FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (Dao, Princeton, arXiv 2023)
Introduction
GPT부터 시작해서 ViT 등 여러 분야에서 attention layer를 많이 쓰고 있다. 그런데 이 attention layer는 dimension의 제곱에 비례해서 계산 비용이 커서 모델의 병목이 될 수 있다. 그래서 attention layer를 효율적으로 만드는 여러 시도가 있는데, 그 중 하나가 FlashAttention이다. FlashAttention은 tiling과 kernel fusion을 사용해서 기존 attention layer보다 2~4배 더 빠르게 동작한다.
하지만 FlashAttention도 GPU의 이론적 성능에 비해 25~40%밖에 성능을 내지 못한다. A100 GPU의 이론 최대 312 TFLOPS/s 대비, FlashAttention은 약 72~120 TFLOPS/s 정도에 그친다. 최적화된 GEMM 커널이 80~90%를 달성하는 것과 비교하면 아직 많은 개선 여지가 있다.
저자는 FlashAttention의 비효율성을 분석하면서 세 가지 문제를 발견했다.
- non-matmul FLOPs가 많다: Attention에서 matmul이 아닌 연산(softmax의 rescaling, exp, max, sum 등)이 전체 FLOPs에서 상당한 비중을 차지한다. GPU의 matmul 처리량이 non-matmul 대비 최대 16배 빠르므로, non-matmul FLOPs를 줄이는 것이 중요하다.
- 병렬화가 부족하다: FlashAttention은 batch size와 head 수에 대해서만 병렬화한다. Batch가 작거나 head가 적으면 GPU의 SM을 충분히 활용하지 못한다.
- Warp 간 work partitioning이 비효율적이다: FlashAttention의 “split-K” 방식은 warp 간 불필요한 shared memory 읽기/쓰기와 동기화를 유발한다.
저자는 이 세 가지를 개선하여 FlashAttention 대비 약 2배 빠른 성능을 달성하고, A100에서 이론 성능의 50~73%까지 도달했다.
Background
Hardware Characteristics
GPU Performance Characteristics
GPU는 compute element와 memory hierarchy를 가지고 있다. Nvidia의 tensor core는 FP16/BF16 같은 저정밀도 matmul에 최적화되어 있다. A100 기준:
| 연산 | 처리량 |
|---|---|
| FP16/BF16 matmul | 312 TFLOPS/s |
| non-matmul FP32 | 19.5 TFLOPS/s |
matmul이 non-matmul보다 약 16배 빠르다. 따라서 전체 연산에서 non-matmul이 차지하는 비중이 크면, matmul을 아무리 빠르게 해도 성능이 제한된다. 이것이 FlashAttention의 첫 번째 문제이다.
메모리 계층 구조: A100 기준으로 40~80GB의 HBM은 1.5~2.0TB/s의 대역폭을 가지며, 108개의 stream multiprocessor는 각각 192KB의 on-chip SRAM을 갖고 있어 약 19TB/s의 대역폭을 제공한다. L2 캐시도 있지만, 이는 사용자가 컨트롤할 수 없어서 논의에서는 제외한다.
Execution Model
GPU의 실행 단위는 계층적이다.
- Thread: 가장 작은 실행 단위
- Warp: 32개 thread의 묶음. SIMT 방식으로 같은 명령을 동시 실행한다.
- Thread block: 여러 warp의 묶음. 하나의 SM에서 실행되며, shared memory(SRAM)를 공유한다.
- Grid: 전체 커널의 모든 thread block
Thread block 내의 warp들은 shared memory를 통해 통신할 수 있지만, 다른 thread block의 warp과는 통신할 수 없다. 따라서 한 thread block 내에서의 work partitioning이 성능에 큰 영향을 미친다.
Standard Attention Implementation
기존의 attention은 query, key, value들 간의 연산으로 구성된다. 시퀀스 길이를 \(N\), head dimension을 \(d\)라고 하자. Input sequence \(Q, K, V \in \mathbb{R}^{N \times d}\)에 대해 attention output \(O \in \mathbb{R}^{N \times d}\)를 계산하는 방식은 아래와 같다.
\[S = QK^\intercal \in \mathbb{R}^{N \times N}\] \[P = \text{softmax}(S) \in \mathbb{R}^{N \times N}\] \[O = PV \in \mathbb{R}^{N \times d}\]여기서 softmax는 row-wise로 적용된다.
Backward Pass
Backward pass는 아래 과정을 거친다.
\[dV = P^\intercal dO \in \mathbb{R}^{N \times d}\] \[dP = dO V^\intercal \in \mathbb{R}^{N \times N}\] \[dS = \text{dsoftmax}(dP) \in \mathbb{R}^{N \times N}\] \[dQ = dS \cdot K \in \mathbb{R}^{N \times d}\] \[dK = dS^\intercal \cdot Q \in \mathbb{R}^{N \times d}\]여기서 softmax의 gradient는 \(ds = (\text{diag}(p) - pp^\top) dp\)로 주어진다. 벡터 \(p = \text{softmax}(s)\)에 대해, 이는 다음과 같이 단순화할 수 있다.
\[dS_{ij} = P_{ij} (dP_{ij} - D_i), \quad D_i = \sum_j P_{ij} \cdot dP_{ij} = (P_i \circ dP_i)^\top \mathbf{1}\]\(D_i\)는 \(P\)의 \(i\)번째 행과 \(dP\)의 \(i\)번째 행의 element-wise 곱의 합이다. 이 \(D_i\) 값은 FlashAttention-2의 backward에서 중요한 역할을 한다.
FlashAttention 복습
FlashAttention의 구체적인 내용은 이전에 다뤘던 FlashAttention 1 포스트에서 참고할 수 있다.
Forward Pass
FlashAttention은 K와 V를 outer loop에서 순회하고, Q를 inner loop에서 순회한다. 각 iteration에서 on-line softmax를 통해 점진적으로 softmax를 적용하고, \(O\)를 누적한다. 구체적으로 두 블록을 처리하는 과정은 다음과 같다.
블록 1 처리:
\[m^{(1)} = \text{rowmax}(S^{(1)}) \in \mathbb{R}^{B_r}\] \[l^{(1)} = \text{rowsum}(e^{S^{(1)} - m^{(1)}}) \in \mathbb{R}^{B_r}\] \[\tilde{P}^{(1)} = \text{diag}(l^{(1)})^{-1} e^{S^{(1)} - m^{(1)}} \in \mathbb{R}^{B_r \times B_c}\] \[O^{(1)} = \tilde{P}^{(1)} V^{(1)} = \text{diag}(l^{(1)})^{-1} e^{S^{(1)} - m^{(1)}} V^{(1)} \in \mathbb{R}^{B_r \times d}\]블록 2 처리 (블록 1 결과를 보정):
\[m^{(2)} = \max(m^{(1)}, \text{rowmax}(S^{(2)})) = m\] \[l^{(2)} = e^{m^{(1)} - m^{(2)}} l^{(1)} + \text{rowsum}(e^{S^{(2)} - m}) = l\] \[O^{(2)} = \text{diag}(l^{(1)}/l^{(2)})^{-1} O^{(1)} + \text{diag}(l^{(2)})^{-1} e^{S^{(2)} - m^{(2)}} V^{(2)} = O\] 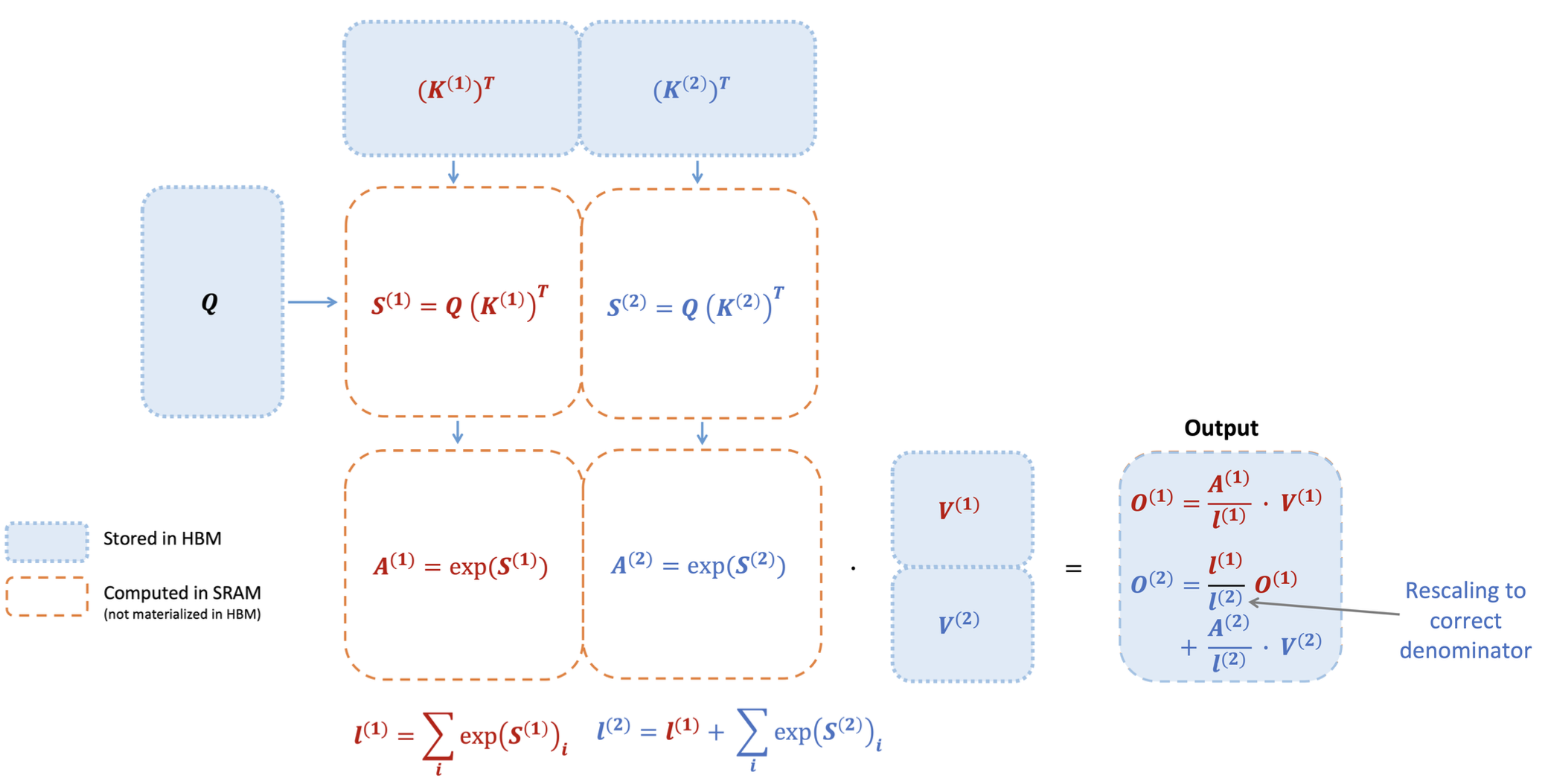
이 과정에서 매 블록마다 \(\text{diag}(l^{(1)}/l^{(2)})^{-1}\)로 이전 결과를 rescaling한다. 이 rescaling에 사용되는 \(\text{diag}(l)^{-1}\)가 non-matmul 연산이고, 매 iteration마다 수행되어 전체 FLOPs에서 상당한 비중을 차지한다. FlashAttention-2는 이 점을 개선한다.
Backward Pass
Backward pass에서는 forward에서 저장한 \(m\)과 \(l\)을 사용해서 \(S, P\)를 재계산(recomputation)할 수 있다.
FlashAttention-2
FlashAttention-2는 기존 FlashAttention보다 non-matmul FLOPs를 줄인다. A100 GPU 기준으로 FP16/BF16 matmul은 312 TFLOPS/s이지만, non-matmul 연산은 19.5 TFLOPS/s로 16배 느리다. 따라서 non-matmul 비중이 전체 성능을 좌우한다.
Forward Pass 개선
FlashAttention-2는 online softmax의 rescaling 방식을 변경하여 non-matmul FLOPs를 줄인다.
개선 1: Rescaling을 마지막에 한 번만
기존 FlashAttention에서는 매 블록마다 \(O_i\)에 \(\text{diag}(l_i)^{-1}\)를 곱해서 정규화된(normalized) output을 유지했다. 즉, 매 iteration마다 나누기 연산이 들어갔다.
FlashAttention-2에서는 정규화하지 않은 상태의 \(\tilde{O}\)를 유지하고, 모든 블록 처리가 끝난 후 마지막에 한 번만 \(\text{diag}(l)^{-1}\)을 곱한다.
기존 (FlashAttention):
\[O^{(1)} = \text{diag}(l^{(1)})^{-1} e^{S^{(1)} - m^{(1)}} V^{(1)}\] \[O^{(2)} = \text{diag}(l^{(1)}/l^{(2)})^{-1} O^{(1)} + \text{diag}(l^{(2)})^{-1} e^{S^{(2)} - m^{(2)}} V^{(2)}\]개선 (FlashAttention-2): 정규화하지 않은 \(\tilde{O}\)를 유지:
\[\tilde{O}^{(1)} = e^{S^{(1)} - m^{(1)}} V^{(1)}\] \[\tilde{O}^{(2)} = \text{diag}(e^{m^{(1)} - m^{(2)}}) \tilde{O}^{(1)} + e^{S^{(2)} - m^{(2)}} V^{(2)}\] \[O^{(2)} = \text{diag}(l^{(2)})^{-1} \tilde{O}^{(2)}\]이렇게 하면 매 iteration마다 \(\text{diag}(l)^{-1}\)을 곱하는 대신, \(\text{diag}(e^{m^{(1)} - m^{(2)}})\)만 곱하면 된다. 최종 나누기는 모든 블록 처리 후 한 번만 수행한다.
개선 2: \(m\)과 \(l\) 대신 \(L\)만 저장
Backward pass를 위해 FlashAttention은 \(m \in \mathbb{R}^N\)과 \(l \in \mathbb{R}^N\)을 각각 저장했다. FlashAttention-2에서는 이를 하나로 합친다.
\[L^{(j)} = m^{(j)} + \log(l^{(j)})\]이 \(L\)은 log-sum-exp 값으로, \(m\)과 \(l\)의 정보를 하나로 압축한다. Backward에서 softmax를 재계산할 때:
\[P_{ij} = \exp(S_{ij} - L_i)\]\(m\)과 \(l\)을 개별적으로 사용하는 것과 수학적으로 동일하지만, 저장 공간이 절반으로 줄고 HBM 접근도 줄어든다.
결과: FlashAttention-2 Forward 알고리즘

FlashAttention-2의 forward pass를 단계별로 정리하면:
- \(Q\)를 \(T_r = \lceil N/B_r \rceil\)개, \(K, V\)를 \(T_c = \lceil N/B_c \rceil\)개 블록으로 나눈다.
- Outer loop: \(i = 1, \ldots, T_r\)에 대해 (\(Q\) 블록 순회):
- \(O_i = (0)\), \(l_i = (0)\), \(m_i = (-\infty)\) 초기화
- Inner loop: \(j = 1, \ldots, T_c\)에 대해 (\(K, V\) 블록 순회):
- \[S_{ij} = Q_i K_j^\top\]
- \[m_{ij} = \text{rowmax}(S_{ij})\]
- \[\tilde{P}_{ij} = \exp(S_{ij} - m_{ij})\]
- \[l_{ij} = \text{rowsum}(\tilde{P}_{ij})\]
- \[m_i^{\text{new}} = \max(m_i, m_{ij})\]
- \[l_i^{\text{new}} = e^{m_i - m_i^{\text{new}}} l_i + e^{m_{ij} - m_i^{\text{new}}} l_{ij}\]
- \[O_i \leftarrow \text{diag}(e^{m_i - m_i^{\text{new}}}) O_i + e^{m_{ij} - m_i^{\text{new}}} \tilde{P}_{ij} V_j\]
- \(m_i \leftarrow m_i^{\text{new}}\), \(l_i \leftarrow l_i^{\text{new}}\)
- \(O_i \leftarrow \text{diag}(l_i)^{-1} O_i\) ← 마지막에 한 번만 정규화
- \[L_i \leftarrow m_i + \log(l_i)\]
FA1과의 핵심 차이점: outer loop과 inner loop의 순서가 바뀌었다!
| FlashAttention | FlashAttention-2 | |
|---|---|---|
| Outer loop | K, V 블록 (\(j\)) | Q 블록 (\(i\)) |
| Inner loop | Q 블록 (\(i\)) | K, V 블록 (\(j\)) |
FA1에서는 같은 \(K_j, V_j\)를 올려놓고 모든 \(Q_i\)를 순회했다. FA2에서는 하나의 \(Q_i\)를 올려놓고 모든 \(K_j, V_j\)를 순회한다. 이 변경이 왜 중요한지는 병렬화 섹션에서 설명한다.
Backward Pass

Backward에서도 비슷한 최적화를 적용한다. \(L\)을 사용하여 \(S, P\)를 재계산하고, \(D_i = \text{rowsum}(dO_i \circ O_i)\)를 미리 계산해둔다.
Backward의 loop 순서는 forward와 반대이다.
| Forward | Backward | |
|---|---|---|
| Outer loop | Q 블록 (\(i\)) | K, V 블록 (\(j\)) |
| Inner loop | K, V 블록 (\(j\)) | Q 블록 (\(i\)) |
이유: backward에서는 \(dK_j, dV_j\)를 누적해야 한다. \(K_j, V_j\)를 outer loop에 두면 하나의 thread block이 \(dK_j, dV_j\)를 독립적으로 계산할 수 있어서, thread block 간 동기화 없이 병렬 처리가 가능하다.
Parallelism: 시퀀스 길이 차원 병렬화
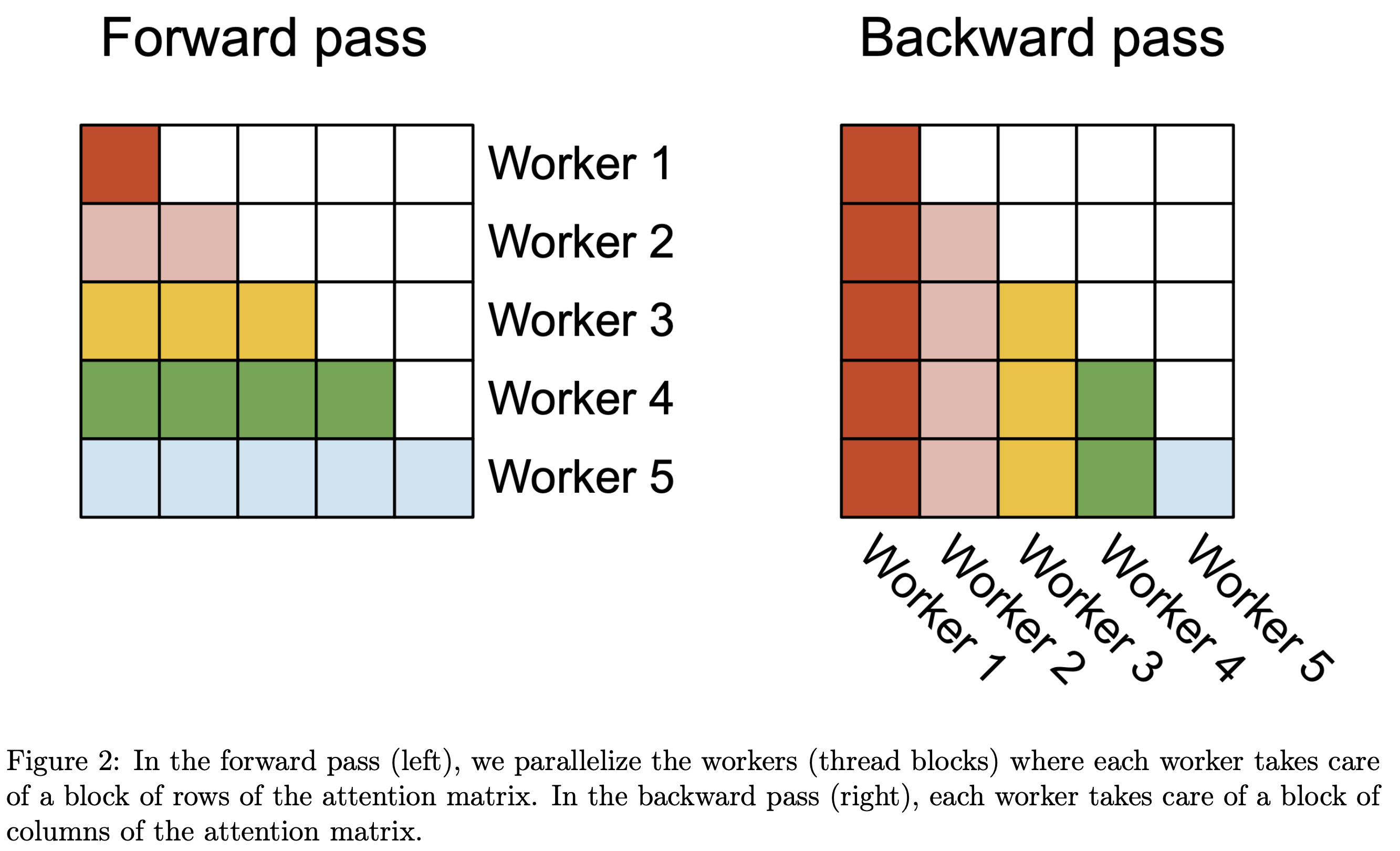
기본적으로 FlashAttention은 batch size와 head 수에 대해 thread block을 할당한다. GPU의 SM 수는 A100 기준 108개이므로, batch × heads ≥ 108이어야 GPU를 충분히 활용할 수 있다.
하지만 긴 시퀀스 + 작은 batch에서는 batch × heads가 108보다 작을 수 있다. 예를 들어 batch=1, heads=8이면 8개의 thread block만 활용되어 SM의 7%만 쓰게 된다.
Forward: Q 블록 병렬화
FlashAttention-2에서 outer loop을 Q 블록으로 바꾼 핵심 이유가 여기에 있다. 각 \(Q_i\)는 독립적으로 \(O_i\)를 계산하므로, \(T_r\)개의 Q 블록을 병렬로 처리할 수 있다. 따라서 총 thread block 수는:
\[\text{batch} \times \text{heads} \times T_r\]시퀀스가 길수록 \(T_r\)이 커져서 자동으로 병렬도가 높아진다.
FA1에서는 outer loop이 K, V였기 때문에 이런 병렬화가 불가능했다. K, V를 바꿀 때마다 모든 Q의 중간 결과를 업데이트해야 하므로, Q 블록 간에 의존성이 생기기 때문이다.
Backward: K, V 블록 병렬화
Backward에서는 outer loop이 K, V 블록이므로, 마찬가지로 \(T_c\)개의 블록을 병렬로 처리한다. 각 thread block은 \(dK_j, dV_j\)를 독립적으로 계산한다.
\(dQ\)는 모든 K, V 블록의 기여를 합산해야 하므로 thread block 간 동기화가 필요하다. 이를 위해 \(dQ\)를 atomic add로 누적하거나, 별도의 reduction 단계를 사용한다.
Work Partitioning Between Warps
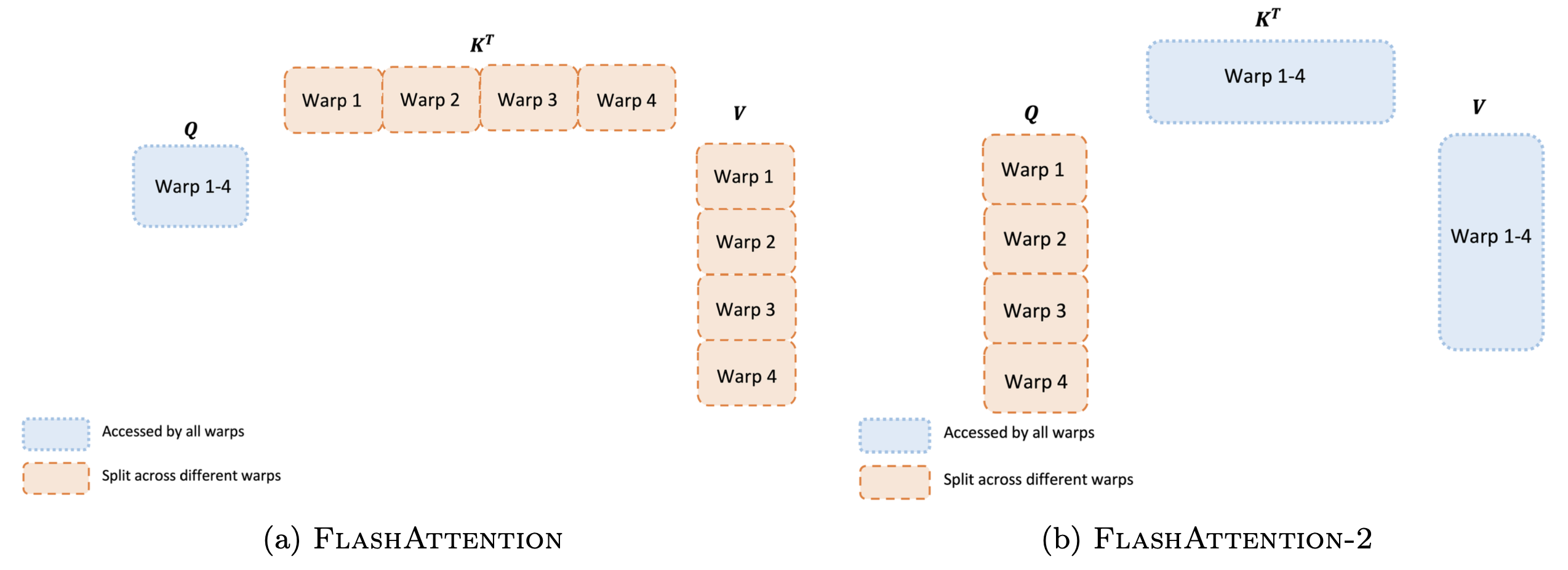
Thread block 내에서 여러 warp이 어떻게 작업을 나누느냐도 성능에 큰 영향을 미친다.
FlashAttention의 “Split-K” 방식
기존 FlashAttention에서는 \(K\)와 \(V\)를 warp 간에 나누고, \(Q\)는 모든 warp이 공유했다. 4개의 warp이 있다면, 각 warp이 \(K\)의 일부로 \(QK^\top\)의 일부를 계산한다.
문제: 각 warp이 \(QK^\top\)의 서로 다른 열 블록을 계산한 후, softmax를 위해 이들을 합쳐야 한다. 이 과정에서:
- 각 warp이 자기 결과를 shared memory에 쓴다
- 동기화 배리어 (\(\text{__syncthreads}\))
- 다른 warp의 결과를 shared memory에서 읽는다
- Reduction으로 max, sum을 계산한다
이 shared memory 읽기/쓰기와 동기화가 반복되어 overhead가 크다.
FlashAttention-2의 “Split-Q” 방식
FlashAttention-2에서는 \(Q\)를 warp 간에 나누고, \(K\)와 \(V\)는 모든 warp이 공유한다. 4개의 warp이 있다면, 각 warp이 \(Q\)의 서로 다른 행 블록을 담당한다.
장점: 각 warp이 독립적인 행을 담당하므로, softmax를 위한 warp 간 통신이 전혀 필요 없다. Softmax는 row-wise 연산이기 때문에, 자기가 담당하는 행에 대해서만 계산하면 된다. \(K, V\)는 shared memory에 한 번 올려놓으면 모든 warp이 읽기만 하면 되므로 동기화도 필요 없다.
결과적으로 warp 간 shared memory 쓰기와 동기화가 사라져서, 실제 속도가 크게 향상된다.
Backward에서의 Warp Partitioning
Backward에서도 “split-K”를 피하고, 각 warp이 독립적으로 작업할 수 있도록 partitioning한다. 구체적으로, 각 warp이 \(K, V\)의 서로 다른 열 블록을 담당하여 \(dQ\)의 일부를 독립적으로 계산한다.
Tuning Block Sizes
Block size를 늘리면 memory IO가 줄어든다. 하지만 두 가지 제약이 있다.
-
레지스터 압력: 블록이 커지면 각 thread가 보관해야 할 intermediate 값이 많아져서 레지스터가 부족해진다. 레지스터가 부족하면 register spilling이 발생하여 값을 local memory(실제로는 HBM)에 저장해야 하므로 속도가 크게 떨어진다.
-
Shared memory 크기: \(K, V\) 블록을 shared memory에 올려야 하므로, 블록 크기가 SM당 shared memory 용량(A100: 192KB)을 초과하면 안 된다. Shared memory를 많이 쓰면 SM당 동시 실행 가능한 thread block 수(occupancy)도 줄어든다.
따라서 GPU마다 최적의 block size가 다르며, 실험적으로 튜닝해야 한다. A100에서는 보통 \(B_r = B_c = 128\) (head dim 64) 또는 \(B_r = 64, B_c = 128\) (head dim 128) 정도가 최적이다.
Causal Masking 최적화
Autoregressive 모델(GPT 등)에서는 미래 토큰을 볼 수 없으므로 causal mask를 적용한다. FlashAttention-2에서는 Q의 행 인덱스가 K의 열 인덱스보다 작은 블록은 전체가 mask되므로, 해당 블록의 연산을 완전히 건너뛴다. 이렇게 하면 causal attention의 연산량이 non-causal 대비 약 절반으로 줄어든다.
Empirical Validation
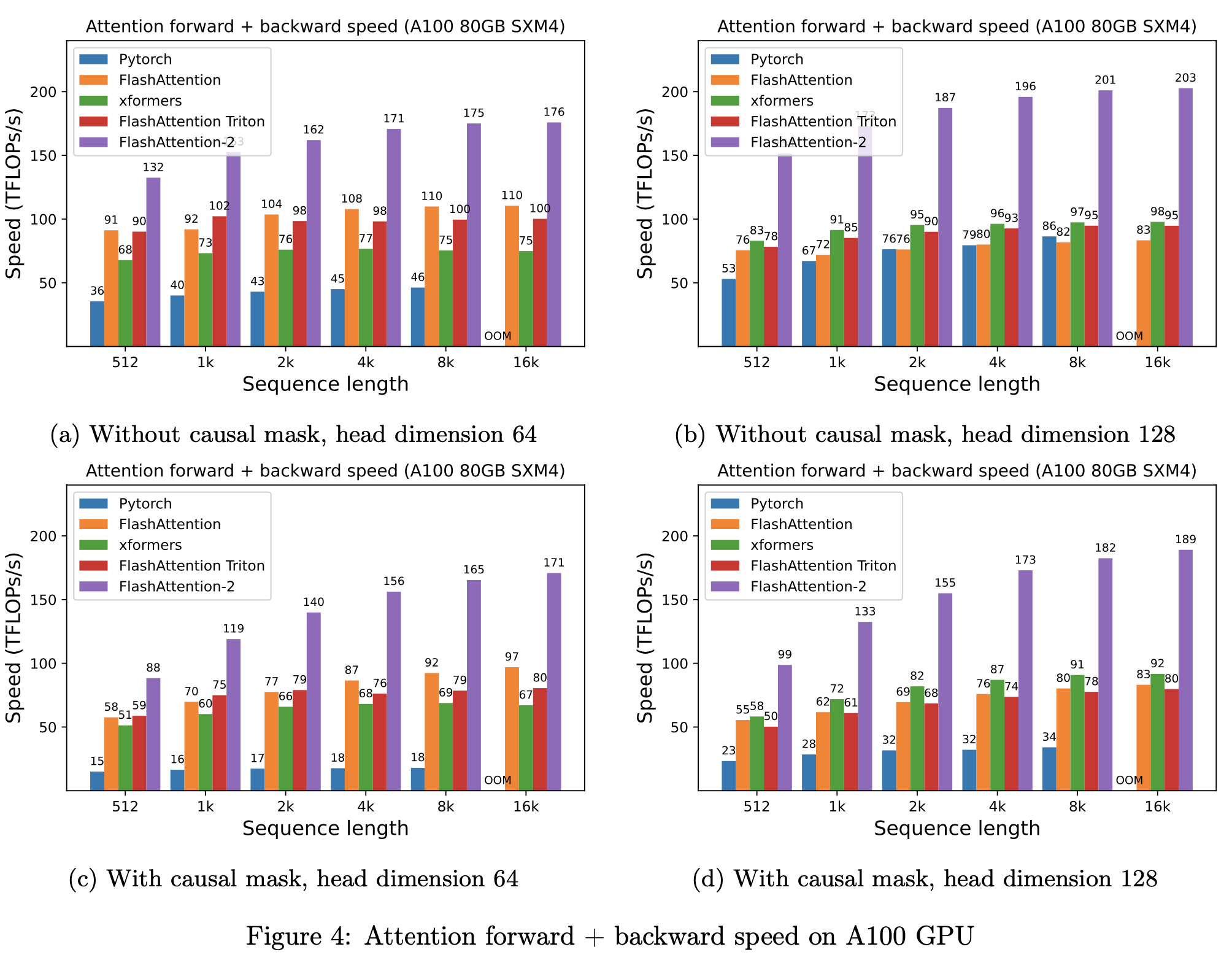
A100 80GB SXM GPU에서 다양한 설정으로 벤치마크를 수행했다.
벤치마크 결과
FlashAttention-2는 FlashAttention, xFormers 대비 약 2배의 speed up을 보였다. 구체적으로:
- Head dim 64, seqlen 2K: FlashAttention ~130 TFLOPS → FlashAttention-2 ~220 TFLOPS
- Head dim 128, seqlen 2K: FlashAttention ~135 TFLOPS → FlashAttention-2 ~230 TFLOPS
- Causal masking 적용 시 최대 2.7배 speed up (건너뛸 수 있는 블록이 많아짐)
GPT 스타일 학습 기준으로 A100당 225 TFLOPS/s, 모델 FLOPs utilization 72%를 달성했다. 이론 최대 312 TFLOPS 대비 약 72%로, FlashAttention의 25~40% 대비 크게 향상되었다.
FlashAttention vs FlashAttention-2 요약
| FlashAttention | FlashAttention-2 | |
|---|---|---|
| Rescaling | 매 블록마다 정규화 | 마지막에 한 번만 |
| Logsumexp 저장 | \(m, l\) 별도 저장 | \(L = m + \log(l)\) 합쳐서 저장 |
| Forward outer loop | K, V 블록 | Q 블록 |
| Backward outer loop | Q 블록 | K, V 블록 |
| Warp partitioning | Split-K (통신 필요) | Split-Q (통신 불필요) |
| 시퀀스 병렬화 | 없음 | 있음 |
| A100 활용률 | 25~40% | 50~73% |
| 성능 | 72~120 TFLOPS | ~230 TFLOPS |
Conclusion
FlashAttention-2는 기존 FlashAttention을 세 가지 측면에서 개선했다. Non-matmul FLOPs를 줄이고, 시퀀스 길이 차원으로 병렬화를 추가하고, warp 간 통신을 제거하여 약 2배의 speed up을 달성했다. 이를 통해 A100에서 이론 성능의 50~73%까지 도달할 수 있었다.
다만 A100에서도 여전히 이론 최대와 gap이 있으며, 이는 주로 non-matmul 연산(softmax의 exp, max, sum)이 matmul 대비 16배 느리기 때문이다. 이 문제는 FlashAttention-3에서 Hopper GPU의 비동기 실행을 통해 GEMM과 softmax를 겹치는 방식으로 해결된다.
FlashAttention의 원리가 궁금하다면 FlashAttention 논문 리뷰를, Hopper GPU 최적화가 궁금하다면 FlashAttention-3 논문 리뷰를, Blackwell GPU 최적화가 궁금하다면 FlashAttention-4 논문 리뷰를, Triton FA1으로 구현하고 싶다면 Triton 05: Flash Attention을, Triton FA2로 구현하고 싶다면 Triton 06: Flash Attention 2를 참고하자.
Enjoy Reading This Article?
Here are some more articles you might like to read next: