TravelPlanner: A Benchmark for Real-World Planning with Language Agents
TravelPlanner: A Benchmark for Real-World Planning with Language Agents (Xie et al., Fudan University & Penn State, ICML 2024)
Introduction
LLM agent 연구는 빠르게 발전해왔다. ReAct·Reflexion·Tree of Thoughts 같은 prompting 기법, AutoGPT·BabyAGI 같은 자율 framework가 쏟아져 나왔다. agent는 코딩(SWE-bench)과 web browsing(GAIA)에서 가시적 성과를 보였다.
그런데 한 가지 능력에서 agent는 처참하게 무너진다. 사용자가 무심코 던지는 다음과 같은 부탁이다.
“3박 4일 여행 계획을 짜줘. 예산은 100만원이고, 가족 4명이고, 부산에서 출발해서 제주도 다녀올 거야. 한식 위주로 부탁해.”
이 평범한 요청을 풀려면 agent는 다음을 해야 한다.
- 여러 제약 조건을 동시에 만족 (예산, 인원, 출발지, 음식 선호)
- 여러 도구의 결과를 종합 (항공편, 호텔, 식당, 관광지 검색)
- 계획의 모든 부분이 일관되어야 함 (도착 후 호텔 체크인 시간, 같은 식당 중복 금지)
TravelPlanner는 이런 constrained multi-step planning을 정량적으로 측정하는 첫 본격 벤치마크다. 결과는 충격적이다.
“Even GPT-4-Turbo achieves only a 0.6% success rate.”
1,225개 task 중 7개만 모든 제약을 만족하는 완벽한 계획을 만들었다. 이 논문은 ICML 2024 Spotlight에 발표되었고, agent의 planning이 reasoning과 별개의 어려움임을 정량적으로 보여줬다.
Related Work
기존 Planning 벤치마크의 한계
| 분류 | 대표 | 한계 |
|---|---|---|
| Symbolic planning | Blocksworld, PDDL | 단일 목표, 고정 ground truth, 작은 search space |
| Embodied | ALFWorld, VirtualHome | 가정 환경 중심, 제약이 implicit |
| Web | WebArena, Mind2Web | navigation은 있지만 long-horizon constraint 부재 |
| Tool-use | API-Bank, ToolBench | tool calling은 있지만 plan 일관성 평가 없음 |
기존 벤치마크는 (a) 제약이 거의 없거나 implicit하고, (b) tool-use와 long-horizon planning을 함께 평가하지 못하고, (c) 환경이 정적이거나 closed-world였다.
왜 여행 계획인가
저자는 여행 task가 planning 평가에 적합한 5가지 이유를 제시한다.
- 다중 제약 동시 만족: 예산, 동선, 식당 다양성, 숙박 룰 등 explicit + implicit 제약 공존
- Long-horizon: 3~7일 일정에 매일 6~7개 의사결정 → 한 plan에 수십 개 sub-decision
- Tool-use 필수: ~400만 record의 DB에서 정보를 능동 수집
- 검증 가능성: 자연어 plan이지만 구조화된 메트릭으로 자동 평가
- 실세계 의미: human annotator도 plan 당 평균 12분 소요할 정도의 난이도
데이터셋 상세
구성 방식
- Human-written queries: 다양한 explicit/implicit 제약을 자연스럽게 포함하도록 작성
- 20명의 대학원생 annotator가 reference plan 작성
- Plan 당 평균 12분 소요, $0.80 보상
- 9개 group: {3-day, 5-day, 7-day} × {Easy, Medium, Hard}
Split 분포 (총 1,225)
| Split | 그룹당 | 총 query |
|---|---|---|
| Train | 5 | 45 |
| Validation | 20 | 180 |
| Test | ~111 | 1,000 |
Test set 9-group 분포:
| Easy | Medium | Hard | |
|---|---|---|---|
| 3-day | 122 | 104 | 82 |
| 5-day | 116 | 114 | 121 |
| 7-day | 110 | 115 | 116 |
난이도 정의
| Level | 제약 |
|---|---|
| Easy | 예산만, 단일 도시 (3일) |
| Medium | 예산 + 1개 추가 (cuisine / room type / room rule 중 하나) |
| Hard | 예산 + 3개 추가 (transportation 선호 포함), 다중 도시 (5일=2, 7일=3) |
환경 / DB 규모
총 약 400만 record의 closed-world DB.
| Tool | DB 크기 |
|---|---|
| FlightSearch | 3,827,361 항공편 |
| DistanceMatrix | 17,603 도시 쌍 |
| RestaurantSearch | 9,552 식당 |
| AttractionSearch | 5,303 관광지 |
| AccommodationSearch | 5,064 숙박 |
| CitySearch | 312 도시 (미국 50개 주) |
Query 예시 (Hard, verbatim)
“Could you create a challenging travel plan for 7 people from Roanoke to Illinois spanning a week, from March 8th to March 14th, 2022, with a budget of $30,200?”
Reference plan 포맷 (per day)
- Current City
- Transportation (예: “Flight Number: F0123456, from X to Y, Departure Time: …, Arrival Time: …”)
- Breakfast / Lunch / Dinner (식당명, 도시)
- Attraction (관광지명, 도시)
- Accommodation (숙소명, 도시)
환경 / Tool Suite
7개 도구로 구성된다.
| Tool | Input | Output |
|---|---|---|
| FlightSearch | (origin, dest, date) | 항공편 리스트 (편명, 가격, 시각) |
| DistanceMatrix | (origin, dest, mode) | 거리, 소요시간, 비용 |
| AccommodationSearch | (city) | 숙소 리스트 (이름, 가격, room type, rules, min stay) |
| RestaurantSearch | (city) | 식당 리스트 (이름, 가격대, cuisine) |
| AttractionSearch | (city) | 관광지 리스트 (이름, 주소) |
| CitySearch | (state) | 해당 주의 후보 도시 |
| NotebookWrite | (description, content) | 검색 결과를 “Notebook”에 저장 |
Tool 호출은 ReAct 스타일의 Action: Tool[args] 포맷. 30 step이 최대 action budget — 초과 시 fail.
sandbox는 static이다. 외부 인터넷 호출 없이 closed DB만 사용 → 재현성 보장. 실제 항공편 가격 변동은 다루지 않는다.
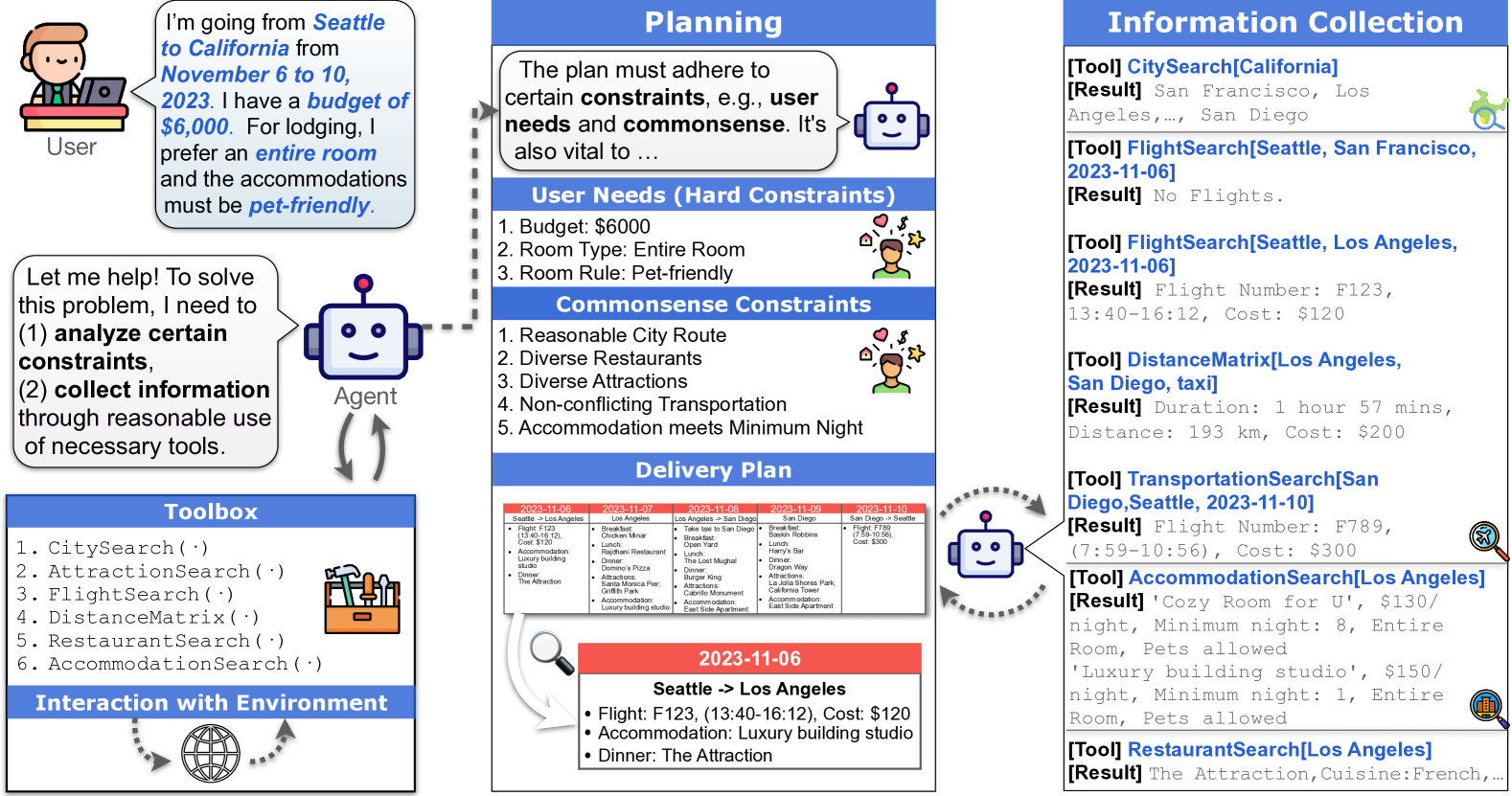
평가 모드 두 가지
(1) Sole-planning Mode
도구 호출로 모을 수 있는 모든 reference 정보를 사전에 prompt에 제공한다. agent는 plan 작성에만 집중한다. planning 능력만 격리 평가하는 모드다.
prompting 전략 4가지를 비교할 수 있다.
- Direct
- CoT
- ReAct
- Reflexion
(2) Two-stage Mode
Stage 1 (Tool Use): agent가 도구를 호출해 정보 수집, NotebookWrite로 저장 Stage 2 (Planning): 수집된 notebook 내용을 바탕으로 plan 생성
정보 수집 자체가 실패할 수 있고, 부족하거나 불일치하는 정보로 인해 planning이 더 어려워진다. end-to-end full pipeline 평가다.
평가 메트릭
Delivery Rate
30 step 안에 형식상 plan을 산출했는지 (parsing 가능한 출력). 가장 약한 요구사항.
Commonsense Constraint Pass Rate
Micro: 개별 제약 단위 통과율
\[\text{Micro} = \frac{\sum_i \#\text{passed commonsense in plan } i}{\sum_i \#\text{total commonsense in plan } i}\]Macro: plan 전체가 모든 8개 commonsense를 동시에 만족한 비율
\[\text{Macro} = \frac{\#\text{plans passing all 8 commonsense}}{\#\text{total plans}}\]Hard Constraint Pass Rate
사용자가 query에 명시한 제약(예산 등)에 대해 동일한 방식의 Micro/Macro 계산.
Final Pass Rate
\[\text{Final Pass} = \frac{\#\text{plans passing all commonsense AND all hard}}{\#\text{total plans}}\]모든 commonsense 8가지 + 모든 hard 제약을 동시 만족해야 한다. 가장 엄격한 메트릭.
Macro/Final이 매우 낮은 이유는 8개 commonsense 중 하나만 실패해도 그 plan은 0점 처리되기 때문이다.
8가지 Commonsense Constraints
| # | 이름 | 정의 |
|---|---|---|
| 1 | Within Sandbox | plan에 등장하는 모든 항목은 DB에 실제 존재해야 함. Hallucination 금지. |
| 2 | Complete Information | 필수 필드 누락 금지 |
| 3 | Within Current City | 하루 일정의 모든 활동은 해당 일자의 city 내에서 |
| 4 | Reasonable City Route | 도시 간 이동이 논리적으로 타당 |
| 5 | Diverse Restaurants | 여행 전 기간 동안 같은 식당 중복 금지 |
| 6 | Diverse Attractions | 같은 관광지 중복 방문 금지 |
| 7 | Non-conflicting Transportation | 동일 구간에 self-driving과 flight 동시 사용 금지 |
| 8 | Minimum Nights Stay | 숙소가 요구하는 최소 숙박일 충족 |
Hard Constraints (5종)
| 종류 | 예시 |
|---|---|
| Budget | 총 비용 ≤ query 명시 ceiling |
| Room Rule | “No parties”, “No smoking”, “No children under 10”, “No pets”, “No visitors” |
| Room Type | Entire Room / Private Room / Shared Room |
| Cuisine | Chinese, American, Italian, Mexican, Indian, Mediterranean, French |
| Transportation | “No flight”, “No self-driving” 등 |
Experiments
Sole-planning Mode 결과
Test set 1,000개 query 기준:
| Model / Strategy | Delivery | Common. Micro | Common. Macro | Hard Micro | Hard Macro | Final Pass |
|---|---|---|---|---|---|---|
| Direct GPT-3.5-Turbo | 100% | 59.5 | 2.7 | 9.5 | 4.4 | 0.6 |
| Direct GPT-4-Turbo | 100% | 80.6 | 15.2 | 44.3 | 23.1 | 4.4 |
| CoT GPT-3.5-Turbo | 99.7 | — | — | — | — | 0.4 |
| ReAct GPT-3.5-Turbo | 81.6 | 45.9 | 2.5 | 10.7 | 3.1 | 0.7 |
| Reflexion GPT-3.5-Turbo | 92.1 | 52.1 | 2.2 | 9.9 | 3.8 | 0.6 |
핵심 관찰:
- Sole-planning에서도 GPT-4-Turbo가 4.4%에 그친다. 모든 도구 결과를 미리 줘도 plan을 못 짠다.
- CoT/ReAct/Reflexion이 Direct를 능가하지 못한다. 오히려 reasoning chain이 길어지면서 제약을 놓치는 경향.
- Commonsense Macro가 Micro보다 훨씬 낮다 (15.2 vs 80.6). 개별 제약은 잘 지키지만 8개 동시 충족은 거의 못 한다.
Two-stage Mode 결과
| Model | Delivery | Common. Micro | Hard Micro | Final Pass |
|---|---|---|---|---|
| Greedy Search (baseline) | 100% | 72.0 | 52.4 | 0 |
| GPT-3.5-Turbo | 86.7 | — | — | 0 |
| Mistral-7B-32K | — | — | — | 0 |
| Mixtral-8×7B-MoE | 49.4 | — | — | 0.4 |
| Gemini Pro | 28.9 | — | — | 0.1 |
| GPT-4-Turbo | 93.1 | 63.3 | 10.5 | 0.6 |
GPT-4-Turbo가 4.4% → 0.6%로 약 7배 하락한다. Tool-use 단계가 매우 큰 병목이다.
Fine-tuning 결과 (2024-10 업데이트)
| Model | Common. Micro | Hard Micro | Final Pass |
|---|---|---|---|
| Llama-3.1-8B (Direct) | 60.1 | 7.9 | 0.0 |
| Llama-3.1-8B (SFT) | 78.3 | 19.3 | 3.8 |
| Qwen2-7B (SFT) | 59.0 | 0.2 | 0.0 |
Llama-3.1-8B SFT만으로 GPT-4-Turbo Direct(4.4%)에 근접한 3.8%를 달성한다. fine-tuning이 매우 효과적이다.
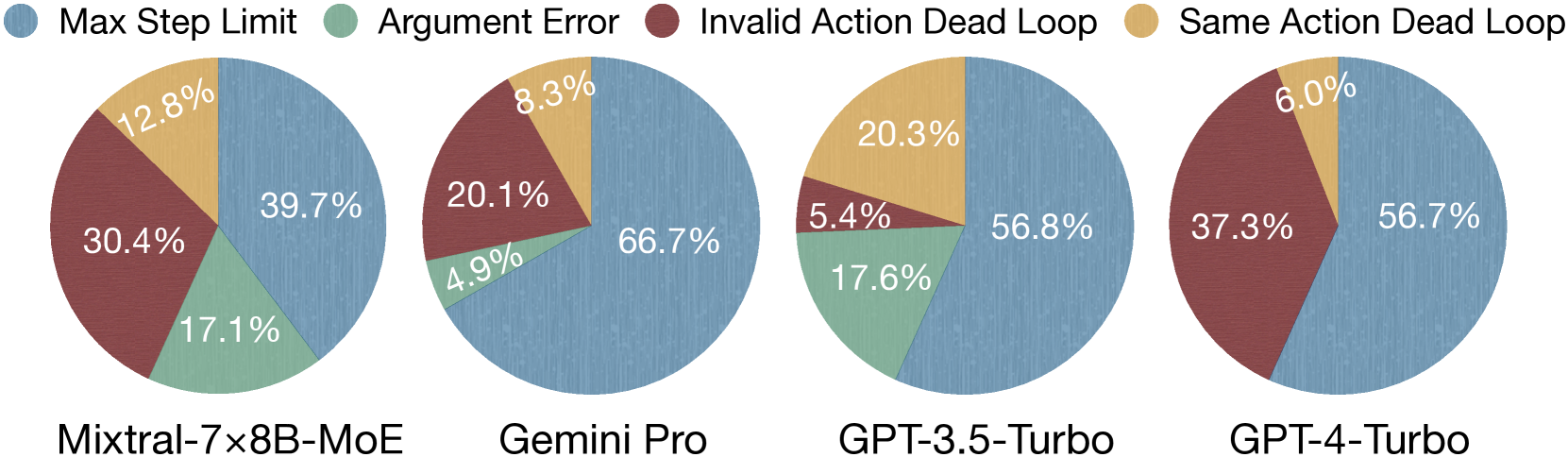
실패 분석
Tool-use stage 실패 유형 (GPT-4-Turbo Two-stage)
| 유형 | 비율 / 특징 |
|---|---|
| Invalid Action / Argument Error | ~37.3% — 잘못된 tool 이름/파라미터 |
| Repetitive Action Loop (dead loop) | ~6.0% — 같은 호출 반복 |
| Information Under-collection | reference는 3-day에 평균 2.0개 flight 수집 vs agent는 0.7개 |
| Step budget 초과 | 30 step 한계에 걸려 plan 생성 못함 |
Planning stage 실패 유형
- Budget 계산 오류 (가장 빈번): 숫자 합계가 ceiling을 초과하는데도 통과 처리
- Constraint inconsistency: 단일 제약(Micro)은 잘 지키지만 8개 commonsense를 동시 충족(Macro)은 거의 못함 — “global constraint satisfaction” 부재
- Hallucination: DB에 없는 식당/항공편을 만들어냄 (“Within Sandbox” 위반)
- Lost in the Middle: 긴 context의 중간에 있는 정보를 무시
- Reasoning-Action Misalignment: “예산을 줄여야 한다”고 추론하면서 더 비싼 옵션 선택
- Self-correction 실패: Reflexion으로도 초기 오류(예: 잘못된 날짜)를 고치지 못함

Planning vs Tool-use, 어느 쪽이 더 큰 병목인가
- Sole-planning(4.4%) ≫ Two-stage(0.6%) → 둘 다 병목이지만 tool-use가 더 큰 wall
- 그러나 sole-planning에서도 95%+ 실패 → planning 자체도 미해결
즉, “도구만 잘 부르면 plan은 잘 짠다”가 아니라 planning 자체가 어려운 문제다.
Discussion / 한계
저자가 인정한 한계
- 단일 도메인: 여행이라는 한 영역에 국한. 일반 planning으로 직접 일반화 어려움
- 합성/Sandbox 데이터: 실제 API/실시간 가격 변동을 반영하지 않음. Closed-world
- 정적 환경: 동적 가용성(매진된 항공편 등) 미지원
- 자연어 plan parsing 의존: GPT-4를 사용해 JSON 변환 → parser 자체의 noise 가능
- Annotator 편향: 미국 50개 주만 다룸. 국제 여행, 다국어 미지원
Cheating 방지 경고
README에 explicit warning이 있다.
- query를 JSON으로 reverse-engineer하여 직접 푸는 행위 금지
- commonsense를 prompt에 hard-code하는 행위 금지
저자는 이런 우회 풀이가 벤치마크의 의미를 훼손한다고 강조한다.
긍정적 측면
저자는 비관적이지만은 않다.
“Agent가 이런 복잡한 문제를 시도할 수 있다는 것 자체가 non-trivial progress.”
Conclusion
TravelPlanner의 의의를 정리하면:
- Planning ≠ Reasoning: 추론 능력이 좋은 모델도 multi-constraint planning은 못 한다는 점을 정량적으로 증명
- Global constraint satisfaction의 어려움: 개별 제약(Micro)은 80%+ 만족하면서 전체 plan(Macro)은 15%만 만족 — “부분의 합이 전체가 아님”을 보여줌
- Tool-use가 추가 병목: sole-planning에서 4.4% → two-stage에서 0.6%로 추가 하락
- Fine-tuning의 효과: 7B SFT 모델이 GPT-4 Direct를 거의 따라잡음
- 이후 도메인 특화 planning 벤치마크의 원형: TelAgentBench의 Plan 차원이 TravelPlanner의 Sole-planning 모드와 hard/commonsense 제약 구조를 직접 차용
TravelPlanner는 agent 능력의 숨겨진 약점을 정확히 짚어냈다. 코딩(SWE-bench)이나 QA(GAIA)에서 보이는 진전과 달리, planning은 2024년 ICML 시점에 GPT-4조차 0.6%였다. 이는 agent가 진정한 “assistant”가 되려면 추론 능력 외에 global constraint optimization 능력이 필요함을 시사한다.
이어서 읽기: AgentBench, GAIA, SWE-bench, TelAgentBench: 통신 도메인 LLM 에이전트 평가
참고 문헌
- TravelPlanner: A Benchmark for Real-World Planning with Language Agents (arXiv 2402.01622) — Xie et al., ICML 2024
- 공식 프로젝트 페이지 (OSU NLP Group)
- GitHub: OSU-NLP-Group/TravelPlanner
- PMLR ICML 2024 Proceedings
- HuggingFace Leaderboard
- ReAct (Yao et al., 2023)
- Reflexion (Shinn et al., 2023)
- Lost in the Middle (Liu et al., 2023)
Enjoy Reading This Article?
Here are some more articles you might like to read next: