 2~4배 빨라지고 메모리 사용량은 \(O(N^2)\)에서 \(O(N)\)으로 줄어든다.
Background
GPU Memory Hierarchy
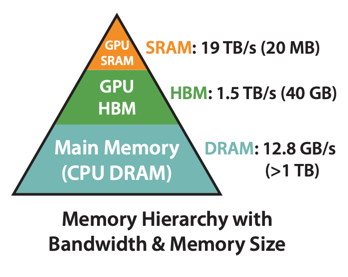
GPU는 CPU와 마찬가지로 메모리 계층을 가진다. A100 GPU 기준:
| 메모리 | 용량 | 대역폭 |
|---|---|---|
| HBM (DRAM) | 40~80 GB | 1.5~2.0 TB/s |
| SRAM (on-chip, per SM) | 192 KB | ~19 TB/s |
SRAM은 HBM보다 약 10배 빠르지만, 용량은 수십만 배 작다. GPU는 병렬 연산 시 데이터를 HBM에서 가져온 후 SRAM에 올려놓고 연산을 한다. SRAM 용량을 초과하면 데이터를 다시 HBM에 저장하고 새로운 데이터를 올려야 한다.
Performance Characteristics
연산의 병목이 어디에 있느냐에 따라 두 가지로 분류할 수 있다.
Compute-bound: 연산량이 메모리 접근보다 많은 경우. 시간은 연산량에 비례한다.
- 예: 큰 행렬의 MatMul, channel이 많은 convolution
Memory-bound: 메모리 접근이 연산량보다 많은 경우. 시간은 메모리 접근량에 비례한다.
- 예: elementwise 연산 (activation, dropout), reduction 연산 (softmax, batchnorm, layernorm)
이를 정량적으로 판단하는 지표가 연산 강도(arithmetic intensity)이다.
\[\text{Arithmetic Intensity} = \frac{\text{FLOPs}}{\text{Bytes accessed}}\]연산 강도가 GPU의 ops:byte 비율보다 높으면 compute-bound, 낮으면 memory-bound이다. A100의 경우 FP16 matmul은 312 TFLOPS / 2 TB/s = 약 156 ops/byte이므로, 대부분의 matmul은 compute-bound이다. 반면 softmax, dropout 등은 원소당 몇 개의 연산만 수행하므로 memory-bound이다.
Kernel Fusion

Memory-bound 연산을 가속하는 가장 일반적인 방법은 kernel fusion이다. 같은 데이터에 대해 여러 연산(예: matmul → bias add → activation → dropout)을 수행할 때, 각 연산마다 HBM에 쓰고 다시 읽는 대신, 한 번 HBM에서 읽어서 여러 연산을 SRAM에서 수행하고 최종 결과만 HBM에 쓰면 된다.
하지만 standard attention에서는 \(S = QK^\top\) 행렬의 크기가 \(N \times N\)이어서 SRAM에 올릴 수 없다. 따라서 kernel fusion이 불가능하고, \(S\)와 \(P\)를 HBM에 저장해야 한다. FlashAttention은 tiling을 통해 이 문제를 해결한다.
Standard Attention Implementation
Sequence length \(N\)과 head dimension \(d\)에 대하여 attention은 input sequence \(Q, K, V \in \mathbb{R}^{N \times d}\)를 이용하여 \(O \in \mathbb{R}^{N \times d}\)를 구한다.
\[S = QK^\top \in \mathbb{R}^{N \times N}, \quad P = \text{softmax}(S) \in \mathbb{R}^{N \times N}, \quad O = PV \in \mathbb{R}^{N \times d}\]이때 softmax는 row-wise operation이다. 보통의 attention은 \(O(N^2)\)의 memory cost를 사용하는데, 대다수의 경우에는 \(N \gg d\)를 만족한다 (GPT-2: N=1024, d=64).

Standard attention의 HBM 접근 패턴을 정리하면:
- \(Q, K\)를 HBM에서 읽어 \(S = QK^\top\)을 계산하고 \(S\)를 HBM에 쓴다 — \(\Theta(N^2)\)
- \(S\)를 HBM에서 읽어 \(P = \text{softmax}(S)\)를 계산하고 \(P\)를 HBM에 쓴다 — \(\Theta(N^2)\)
- \(P, V\)를 HBM에서 읽어 \(O = PV\)를 계산하고 \(O\)를 HBM에 쓴다 — \(\Theta(N^2)\)
총 HBM 접근: \(\Theta(Nd + N^2)\). \(N \times N\) 크기의 \(S, P\)를 HBM에 읽고 쓰는 것이 지배적이다.
FlashAttention
FlashAttention은 Tiling과 Recomputation을 사용하여 HBM 접근을 최소화한다.
Tiling: Online Softmax
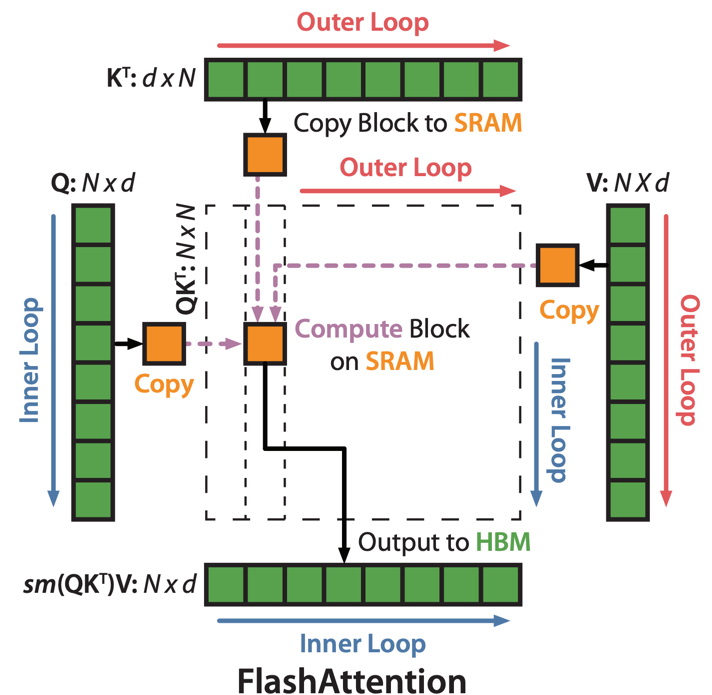
Tiling의 핵심 난관은 softmax이다. Softmax는 전체 row를 봐야 계산할 수 있기 때문에, \(S\)의 일부 블록만으로는 정확한 softmax를 구할 수 없다. FlashAttention은 online softmax 알고리즘으로 이를 해결한다.
Safe Softmax
먼저 수치 안정성을 위한 safe softmax를 정의한다. 벡터 \(x \in \mathbb{R}^B\)에 대해:
\[m(x) := \underset{i}{\max}(x_i), \quad f(x) := [e^{x_1 - m(x)}, \ldots, e^{x_B - m(x)}]\] \[l(x) := \sum_i f(x)_i, \quad \text{softmax}(x) := \frac{f(x)}{l(x)}\]최대값 \(m(x)\)를 빼서 overflow를 방지하면서도, 결과는 일반 softmax와 동일하다.
Softmax의 블록 분해
핵심 관찰: 벡터 \(x^{(1)}, x^{(2)} \in \mathbb{R}^B\)의 concatenation \(x = [x^{(1)}, x^{(2)}]\)에 대해, softmax를 각 블록의 통계량만으로 계산할 수 있다.
\[m(x) = m([x^{(1)}, x^{(2)}]) = \max(m(x^{(1)}), m(x^{(2)}))\] \[f(x) = [e^{m(x^{(1)}) - m(x)} f(x^{(1)}), \; e^{m(x^{(2)}) - m(x)} f(x^{(2)})]\] \[l(x) = e^{m(x^{(1)}) - m(x)} l(x^{(1)}) + e^{m(x^{(2)}) - m(x)} l(x^{(2)})\] \[\text{softmax}(x) = \frac{f(x)}{l(x)}\]이 분해의 핵심은 보정 계수 \(e^{m(x^{(1)}) - m(x)}\)이다. 블록 1을 처리할 때 max가 \(m(x^{(1)})\)이었는데, 블록 2를 보고 나서 전체 max \(m(x)\)가 바뀌면, 블록 1에서 계산한 값을 보정해야 한다. 이 보정이 있기 때문에 블록을 순차적으로 처리하면서도 정확한 softmax를 얻을 수 있다.
Output도 점진적으로 누적
Softmax뿐 아니라 output \(O = PV\)도 블록 단위로 누적할 수 있다. 블록 1을 처리한 후의 partial output:
\[O^{(1)} = \text{diag}(l^{(1)})^{-1} e^{S^{(1)} - m^{(1)}} V^{(1)}\]블록 2를 처리한 후, 전체 max가 \(m\)으로 바뀌면:
\[O^{(2)} = \text{diag}(l^{(1)}/l^{(2)})^{-1} O^{(1)} + \text{diag}(l^{(2)})^{-1} e^{S^{(2)} - m^{(2)}} V^{(2)}\]즉, 이전 결과에 보정 계수를 곱하고 새로운 블록의 기여를 더한다. 이 과정을 \(T_c\)개의 블록에 대해 반복하면 정확한 \(O\)를 얻는다.
Algorithm 1: FlashAttention Forward Pass
입력: \(Q, K, V \in \mathbb{R}^{N \times d}\) (HBM에 저장됨), SRAM 크기 \(M\)
- 블록 크기를 설정한다: \(B_c = \lceil M / 4d \rceil\), \(B_r = \min(\lceil M / 4d \rceil, d)\)
- SRAM에 \(K, V\)의 한 블록(\(B_c \times d\))과 \(Q, O\)의 한 블록(\(B_r \times d\))을 동시에 올릴 수 있어야 한다.
- \(Q\)를 \(T_r = \lceil N / B_r \rceil\)개, \(K, V\)를 \(T_c = \lceil N / B_c \rceil\)개 블록으로 나눈다.
- \(O = (0)_{N \times d}\), \(l = (0)_N\), \(m = (-\infty)_N\)을 HBM에 초기화한다.
- Outer loop: \(j = 1, \ldots, T_c\)에 대해:
- \(K_j, V_j\)를 HBM에서 SRAM으로 로드한다.
- Inner loop: \(i = 1, \ldots, T_r\)에 대해:
- \(Q_i, O_i, l_i, m_i\)를 HBM에서 SRAM으로 로드한다.
- SRAM에서 \(S_{ij} = Q_i K_j^\top \in \mathbb{R}^{B_r \times B_c}\) 계산
- SRAM에서 \(\tilde{m}_{ij} = \text{rowmax}(S_{ij}) \in \mathbb{R}^{B_r}\) 계산
- SRAM에서 \(\tilde{P}_{ij} = \exp(S_{ij} - \tilde{m}_{ij}) \in \mathbb{R}^{B_r \times B_c}\) 계산
- SRAM에서 \(\tilde{l}_{ij} = \text{rowsum}(\tilde{P}_{ij}) \in \mathbb{R}^{B_r}\) 계산
- SRAM에서 \(m_i^{\text{new}} = \max(m_i, \tilde{m}_{ij})\) 계산
- SRAM에서 \(l_i^{\text{new}} = e^{m_i - m_i^{\text{new}}} l_i + e^{\tilde{m}_{ij} - m_i^{\text{new}}} \tilde{l}_{ij}\) 계산
- SRAM에서 \(O_i \leftarrow \text{diag}(l_i^{\text{new}})^{-1} (\text{diag}(l_i) e^{m_i - m_i^{\text{new}}} O_i + e^{\tilde{m}_{ij} - m_i^{\text{new}}} \tilde{P}_{ij} V_j)\)
- \(m_i \leftarrow m_i^{\text{new}}\), \(l_i \leftarrow l_i^{\text{new}}\) 업데이트
- \(O_i, m_i, l_i\)를 HBM에 저장한다.
- \(O\)를 반환한다.

Theorem 1. Algorithm 1은 \(O = \text{softmax}(QK^\top)V\)를 \(O(N^2 d)\) FLOPs로 정확히 계산하며, 입력과 출력 외에 \(O(N)\)의 추가 메모리만 사용한다.
Standard attention과 동일한 FLOPs이지만, HBM 접근 패턴이 완전히 다르다. \(N \times N\) 크기의 \(S, P\)를 HBM에 저장하지 않고, SRAM에서 블록 단위로 처리하기 때문이다.
블록 크기 선택
블록 크기 \(B_c = \lceil M / 4d \rceil\)는 SRAM 용량 \(M\)에 의해 결정된다. SRAM에 동시에 올려야 하는 것은:
- \(K_j\) 블록: \(B_c \times d\)
- \(V_j\) 블록: \(B_c \times d\)
- \(Q_i\) 블록: \(B_r \times d\)
- \(O_i\) 블록: \(B_r \times d\)
총 SRAM 사용량 \(\approx 2 B_c d + 2 B_r d\)가 \(M\) 이하여야 한다. A100의 SRAM이 192KB이고 FP16 기준 \(d = 64\)이면, 블록 크기는 약 \(B_c = B_r = 128\) 정도가 된다.
Recomputation: Backward에서 메모리 절약
Standard attention의 backward pass에서는 \(dQ, dK, dV\)를 계산하기 위해 \(S, P \in \mathbb{R}^{N \times N}\)이 필요하다. 이를 forward에서 저장하면 \(O(N^2)\)의 메모리가 필요하다.
FlashAttention은 \(S, P\)를 저장하지 않는 대신, backward 때 다시 계산한다. Forward에서 저장하는 것은 softmax normalization statistics \((m, l)\)뿐이며, 이는 \(O(N)\)의 메모리만 사용한다.
Backward에서 \(S_{ij} = Q_i K_j^\top\)를 다시 계산하고, 저장해둔 \((m_i, l_i)\)를 이용하여 \(P_{ij}\)를 복원한다.
\[P_{ij} = \text{diag}(l_i)^{-1} \exp(S_{ij} - m_i)\]이로 인해 FLOPs는 증가하지만 (forward의 matmul을 backward에서 다시 수행), HBM 접근이 크게 줄어들어 실제 속도는 오히려 빨라진다. 이것이 FlashAttention의 핵심 통찰이다: 연산은 싸고 메모리 접근이 비싸므로, 연산을 더 하더라도 메모리 접근을 줄이는 것이 이득이다.
IO Complexity Analysis
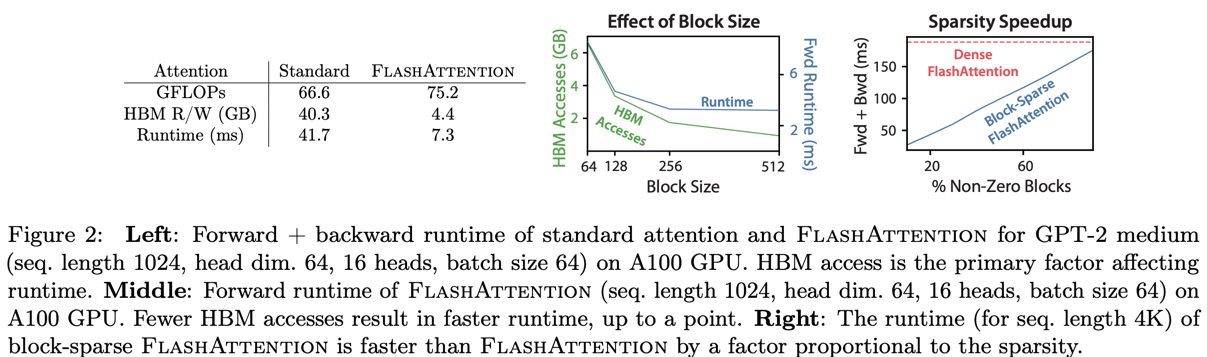
FlashAttention은 standard보다 GFLOPs는 많지만, HBM read and write가 적어 runtime이 개선되었다.
Theorem 2. Sequence length \(N\), head dimension \(d\), SRAM 크기 \(M\) (\(d \leq M \leq Nd\))에 대해, Standard attention은 \(\Theta(Nd + N^2)\)의 HBM 접근이 필요하고, FlashAttention은 \(\Theta(N^2 d^2 M^{-1})\)의 HBM 접근이 필요하다.
증명 직관
FlashAttention에서 outer loop은 \(T_c = N/B_c\)번, inner loop은 \(T_r = N/B_r\)번 반복된다. 각 inner iteration에서 \(Q_i\) (\(B_r \times d\))와 \(K_j, V_j\) (\(B_c \times d\))를 로드한다.
총 HBM 접근:
\[T_c \times T_r \times (B_r d + B_c d) = \frac{N}{B_c} \times \frac{N}{B_r} \times (B_r + B_c) d\]\(B_r, B_c = \Theta(M/d)\)를 대입하면:
\[\frac{N}{M/d} \times \frac{N}{M/d} \times \frac{M}{d} \times d = \frac{N^2 d^2}{M}\]Standard attention의 \(\Theta(Nd + N^2)\)와 비교하면, \(M\)이 클수록 (SRAM이 클수록) FlashAttention의 이점이 커진다. 일반적으로 \(d^2 \ll M\)이므로 FlashAttention이 유리하다.
Proposition 3. \(d \leq M \leq Nd\) 범위의 모든 \(M\)에 대해, exact attention을 \(o(N^2 d^2 M^{-1})\)의 HBM 접근으로 계산하는 알고리즘은 존재하지 않는다.
즉, FlashAttention의 IO 복잡도는 점근적으로 최적이다.
Extension: Block-Sparse FlashAttention
Block-sparse attention을 응용하여 block-sparse FlashAttention을 만들기도 했다. Sparsity mask \(\tilde{M}\)을 적용하여:
\[S = QK^\top \in \mathbb{R}^{N \times N}, \quad P = \text{softmax}(S \odot \mathbb{1}_{\tilde{M}}) \in \mathbb{R}^{N \times N}, \quad O = PV \in \mathbb{R}^{N \times d}\]FlashAttention의 outer loop에서 mask가 0인 블록은 건너뛰면 된다. 이 경우 IO 복잡도는:
Proposition 4. Block-sparse FlashAttention은 \(\Theta(N^2 d^2 M^{-1} s)\)의 HBM 접근이 필요하다. 여기서 \(s\)는 block-sparsity mask의 nonzero 블록 비율이다.
예를 들어 sparsity가 50%이면 IO도 절반으로 줄어든다. 기존 approximate attention 방법들은 FLOP은 줄여도 IO를 줄이지 못했는데, block-sparse FlashAttention은 IO도 비례하여 줄어든다.
Experiment
FlashAttention은 tiling을 통해 속도가 빠르고, recomputation을 통해 메모리가 줄어들었다. 이를 이용하여 sequence length를 늘릴 수 있었고, 이는 추가적인 성능 향상을 가져왔다.
BERT

BERT-large 학습 시 MLPerf 1.1 기준 학습 시간이 15% 개선되었다. 기존 최고 기록 대비 같은 정확도에 더 빠르게 도달한다.
GPT-2
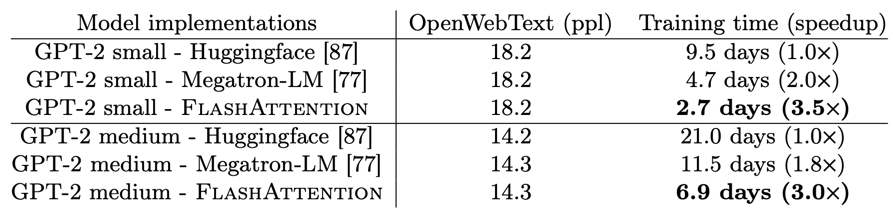
GPT-2 학습에서:
- Huggingface 구현 대비 3배 speed up
- Megatron-LM 대비 1.7배 speed up
- 메모리 사용량도 크게 줄어들어 같은 GPU에서 더 긴 시퀀스를 학습할 수 있다.
Long-range Arena
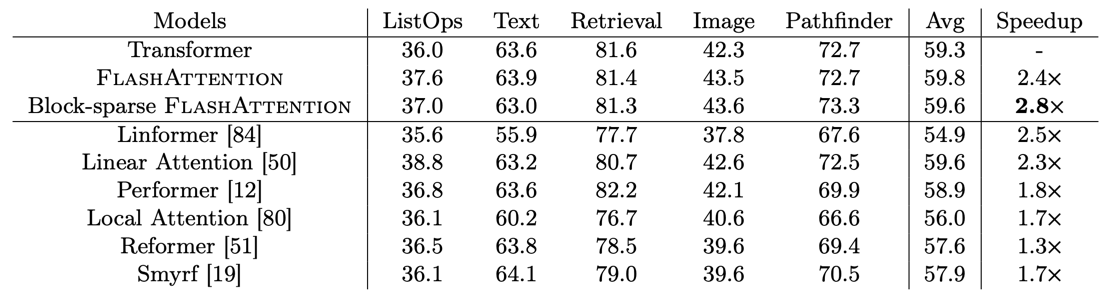
Long-range Arena(LRA) 벤치마크에서도 기존 대비 2.4배의 speed up을 보였으며, 다른 approximate attention method(Performer, Linear Attention 등)보다 정확도도 높았다. Exact attention이므로 근사 오차가 없기 때문이다.
Better Models with Longer Sequences
Language Modeling with Long Context

FlashAttention의 진정한 가치는 메모리 절약을 통해 더 긴 시퀀스를 다룰 수 있다는 점이다. Recomputation으로 메모리 사용량이 \(O(N)\)으로 줄어들면서 기존에는 OOM이 발생하던 긴 시퀀스도 학습할 수 있게 되었다. 더 긴 context를 볼 수 있으므로 perplexity도 개선된다.
Long Document Classification

긴 문서를 분류하는 태스크에서도 FlashAttention으로 시퀀스 길이를 늘릴 수 있어 성능이 향상되었다.
Path-X and Path-256

Path-X와 Path-256은 극단적으로 긴 시퀀스(16K, 64K)를 요구하는 태스크다. 기존의 모든 모델은 random 수준의 정확도(50%)를 보였다. FlashAttention은 이 태스크에서 random 이상의 결과를 가져온 최초의 transformer 모델이다. 메모리 제약 없이 긴 시퀀스를 처리할 수 있기 때문이다.
Benchmarking Attention
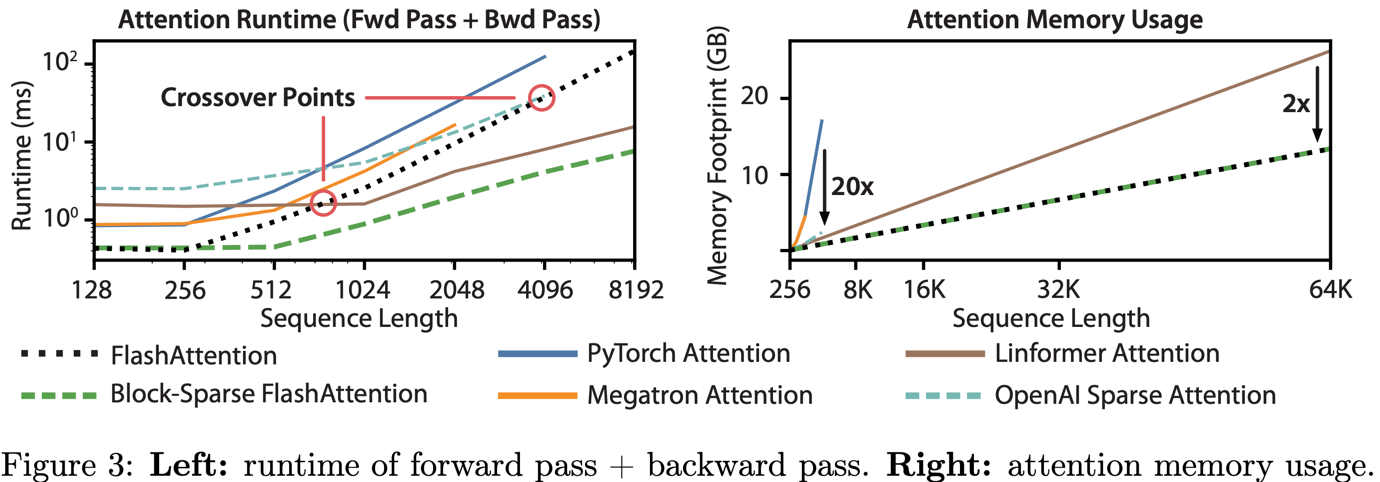
Standard Attention은 메모리 사용량이 \(O(N^2)\)이고, FlashAttention은 recomputation을 통해 \(O(N)\)으로 줄였다. Approximate attention(sparse attention) 역시 \(O(N)\)이다.
다만 sequence length가 매우 길어지면 approximate attention이 속도 면에서 유리할 수 있지만, exact attention인 FlashAttention이 정확도에서는 더 우수하다.
Limitation
FlashAttention은 CUDA kernel을 사용해야 하므로 상당한 엔지니어링이 필요하다. 새로운 attention variant(multi-query attention 등)를 지원하려면 커널을 새로 작성해야 한다. 그리고 GPU 아키텍처마다 최적의 블록 크기와 구현이 달라 이식성에 문제가 있다. 또한 현재는 single GPU를 기준으로 만들어졌으므로, multi-GPU에서의 attention 분산 처리는 별도의 알고리즘이 필요하다.
FlashAttention-2의 개선점이 궁금하다면 FlashAttention-2 논문 리뷰를, Hopper GPU에서의 최적화가 궁금하다면 FlashAttention-3 논문 리뷰를, Triton FA1으로 구현해보고 싶다면 Triton 05: Flash Attention을, Triton FA2로 구현해보고 싶다면 Triton 06: Flash Attention 2를 참고하자.
추가글…
아앗… 포스트를 올리고 4개월 만에 URL이 틀렸다는 것을 깨달았다… 하지만 어쩔 수 없다… 그냥 간다…
fastattentiondl 아니라 flashattention으로 해야 하는데….
Enjoy Reading This Article?
Here are some more articles you might like to read next: