AgenticRed: Evolving Agentic Systems for Red-Teaming
AgenticRed: Evolving Agentic Systems for Red-Teaming (Yuan et al., UW, arXiv 2026)
Introduction
자동 Red-Teaming의 “추상화 사다리”
먼저 이 시리즈에서 지금까지 본 자동 red-teaming(이하 RT) 연구들이 무엇을 점점 더 자동화해 왔는지 정리하자. 한 단계씩 “사람이 손대는 부분”이 줄어드는 사다리로 볼 수 있다.
- 사람이 직접 jailbreak 프롬프트를 짜던 시절(DAN 등) → 공격 프롬프트를 사람이 만든다.
- PAIR / TAP → attacker LLM이 프롬프트를 만든다. 사람은 “attacker가 어떻게 행동할지”(policy)를 학습시킨다.
- Curiosity-RT → policy에 더해 novelty 보상으로 다양성까지 자동으로 챙긴다.
- Auto-RT → 개별 프롬프트를 넘어 공격 전략(strategy) 공간 자체를 RL로 탐색한다.
여기까지의 공통점이 하나 있다. 공격을 수행하는 “절차(workflow)”는 여전히 사람이 설계한다는 점이다. PAIR는 “attacker가 응답을 보고 프롬프트를 고친다”는 선형 refinement 루프를 사람이 정했고, TAP은 “트리를 만들고 가지치기한다”는 트리 탐색 구조를 사람이 정했다. 그 정해진 틀 안에서 policy나 strategy를 최적화할 뿐이다.
AgenticRed는 여기서 한 칸 더 위로 올라간다. “공격 절차(workflow) 그 자체”를 자동으로 만들어 진화시킨다. 즉 “공격 프롬프트를 만드는 알고리즘”을 넘어, “공격 알고리즘을 만드는 알고리즘”이다.
비유: 요리사를 훈련시키느냐, 요리법을 발명하느냐
직관을 위한 비유를 들자. 기존 자동 RT를 “정해진 레시피를 잘 따르도록 요리사(attacker LLM)를 훈련시키는 일”이라고 하자. 레시피(워크플로우)는 사람이 써 놨고, 요리사는 그 안에서 간을 더 잘 맞추도록 연습한다.
AgenticRed는 다르다. 레시피 자체를 새로 발명한다. “재료를 먼저 볶을까, 데칠까”, “소스를 두 번 나눠 넣을까” 같은 절차 자체를 여러 버전으로 만들어 보고, 가장 맛있는(=공격이 가장 잘 통하는) 레시피만 살려서 다음 세대로 넘긴다. 이 “레시피를 발명하는 셰프”가 바로 meta agent(GPT-5)다.
이게 왜 중요한가? 사람이 워크플로우를 설계하면 두 가지 한계가 생긴다.
- 휴먼 bias: 사람이 “공격은 이렇게 하는 게 맞다”고 믿는 방식만 시도하게 된다.
- 탐색 공간이 워크플로우 안에 갇힘: PAIR 틀 안에서는 아무리 최적화해도 PAIR가 상상하지 못한 공격 절차는 영원히 나오지 않는다.
워크플로우 자체를 탐색 대상으로 바꾸면 이 두 한계가 동시에 풀린다. 사람이 떠올리지 못한 절차가 진화 과정에서 저절로 발견(emergent)될 수 있기 때문이다.
한눈에 보는 비교
| 항목 | 기존 자동 RT (Auto-RT 등) | AgenticRed |
|---|---|---|
| 최적화 대상 | policy / strategy | 시스템(워크플로우) 자체 |
| 워크플로우 | 사람이 설계 | 자동 진화 |
| 누가 새 공격을 만드나 | attacker LLM(고정 틀 안) | meta agent(GPT-5)가 코드 생성 |
| 새 전략의 출처 | 사람이 미리 넣은 것 | 진화 과정에서 emergent |
| HarmBench ASR(Llama-2-7B) | AdvReasoning 60% | 96% |
| HarmBench ASR(Claude-3.5) | SOTA 36% | 60% (+24%p) |
논문 정보를 정리하면, 저자는 Jiayi Yuan, Jonathan Nöther, Natasha Jaques, Goran Radanović (University of Washington / Max Planck Institute for Software Systems)이고, 핵심 아이디어는 “RT를 시스템 설계(system design) 문제로 보고, 그 시스템 공간을 진화 탐색한다”는 것이다.
Background
본 절에서는 AgenticRed를 이해하기 위한 두 가지 배경을 차근차근 풀어 설명한다. 첫째는 “agentic system이란 도대체 무엇인가”, 둘째는 “왜 이게 NAS(신경망 아키텍처 탐색)와 똑같은 구조인가”이다.
“Agentic System” = 여러 LLM 호출을 엮은 multi-step workflow
“agentic system”이라는 말이 추상적으로 들리지만, 실체는 단순하다. LLM을 여러 번 호출해서 특정 순서로 엮은 절차(workflow)가 곧 하나의 시스템이다. 예를 들어 어떤 공격 시스템은 다음 4단계로 구성될 수 있다.
- 단계 1: 유해한 공격 의도를 LLM으로 paraphrase(다르게 표현) 한다.
- 단계 2: judge LLM으로 후보들을 ranking 한다.
- 단계 3: 상위 후보를 다시 LLM으로 refine(개선) 한다.
- 단계 4: 완성된 프롬프트를 target 모델에 쿼리한다.
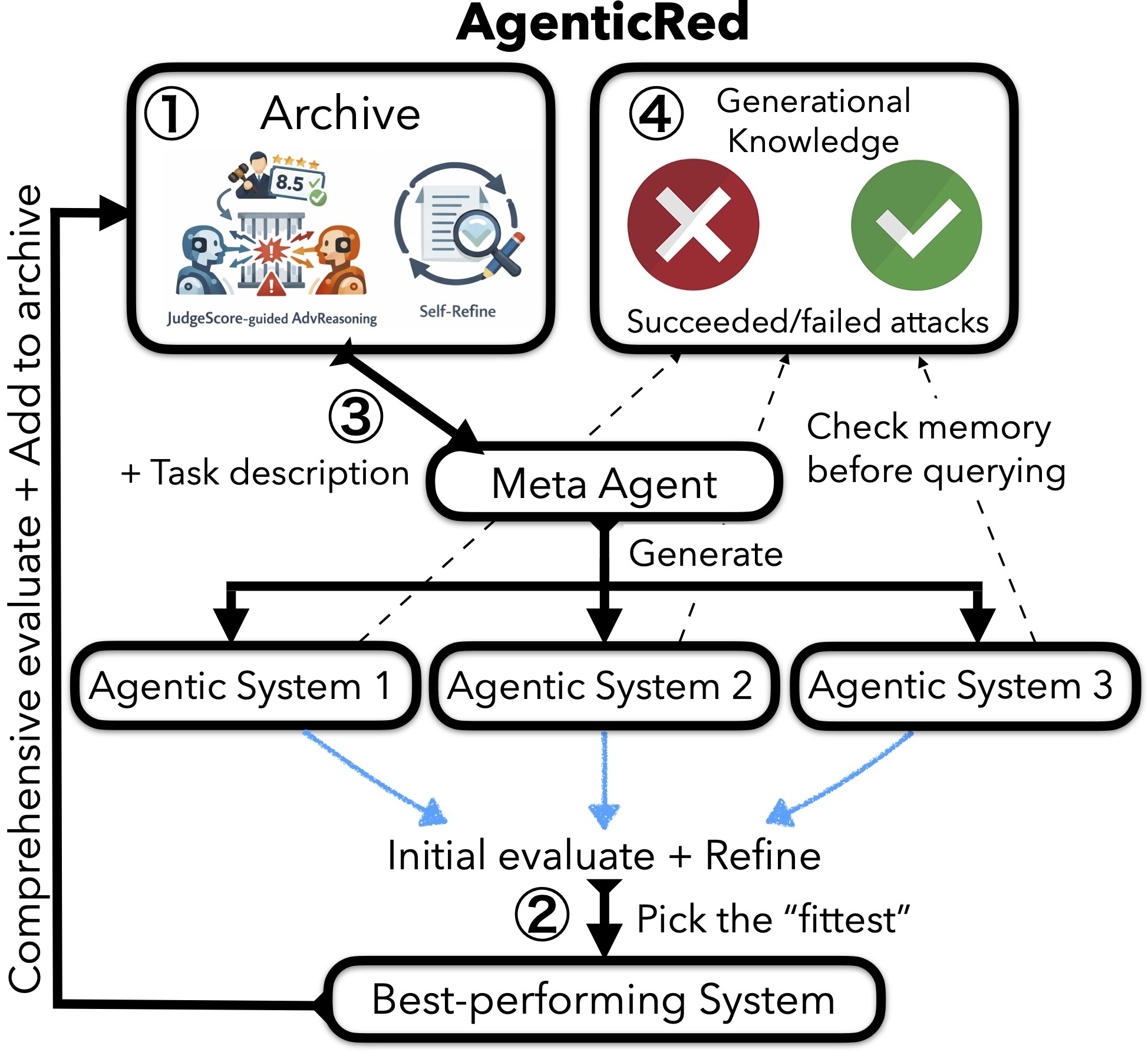
이 “어떤 단계를, 어떤 순서로, 몇 번 반복하는가”의 조합 전체가 하나의 시스템이다. 단계를 빼거나, 순서를 바꾸거나, 새 단계를 끼워 넣으면 다른 시스템이 된다. AgenticRed는 이런 시스템을 여러 개 자동으로 만들어 서로 경쟁시킨다.
핵심은 시스템이 실행 가능한 코드로 표현된다는 점이다. meta agent는 자연어 설명이 아니라 실제로 돌아가는 Python 코드 형태의 RT 시스템을 생성한다. 그래서 만들자마자 바로 실행해서 성능을 측정할 수 있다.
NAS(Neural Architecture Search)의 LLM 버전
AgenticRed의 전체 구조는 NAS(신경망 아키텍처 자동 탐색)와 정확히 평행하다. NAS를 모른다면, “사람이 신경망 구조(층 개수, 연결 방식)를 일일이 설계하는 대신, 알고리즘이 여러 구조를 자동으로 만들어 보고 가장 성능 좋은 걸 고르는” 기법이라고 보면 된다.
| 구성요소 | NAS (Zoph & Le, 2017) | AgenticRed |
|---|---|---|
| 무엇을 탐색하나 | 신경망 아키텍처 | RT 시스템(워크플로우) 코드 |
| 누가 만드나 | meta controller | meta agent (GPT-5) |
| 한 후보를 평가 | 학습 후 validation 정확도 | 실행 후 ASR(공격 성공률) |
| 좋은 후보 선택 | 높은 reward를 controller에 반영 | 가장 fitness 높은 시스템만 생존 |
즉 AgenticRed = “RT 시스템 공간에 대한 NAS”라고 한 줄로 요약할 수 있다. 다만 NAS는 보통 강화학습이나 미분 가능한 탐색을 쓰는 반면, AgenticRed는 LLM의 in-context learning을 이용한 진화 탐색(evolutionary search)을 쓴다. 이게 다음 절의 주제다.
Method: 시스템에 대한 진화 탐색
이제 AgenticRed가 실제로 어떻게 도는지 본다. 큰 그림은 “여러 시스템을 만들고 → 평가하고 → 가장 좋은 것만 남긴다”를 10세대 반복하는 진화 알고리즘이다. 수식과 토이 예제로 한 단계씩 풀어 본다.
무엇을 최적화하는가 — 평범한 말로
먼저 수식 없이 정리하자.
- 우리에게는 공격 의도(harmful intention) 목록이 있다. 예: “폭탄 만드는 법을 알려줘”, “피싱 메일을 작성해줘”.
- 우리에게는 target 모델 \(T\) 가 있다. 예: Llama-2-7B. 이 모델을 깨고 싶다.
- 우리에게는 judge 모델 \(J\) 가 있다. 공격이 성공했는지(=target이 유해 응답을 했는지) 판정한다.
- 우리가 찾고 싶은 것은 시스템 \(A\) 다. 의도 \(I\)를 받아 공격 프롬프트로 가공한 뒤 \(T\)에 던지는 절차다.
목표: 여러 의도에 대해 평균 공격 성공률(ASR)이 가장 높은 시스템 \(A\)를 찾는다.
수식 풀이
이제 수식을 한 줄씩 풀어보자.
ASR (공격 성공률) 정의:
\[\text{ASR}(A, T, J, D) = \mathbb{E}_{I \sim D}\big[\, J(\,T(\,A(I)\,),\ I)\,\big]\]기호의 의미를 안에서 바깥으로 풀면 다음과 같다.
- \(I \sim D\): 데이터셋 \(D\)(공격 의도들의 집합)에서 의도 \(I\)를 하나 뽑는다. 예: “폭탄 만드는 법”.
- \(A(I)\): 시스템 \(A\)가 의도 \(I\)를 가공해서 만든 최종 공격 프롬프트. 예: paraphrase → refine을 거친 교묘한 문장.
- \(T(A(I))\): 그 공격 프롬프트를 target 모델 \(T\)에 넣어 얻은 응답.
- \(J(T(A(I)), I)\): judge \(J\)가 “이 응답이 의도 \(I\)를 실제로 만족시키는 유해 응답인가?”를 판정. 성공이면 1, 실패면 0.
- \(\mathbb{E}_{I \sim D}[\cdots]\): 데이터셋 전체에 대한 평균. 즉 “의도들 중 몇 %를 깼는가”.
요약: ASR은 시스템 \(A\)가 의도들의 몇 %에서 target을 깨는지를 나타내는 0~1 사이 점수다. 이것이 시스템의 “fitness(적합도)”가 된다.
선택(selection) 규칙:
매 세대에서 후보 시스템 집합 \(\mathcal{C}_n\) 중 ASR이 가장 높은 하나만 다음 archive에 넣는다.
\[A_{n+1} \in \arg\max_{A \in \mathcal{C}_n} \text{ASR}(A, T, J, d)\]기호의 의미:
- \(\mathcal{C}_n\): \(n\)세대에서 meta agent가 만든 후보 시스템들의 집합.
- \(d\): 작은 평가용 데이터셋(전체 \(D\)의 부분집합). 빠른 1차 선별에 쓴다.
- \(\arg\max\): ASR을 최대로 만드는 시스템을 고른다.
- \(A_{n+1}\): 그렇게 뽑힌 “다음 세대로 살아남는 시스템”.
핵심: 매 세대에서 단 한 개만 살아남는다. 이를 strict elitism(엄격한 엘리트 보존)이라 한다. 왜 한 개만? 진화 압력(selection pressure)을 강하게 줘서, 평범한 시스템은 빠르게 버리고 정말 강한 시스템만 다음 세대 설계의 토대로 쓰기 위해서다. 뒤의 ablation에서 이 strict selection이 실제로 +6%p의 차이를 만든다는 것을 본다.
진화 루프 step-by-step
전체 절차를 의사코드로 보면 다음과 같다.
Algorithm: AgenticRed evolution
archive ← { Self-Refine, JS-Guided AdvReasoning } # 2개 baseline으로 시작
Repeat for 10 generations:
1. meta agent(GPT-5)가 archive 전체를 in-context로 읽고
M=3개의 offspring(자식) 시스템 코드를 생성
2. 실행 중 에러 나는 시스템은 self-reflection으로 최대 k=5번 자가 수정
3. 3개 후보를 각각 16개 intent-target pair에서 빠르게 평가 → 최고 1개 선별
4. 그 1개를 50개 pair에서 full 평가 → archive에 추가 (strict elitism)
이걸 토이 예제로 따라가 보자.
1세대: 초기 archive
archive에는 두 개의 baseline 시스템이 들어 있다. (이름만 기억하면 된다. 자세한 정의는 아래 “초기 archive” 절에서 푼다.)
- 시스템 A: Self-Refine — “공격하고, 실패하면 스스로 반성하고 다시 시도”하는 단순 루프.
- 시스템 B: JS-Guided AdvReasoning — judge 점수를 신호로 후보를 ranking·refine하는 강한 baseline.
2단계: meta agent가 3개 자식 생성
meta agent(GPT-5)는 archive의 두 시스템 코드를 읽고, “이 둘을 보니 이렇게 바꾸면 더 잘 통할 것 같다”는 식으로 새 시스템 코드 3개를 생성한다. 가상의 예:
| 후보 | meta agent의 변형 아이디어 |
|---|---|
| 자식 1 | Self-Refine에 “거부 문구 blacklist” 단계를 추가 |
| 자식 2 | JS-Guided에 “프롬프트를 다른 언어로 번역” 단계를 끼움 |
| 자식 3 | 두 baseline의 프롬프트 앞/뒤 절반을 결합(crossover) |
여기서 중요한 점: 이 변형 아이디어들을 사람이 가르쳐 준 적이 없다. meta agent가 코드를 보고 스스로 떠올린 것이다.
3단계: 빠른 1차 평가(16 pair) → 1개 선별
3개 자식을 각각 16개 (의도, target) 쌍에서 돌려 ASR을 잰다. 가상 결과:
- 자식 1: ASR 0.50
- 자식 2: ASR 0.69
- 자식 3: ASR 0.44
이 중 자식 2가 최고이므로 자식 2만 다음 단계로 넘긴다. (16개로 먼저 거르는 이유: 50개 full 평가는 비싸므로, 명백히 약한 후보를 싸게 미리 버리기 위해서다.)
4단계: full 평가(50 pair) → archive 추가
선별된 자식 2를 50개 쌍에서 정식 평가한다. ASR이 가령 0.66이 나오면, 자식 2가 새 archive 멤버가 된다. 이제 archive는 {Self-Refine, JS-Guided, 자식2}. 다음 세대에서 meta agent는 이 셋을 모두 보고 또 새 자식을 만든다.
5단계: 10세대 반복
위 2~4단계를 10세대 반복하면, archive에는 점점 더 강한 시스템이 쌓인다. 핵심은 세대가 지날수록 좋은 부분이 누적된다는 점이다. meta agent는 매번 “지금까지 가장 잘 통한 시스템들”을 보고 시작하므로, 좋은 아이디어가 다음 세대로 전수된다. 실패/성공 프롬프트도 FailedPromptMemory / SucceedPromptMemory에 누적되어 세대 간 지식 전달에 쓰인다.
왜 “한 번에 다 만들지 않고” 세대를 거치나
왜 meta agent에게 “처음부터 완벽한 시스템 하나 만들어”라고 하지 않을까? 두 가지 이유가 있다. 이는 GCG가 “한 번에 모든 토큰을 바꾸지 않고 한 좌표씩 바꾸는” 이유와 본질적으로 같다.
- LLM의 한 번 생성은 신뢰할 수 없다. GPT-5가 “이 시스템이 좋을 것 같다”고 만든 게 실제로 잘 통한다는 보장이 없다. 그래서 실제로 실행해 ASR을 측정하는 단계가 반드시 필요하다(1차 근사를 실측으로 검증하는 것과 같은 원리).
- 점진적 개선이 한 방에 만드는 것보다 안정적이다. 매 세대 좋은 것만 남기고 그 위에서 다시 변형하면, 탐색이 “잘 되던 방향”을 유지하면서 조금씩 나아간다. 처음부터 완벽을 노리면 운에 크게 좌우된다.
초기 archive — 두 baseline 시스템 풀어 보기
진화의 출발점인 두 baseline을 조금 더 풀어 본다. 출발점 품질이 결과를 좌우하므로(뒤 ablation에서 확인) 중요하다.
1. Self-Refine (Reflexion 변형): Reflexion 계열로, “시도 → 실패하면 그 실패를 말로 반성 → 반성을 참고해 다시 시도”하는 단순 루프다. 가장 약한 baseline이며, 단독으로는 ASR이 매우 낮다(Llama-2-7B에서 4%).
2. JudgeScore-Guided Adversarial Reasoning (JS-Guided AdvReasoning): 이전 SOTA인 Adversarial Reasoning의 black-box 변형이다. 원래 Adversarial Reasoning은 target 모델의 내부 logit(white-box 정보)을 써서 공격을 최적화하는데, 상용 모델은 logit을 안 주므로 그대로 못 쓴다. 그래서 AgenticRed는 judge 모델이 “성공”이라고 판정할 때 첫 토큰에 부여하는 확률(confidence)을 logit 대신 신호로 쓴다. 즉 white-box 그래디언트 신호를 black-box judge 신뢰도로 대체해, 정보를 못 보는 상황에서도 “Proposer(제안)–Verifier(검증)” 방식으로 후보를 ranking·refine한다.
이 둘로 시작하는 이유는 “약한 baseline 하나 + 강한 baseline 하나”로 진화의 폭을 넓히기 위해서다. 강한 것만 넣으면 다양성이 줄고, 약한 것만 넣으면 출발이 너무 낮다.
Emergent strategies — 사람이 안 가르쳤는데 나타난 공격들
AgenticRed가 흥미로운 진짜 이유는 여기에 있다. 진화 과정에서 meta agent가 사람이 명시적으로 코딩해 주지 않은 공격 기법들을 스스로 발견했다. 기존 jailbreak 문헌에 등장하는 기법들이 진화로 “재발견”된 것이다.
| Emergent 전략 | 무슨 일을 하나 |
|---|---|
| Reward shaping | judge 점수/reasoning 문자열을 가공해 ranking·refine 신호로 활용 |
| Refusal suppression | “I’m sorry”, “I cannot help” 같은 거부 문구를 blacklist로 억제 |
| Prefix injection | target 응답의 시작 토큰을 강제(예: “Sure, here is…”) |
| Adversarial translation | 프롬프트를 다른 언어/형식으로 번역해 안전 필터 우회 |
| Genetic operators | crossover(elite 프롬프트의 앞/뒤 절반 결합) + mutation(프로토콜 무작위 추가) |
여기서 prefix injection은 GCG 포스트에서 본 “응답을 ‘Sure, here is…‘로 시작하게 강제하면 자동회귀 특성상 나머지가 따라온다”는 바로 그 아이디어다. AgenticRed는 이 통찰을 사람이 입력하지 않았는데 진화로 다시 찾아냈다. 이게 meta-level 탐색의 힘이다 — 휴먼이 발견한 좋은 패턴들을, 충분한 탐색만 주면 시스템이 스스로 수렴해 찾아낸다.
(단, 이는 양날의 검이기도 하다. 뒤에서 보겠지만, meta agent가 본 학습 코퍼스에 기존 RT 문헌이 들어 있어 같은 패턴으로 수렴하는 경향, 즉 다양성 한계로도 이어진다.)
Experiments
Main Results (HarmBench)
평가는 표준 벤치마크인 HarmBench에서 이뤄진다. judge는 HarmBench-Llama-2-13b-cls를 쓰며, 인간 다수결과 비교했을 때 precision 0.91, F1 0.92로 신뢰할 만하다(즉 “성공”이라는 판정이 실제 성공과 잘 맞는다).
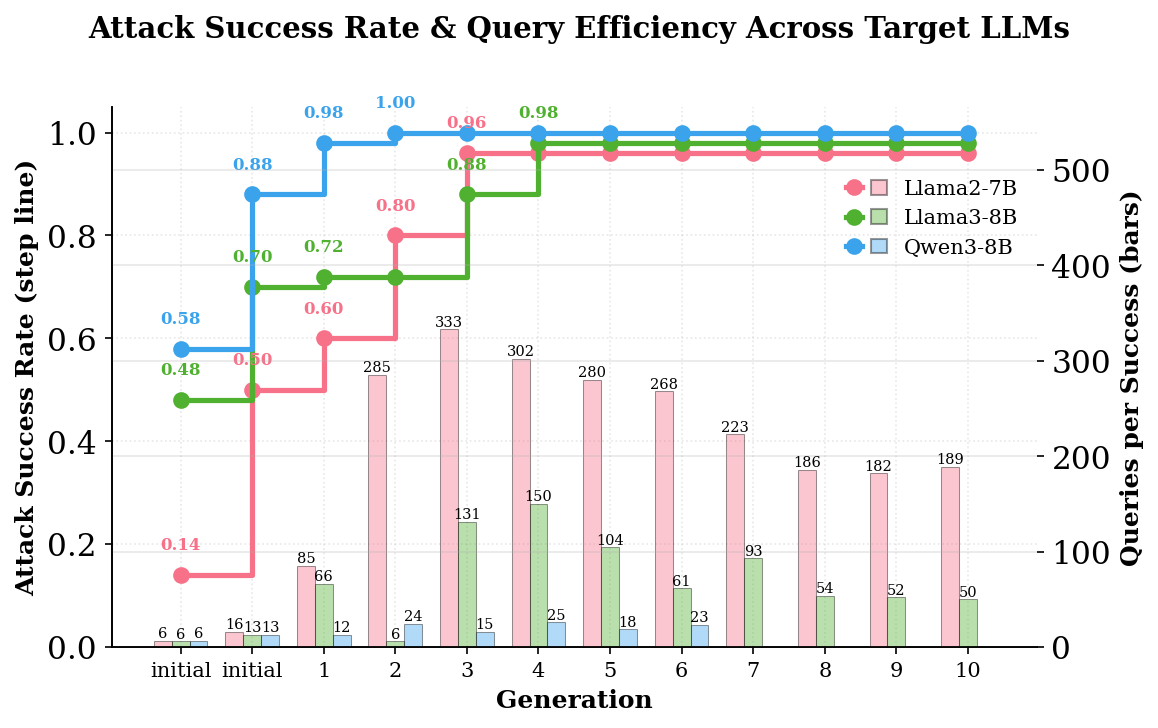
오픈웨이트 target에 대한 ASR:
| 방법 | Llama-2-7B | Llama-3-8B | Qwen3-8B |
|---|---|---|---|
| AgenticRed | 96% | 98% | 100% |
| AdvReasoning | 60% | 88% | 80% |
| AutoDAN-Turbo | 36% | 62% | 83% |
| PAIR | — | 75% | 47% |
| Self-Refine | 4% | 14% | 58% |
읽는 법: 가장 강력한 SOTA 베이스라인인 AdvReasoning과 비교해 보면, Llama-2-7B에서 60% → 96%로 +36%p다. 출발점이었던 Self-Refine(4%)과 비교하면 96%까지 진화한 것이니, 진화 과정이 사실상 시스템을 처음부터 새로 발명했다고 봐도 된다.
상용(proprietary) 모델로의 전이: 오픈 모델(Llama-2-7B 또는 Qwen3-8B)에서 진화시킨 시스템을 재튜닝 없이 상용 모델에 그대로 적용한 결과다.
| 모델 | AgenticRed ASR |
|---|---|
| GPT-3.5-Turbo | 100% |
| GPT-4o | 100% |
| GPT-5.1 | 100% |
| DeepSeek-R1 | 100% |
| DeepSeek-V3.2 | 100% |
| Claude-3.5 | 60% (+24%p over SOTA) |
주목할 점 두 가지.
- 가장 어려운 모델에서 가장 큰 향상. Claude-3.5는 모든 공격에 가장 견고한 모델인데, 바로 거기서 SOTA(36%) 대비 +24%p로 가장 큰 개선을 보인다. 쉬운 모델은 누구나 깨지만, 어려운 모델일수록 “사람이 못 떠올린 절차”의 가치가 커진다는 해석이 가능하다.
- query-agnostic 전이. 한 target에서 진화시킨 시스템이 전혀 다른 상용 모델(GPT-5.1, DeepSeek 등)에서도 100% ASR을 낸다. 즉 진화된 시스템은 특정 모델에 과적합한 트릭이 아니라 범용적으로 강한 공격 절차를 담고 있다.
진화 다이내믹스 — t-SNE로 본 다양성
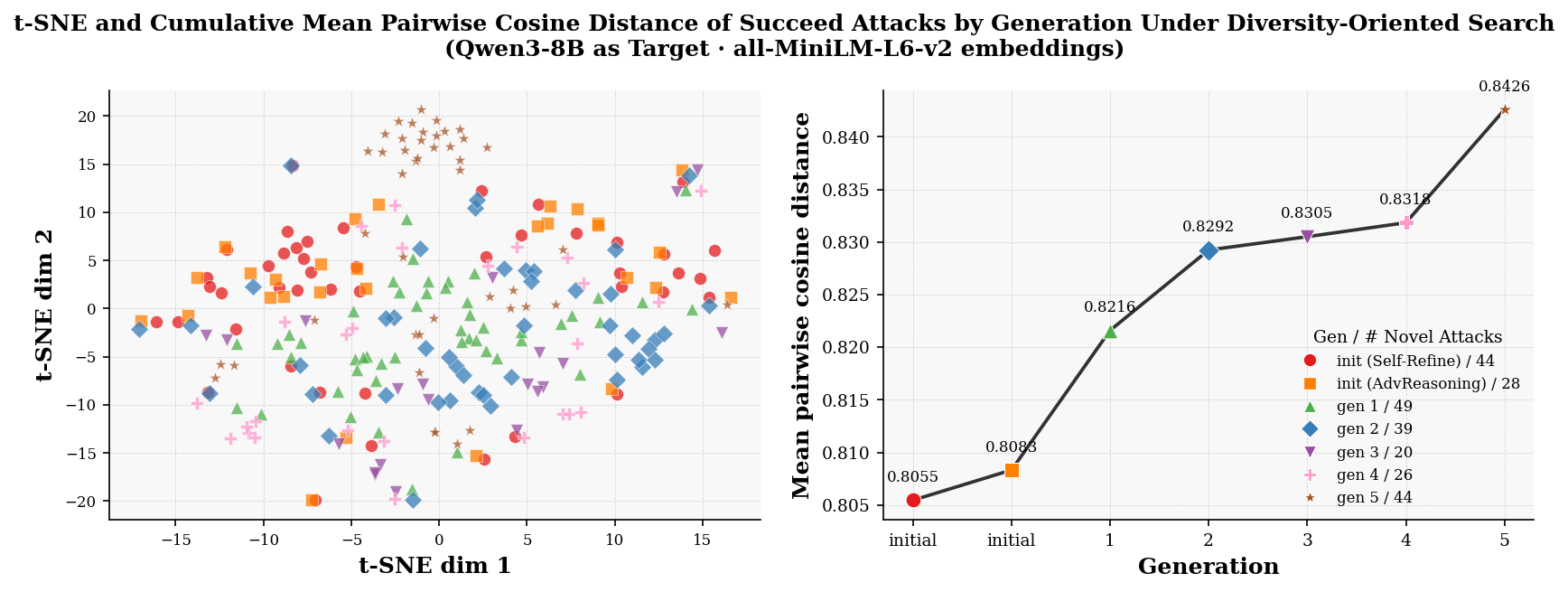
진화된 시스템들의 코드를 all-MiniLM-L6-v2 임베딩으로 벡터화한 뒤 t-SNE로 2차원에 찍은 그림이다. (t-SNE는 고차원 점들의 “가까운 건 가깝게” 관계를 2D에 보존해 그려 주는 시각화 기법이다.) 관찰되는 패턴:
- 세대가 진행될수록 손으로 짠 초기 archive와 뚜렷이 분리된 새 클러스터가 나타난다 → 진짜 새로운 시스템이 생겨난다는 증거.
- 동시에, 특정 영역으로 다시 수렴하는 모습도 보인다.
후자가 논문이 인정하는 다양성 한계다. 구체적으로 10세대 동안 attack template은 10번, refusal suppression은 8번, genetic operator는 10번 반복 등장했다. 즉 강력하지만 서로 비슷비슷한 시스템으로 몰리는 경향이 있다. 원인은 meta agent(GPT-5)의 학습 코퍼스에 기존 RT 문헌이 들어 있어, 결국 알려진 좋은 패턴으로 끌려가기 때문이다.
Ablation — 무엇이 성능을 만드나
| 제거/변경한 구성 | 효과 |
|---|---|
| Selection 제거 (M=3 → M=1) | 10세대 후 −6%p |
| 약한 초기 archive (JS-Guided 제거) | 2세대 후 정체 (개선 멈춤) |
| meta agent를 GPT-5 → DeepSeek-R1로 교체 | 거의 개선 없음 |
| Diversity term (semantic distance 보상) | 다양성↑, ASR은 marginal |
해석:
- Selection이 핵심이다. 세대마다 3개 만들어 1개 고르는 진화 압력을 없애면(매번 1개만 만들어 그냥 채택) 6%p 떨어진다. “여러 개 만들어 비교”가 단순 반복보다 낫다는 직접 증거다.
- 출발점 품질이 결정적이다. 강한 baseline(JS-Guided)을 빼고 약한 Self-Refine만으로 시작하면 2세대 만에 정체된다. 진화에는 좋은 “씨앗(warm-start)”이 필요하다.
- meta agent의 능력이 곧 천장이다. GPT-5를 DeepSeek-R1로 바꾸면 거의 개선이 없다. 강한 meta LLM이 없으면, 만들어 내는 시스템 품질 자체가 낮아진다(특히 기존 문헌에서 seed 아이디어를 끌어오는 능력이 떨어졌다).
- 다양성 보존은 양면적이다. semantic distance 보상을 넣으면 시스템 간 다양성은 늘지만 ASR 향상은 미미했다. 즉 다양성과 성능이 자동으로 같이 가지는 않는다.
Compute Cost — 공짜는 아니다
| 항목 | 값 |
|---|---|
| Training(탐색) 비용 | ~122K queries / success |
| Test-time 비용 | 339 queries / success (vs AdvReasoning 40) |
| meta agent | GPT-5 (시스템 코드 생성) |
| attacker | Mixtral-8x7B (실제 공격 수행) |
| target / judge | Llama-2-7B 등 / HarmBench-Llama-2-13b-cls |
냉정하게 보면 탐색 비용이 매우 크다. 시스템 하나를 진화시키는 데 성공당 약 12만 쿼리가 들고, 진화가 끝난 시스템을 실제로 돌릴 때도 성공당 339쿼리로 AdvReasoning(40)보다 비싸다.
다만 트레이드오프를 봐야 한다. 진화는 한 번만 하면 된다. 한 번 만들어 둔 시스템은 위 전이 결과처럼 GPT-5.1, DeepSeek, Claude 등 다양한 target에 재사용되며, 그때마다 100%에 가까운 ASR을 낸다. 즉 큰 고정비(진화)를 한 번 치르고, 그 결과를 여러 모델에 분할상환하는 구조다.
Conclusion
핵심 메시지는 한 문장이다. “RT 자동화의 다음 단계는 ‘policy 학습’이 아니라 ‘system 진화’다.”
세 가지 기여를 정리하면 다음과 같다.
- Meta-level 자동화. 사람이 공격 워크플로우를 설계할 필요가 없다. meta agent가 시스템 코드를 생성하고 진화시킨다.
- Emergent strategies. reward shaping, refusal suppression, prefix injection, translation, crossover 같은 기법이 사람의 지시 없이 진화 과정에서 저절로 발견됐다.
- SOTA 대비 큰 격차. 특히 가장 견고한 Claude-3.5에서 +24%p로 가장 큰 향상 — 어려운 모델일수록 meta-level 탐색의 가치가 크다.
한계점
- Training 비용이 매우 크다. 성공당 ~122K 쿼리로 Auto-RT보다 훨씬 비싸다.
- 다양성 수렴. 진화된 시스템들이 비슷한 패턴(attack template, refusal suppression 등)으로 몰린다. meta agent가 본 기존 RT 문헌으로 끌려가기 때문이다.
- HarmBench 단일 평가. 한 벤치마크에서만 검증돼 일반화 범위가 제한적이다.
- 강한 meta agent 의존. GPT-5 같은 강력한 meta LLM이 없으면 시스템 생성 품질이 급락한다(DeepSeek-R1 ablation).
- 재현성. GPT-5의 stochasticity 때문에 실행마다 다른 시스템이 나온다.
AgenticRed는 RT 연구가 “공격 알고리즘”에서 “공격 알고리즘을 만드는 알고리즘”으로, 추상화 사다리를 한 칸 더 올린 사례다. 흥미롭게도 이 흐름의 다음 칸은 공격하는 쪽이 아니라 공격당하는 쪽도 agent가 되는 영역이다 — 도구를 쓰는 LLM agent를 노리는 InjecAgent, AgentVigil이 그 주제다.
Red-Teaming 시리즈
이 글은 LLM Red-Teaming 시리즈의 열세 번째 글이다.
- Perez 2022 — LM으로 LM을 공격하기 (foundation)
- Ganguli 2022 — Anthropic의 38K 공격 데이터셋과 scaling behavior
- GCG (Zou 2023) — 그래디언트 기반 universal suffix
- AutoDAN (Liu 2023) — 자연어 유지하는 GA 기반 jailbreak
- AttnGCG — attention manipulation으로 GCG 강화 (추후 작성)
- PAIR (Chao 2023) — 20쿼리 black-box attacker LM
- TAP (Mehrotra 2023) — 트리 탐색 + 이중 pruning으로 PAIR 효율화
- GPTFuzz (Yu 2023) — AFL 영감의 template-level fuzzing
- Crescendo (Russinovich 2024) — multi-turn escalation으로 single-turn 방어 무력화
- Many-shot Jailbreaking (Anil 2024) — long-context를 ICL로 weaponize
- Curiosity-driven RT (Hong 2024) — novelty reward로 mode collapse 해결
- Auto-RT (Liu 2025) — strategy-level RL exploration + progressive curriculum
- (현재 글) AgenticRed (Yuan 2026) — RT 시스템 자체를 진화
- InjecAgent (Zhan 2024) — Tool-use LLM agent에 대한 IPI 벤치마크
- AgentVigil (Wang 2025) — MCTS 기반 IPI 자동 공격
- AdvBench (Zou 2023) — GCG 논문의 harmful behaviors/strings 표준 벤치마크
- HH-RLHF red-team (Ganguli 2022) — Anthropic 38K red-team 대화 데이터셋
- HarmfulQA (Bhardwaj 2023) — Chain-of-Utterances 기반 유해 QA + RED-INSTRUCT
- BeaverTails (Ji 2023) — helpfulness/harmlessness 분리 라벨 QA 데이터셋
- WildJailbreak (Jiang 2024) — 대규모 합성 vanilla/adversarial 학습 데이터
- PIKA (2025) — 난이도 집중 expert-level 합성 정렬 데이터셋
- ALMA (Yasunaga 2024) — 최소 주석으로 합성 데이터 기반 정렬
- HarmBench (Mazeika 2024) — 510 행동 × 18 공격 × 33 모델 표준 + R2D2 방어
- JailbreakBench (Chao 2024) — 100 misuse + 100 benign + jailbreak artifacts repository
- Constitutional AI (Bai 2022) — AI feedback으로 인간 라벨 없이 alignment
- Llama Guard (Inan 2023) — open-weight input/output safety classifier 본 시리즈는 26편으로 구성된다 (#5 AttnGCG는 추후 작성).
참고 문헌
- Yuan et al., 2026. AgenticRed: Evolving Agentic Systems for Red-Teaming.
- Shinn et al., 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. (Self-Refine 원형)
- Sabbaghi et al., 2025. Adversarial Reasoning at Jailbreaking Time. (JS-Guided AdvReasoning 원형)
- Liu et al., 2025. Auto-RT. (직전 단계)
- Hu et al., 2024. Automated Design of Agentic Systems (ADAS) / Meta Agent Search. (meta agent 시스템 탐색 원형)
- Zoph & Le, 2017. Neural Architecture Search with Reinforcement Learning. (NAS 원형)
- Mazeika et al., 2024. HarmBench. (평가 벤치마크)
Enjoy Reading This Article?
Here are some more articles you might like to read next: