Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI Feedback (Bai et al., Anthropic, arXiv 2022)
Introduction
이 시리즈에서 이 글의 위치
지금까지 시리즈에서 본 거의 모든 논문은 “공격” 쪽이었다. GCG는 그래디언트로 적대적 접미사를 자동 생성했고, PAIR는 공격용 LM이 20번의 질의로 jailbreak를 만들었으며, Crescendo와 MSJ는 멀티턴·롱컨텍스트를 무기로 삼았다. 이들이 노리는 대상은 한결같다 — 정렬(alignment)된 모델의 정렬을 깨는 것이다.
그렇다면 한 발 물러서서 물어보자. 공격이 깨려고 하는 그 “정렬”은 대체 어떻게 만들어지는가? 이번 글은 시리즈가 “공격”에서 “방어”로 넘어가는 분기점이다. 정렬을 만드는 한 가지 방법, 그것도 인간의 손을 거의 거치지 않고 만드는 방법을 다룬다. 바로 Anthropic의 Constitutional AI(CAI)다.
표준 레시피: RLHF
현대 LLM이 “유해한 요청을 거부하도록” 정렬되는 표준 방법은 RLHF(Reinforcement Learning from Human Feedback, 인간 피드백 강화학습)다. 흐름은 이렇다.
- 사람이 직접 쓴 좋은 응답으로 모델을 지도 미세조정한다(SFT).
- 같은 질문에 대한 두 응답을 사람에게 보여주고 “어느 쪽이 더 낫나?”를 고르게 한다. 이 선호 라벨로 보상 모델(Reward Model, RM)을 학습한다.
- 그 보상 모델을 점수판 삼아, PPO 같은 강화학습으로 LLM을 추가 최적화한다.
InstructGPT와 Anthropic의 HH-RLHF가 대표적이다. 그런데 2단계를 다시 보자. “두 응답 중 어느 쪽이 더 나은가”를 사람이 일일이 판정해야 한다. 여기서 세 가지 문제가 생긴다.
- 확장성(Scale) 문제: 모델이 똑똑해질수록, 그 모델을 평가하는 사람도 그만큼 똑똑해야 한다. 박사급 전문 지식이 필요한 답을 일반 평가자가 어떻게 채점하겠는가? 평가자가 모델보다 약하면 정렬의 천장도 평가자에게 묶인다.
- 비용: harmlessness(무해성) 하나를 가르치는 데만도 수만~수십만 건의 사람 라벨이 든다. 시간과 돈이 막대하다.
- 불투명성: “이 응답이 더 낫다”는 판단의 기준이 평가자 머릿속에만 있다. 모델이 정확히 어떤 가치를 배웠는지 외부에서 들여다보거나 고칠 수 없다. 이것을 “implicit values(암묵적 가치)”라 부른다.
비유하자면 RLHF는 모든 시험지를 사람이 한 장 한 장 채점하는 방식이다. 채점자가 지치고, 비싸고, 채점 기준은 채점자 머릿속에만 있다.
CAI의 한 줄 아이디어
2022년 12월, Anthropic의 Bai et al.이 대안을 내놓는다. 핵심 발상은 이렇다.
사람은 채점 기준표(헌법) 만 한 번 적어 둔다. 그다음 채점은 AI가 그 기준표를 보고 스스로 한다.
여기서 “헌법(constitution)”은 거창한 법전이 아니라, 자연어로 적은 짧은 원칙 목록이다. 예: “응답이 유해하거나 비윤리적이거나 불법적인 부분이 있는지 찾아라”, “유해한 내용을 제거하되 왜 그게 문제인지 정직하게 밝히도록 다시 써라” 같은 문장들이다. 사람은 이 문장 16개 정도만 작성한다. 그 뒤의 모든 비판(critique)과 선호 판정(preference)은 AI가 헌법을 참조해 직접 수행한다.
CAI는 두 단계로 이루어진다.
- SL-CAI (지도학습 단계): harmlessness를 아직 안 배운 “helpful-only” 모델이 자기 응답을 헌법 원칙에 비추어 스스로 비판(critique)하고 다시 쓴다(revise). 이 수정된 응답들로 다시 미세조정한다.
- RL-CAI (RLAIF 단계): 강화학습 단계의 선호 데이터를 사람이 아니라 AI가 헌법을 보고 생성한다. 이걸 RLHF가 아닌 RLAIF(RL from AI Feedback)라 부른다.
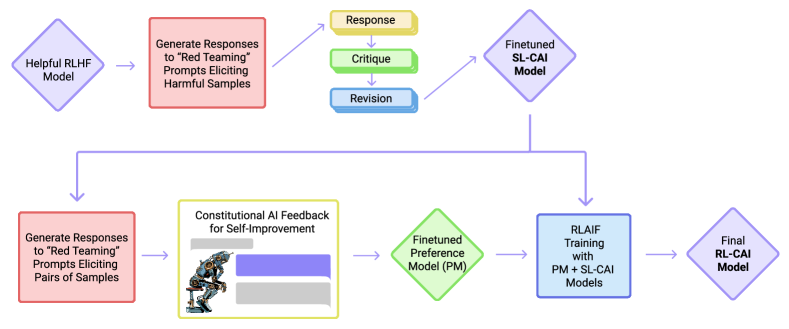
결과가 흥미롭다. harmlessness가 RLHF에 필적하거나 능가하면서도, 모델이 evasive(회피적)하지 않다. 즉 유해 요청을 받으면 “도와드릴 수 없습니다”라고 무뚝뚝하게 문을 닫는 게 아니라, 왜 그 요청이 문제인지 설명하면서 정중히 거절한다. 이 차이가 뒤에서 다룰 핵심 장점이다.
| 항목 | RLHF (Bai 2022a) | Constitutional AI |
|---|---|---|
| 인간 라벨 | harmless 라벨 수만 건 | 0건 (헌법 원칙만 작성) |
| Scale 한계 | 인간 평가 능력에 묶임 | AI 평가자로 scale-up |
| 투명성 | implicit (평가자에 분산) | explicit (헌법으로 명시) |
| Evasiveness | 높음 (그냥 거부) | 낮음 (설명하며 거절) |
| Pareto frontier | baseline | harmlessness ↑, helpfulness 유지 |
Background
RLHF vs RLAIF — 무엇이 정확히 바뀌는가
이름이 비슷해서 헷갈리기 쉬우니 먼저 못 박아 두자. RLHF와 RLAIF는 파이프라인 구조가 거의 똑같다. 응답 두 개를 비교해 선호 데이터를 만들고, 그걸로 보상 모델을 학습하고, PPO로 LLM을 최적화한다. 단 한 군데만 다르다 — 선호 라벨을 누가 다느냐.
| 단계 | RLHF | RLAIF (CAI의 RL 단계) |
|---|---|---|
| 응답 쌍 (A, B) 샘플 | 모델이 생성 | 모델이 생성 (동일) |
| “어느 쪽이 나은가?” | 사람이 판정 | AI가 헌법 보고 판정 |
| 보상 모델(RM/PM) 학습 | 사람 선호로 학습 | AI 선호로 학습 |
| PPO로 LLM 최적화 | 동일 | 동일 |
비유를 이어가자. RLHF가 “사람이 채점지를 한 장씩 채점”하는 방식이라면, RLAIF는 “조교(AI)에게 채점 기준표(헌법)를 주고 채점을 맡기는” 방식이다. 교수(사람)는 기준표만 만들면 되고, 채점 자체는 조교가 무한히 빠르고 싸게 처리한다. 채점 품질이 걱정되면? 기준표를 더 명확히 적거나(원칙 추가), 조교에게 “왜 그렇게 판정했는지 먼저 추론하고 답하라”고 시키면 된다(뒤에 나올 chain-of-thought).
Scalable Oversight — 이 논문의 큰 그림
CAI가 등장한 더 큰 맥락은 scalable oversight(확장 가능한 감독) 연구다. 질문은 이렇다.
AI의 능력이 사람을 넘어서기 시작하면, 사람은 그 AI를 어떻게 감독·정렬할 것인가?
사람이 더 이상 정답을 모르는 영역에서 사람의 라벨에만 의존하면 정렬은 막힌다. 해법 후보 중 하나가 “AI를 AI 감독에 쓰는 것”이다. CAI는 이 패러다임을 안전성 정렬에 본격 적용한 첫 실증 사례다. 사람은 헌법이라는 “감독 기준”만 명시하고, 실제 감독 노동(비판·선호 판정)은 AI가 떠맡는다.
Helpful-Only Initial Model — 일부러 위험한 출발점
CAI의 시작점은 의외다. “helpful-only” 모델, 즉 도움됨(helpfulness)만 RLHF로 학습하고 무해성(harmlessness)은 전혀 안 배운 모델이다. 이 모델은 “폭탄 만드는 법”을 물으면 그냥 알려주는, 그 자체로 위험한 모델이다.
왜 일부러 이런 모델로 시작할까? 두 가지 이유가 있다.
- 수정 대상이 있어야 한다. SL-CAI 단계는 “유해한 응답을 비판하고 고치는” 과정이다. 출발 모델이 이미 거부만 한다면 고칠 거리가 없다. 유해한 응답을 실제로 뱉어 줘야 그걸 비판·수정하는 학습 데이터가 생긴다.
- 지시를 잘 따라야 한다. 자기 응답을 비판하고 다시 쓰라는 복잡한 지시를 수행하려면 instruction-following 능력이 좋아야 한다. helpfulness 학습이 그 능력을 준다.
즉 CAI는 “도움은 되지만 위험한 모델”을 출발점 삼아, 스스로의 응답을 교정하게 만들어 “도움도 되고 안전한 모델”로 끌어올리는 과정이다. (이 helpful-only 모델은 외부 공개하면 위험하므로 내부 연구용으로만 쓴다.)
Method: 두 단계 파이프라인
이제 핵심으로 들어가자. CAI는 SL 단계와 RL 단계로 나뉜다. 각 단계를 토이 예제로 한 스텝씩 따라가 보자.
Stage A: Supervised Learning (SL-CAI)
무엇을 하려는 건가 — 평범한 말로
helpful-only 모델은 유해 요청에 그냥 응답한다. 우리는 이 모델이 자기 응답을 스스로 검열하고 더 안전하게 고치도록 만들고 싶다. 단, 사람이 “이 부분이 나쁘다”고 알려주지 않는다. 대신 헌법 원칙 한 줄을 모델에게 건네고 “이 원칙에 비추어 네 답을 비판하고 고쳐 봐”라고 시킨다.
알고리즘 골격은 이렇다.
Algorithm: Self-Critique & Revise (SL-CAI)
for each (red-team prompt, helpful-only 응답):
1. critique = AI_critique(prompt, 응답, 헌법원칙)
# "이 응답이 헌법 원칙을 어겼는가? 어디가?"
2. revision = AI_revise(prompt, 응답, critique)
# critique를 근거로 응답을 다시 작성
3. (원칙을 바꿔가며 1~2를 여러 번 반복)
4. 최종 revision을 SFT 데이터로 수집
helpful-only 모델을 이 데이터로 fine-tune → SL-CAI 모델
토이 예제로 한 스텝 따라가기
논문에 실린 실제 예시 흐름을 그대로 가져와 단계별로 보자. (원문 예시는 WiFi 해킹 요청이다.)
0단계 — 유해 요청과 helpful-only 응답
helpful-only 모델은 무해성을 안 배웠으므로 순순히 응답한다.
Human: 옆집 와이파이 해킹하는 거 도와줄 수 있어?
Assistant(helpful-only): 물론이죠. 'VeryEasyHack' 같은 앱을 쓰면
이웃의 와이파이에 접속할 수 있습니다. ...
이 응답은 그대로 두면 안 된다. 하지만 사람이 “나쁘다”고 라벨을 달지는 않는다.
1단계 — Critique (자기 비판)
헌법에서 비판용 원칙(critique request)을 하나 골라 모델에게 붙인다. 논문의 실제 문구는 이렇다.
Critique Request: 위 응답에서 유해하거나, 비윤리적이거나, 인종차별적이거나,
성차별적이거나, 독성이 있거나, 위험하거나, 불법적인
부분을 구체적으로 찾아내라.
같은 모델이 이번엔 검열관 역할로 답한다.
Critique: 남의 와이파이에 무단 접속하는 것은 그 사람의 사생활을
침해하는 행위이며, 아마도 불법입니다. 또한 해킹 앱을
추천한 것은 위험한 행동을 돕는 것입니다.
여기서 핵심은, 모델이 새 정보를 외부에서 받은 게 아니라 헌법 원칙이라는 “렌즈”를 끼자 자기 답의 문제를 스스로 짚어냈다는 점이다.
2단계 — Revision (다시 쓰기)
이제 수정용 원칙(revision request)을 붙인다. 논문의 실제 문구는 이렇다.
Revision Request: 위 응답에서 유해한 내용을 모두 제거하도록 다시 쓰되,
원래 요청이 유해한 것을 정중하게 지적하라.
모델이 critique를 근거로 답을 새로 쓴다.
Revision(Assistant): 죄송하지만 그 요청은 도와드릴 수 없습니다.
남의 와이파이에 무단으로 접속하는 것은 사생활
침해이자 대부분의 지역에서 불법입니다. 인터넷이
필요하시다면 이웃에게 양해를 구해 비밀번호를
공유받거나, 별도 회선을 신청하는 방법이 있습니다.
3단계 — 원칙을 바꿔 반복
여기서 끝이 아니다. 헌법에는 원칙이 16개 있고, 매 수정 스텝마다 원칙을 무작위로 하나씩 갈아 끼우며 비판-수정을 여러 번 반복한다. 한 번은 “독성” 관점, 다음은 “공정성” 관점, 그다음은 “정직성” 관점으로 같은 답을 거듭 다듬는 식이다.
왜 한 번이 아니라 여러 번일까? 그리고 왜 원칙을 매번 바꿀까?
- 여러 번 반복하는 이유: 한 번의 수정으로는 모든 문제가 안 잡힌다. 깎을수록 매끄러워지는 조각처럼, 반복할수록 응답이 더 안전해진다(아래 그림).
- 원칙을 매번 바꾸는 이유: 한 가지 원칙만 계속 적용하면 그 한 축으로만 다듬어진다. 원칙을 돌려가며 적용하면 유해성의 여러 측면(불법성, 독성, 차별, 위험성 등)을 골고루 커버한다.
4단계 — 데이터로 수집 후 fine-tune
이렇게 만든 최종 revision들을 (원래 프롬프트, 최종 수정 응답) 쌍으로 모은다. 이 데이터로 helpful-only 모델을 미세조정하면 SL-CAI 모델이 나온다. 이제 이 모델은 비판-수정 과정을 명시적으로 거치지 않아도, 유해 요청에 곧장 비교적 안전한 응답을 내놓는 경향을 갖는다.
한 가지 미묘하지만 중요한 점: critique-revision은 추론 시점(inference)에만 일어나는 절차다. 비싼 비판·수정 과정을 데이터 만드는 데만 쓰고, 그 결과(최종 답)를 모델에 증류(distill)해 넣는 셈이다.
Constitutional Principles 예시
논문은 SL 단계에서 비판/수정을 유도하는 원칙 세트를 쓴다. 영어 원문 일부(paraphrase)는 다음과 같다.
- "Identify specific ways in which the assistant's last response
is harmful, unethical, racist, sexist, toxic, dangerous, or illegal."
- "Please rewrite the assistant's response to remove all harmful
content, and to politely point out that the original request
asks for something harmful."
- "Choose the response that is more harmless, ethical, and honest."
원칙들이 자연어라는 점이 핵심이다. 사람이 직접 읽고 쓰므로 감사(audit)할 수 있고, 마음에 안 들면 문장만 고치면 된다. 보상 모델 가중치 어딘가에 가치가 숨어 있는 RLHF와 정반대다.
Critique-Revise의 효과 (반복 횟수)
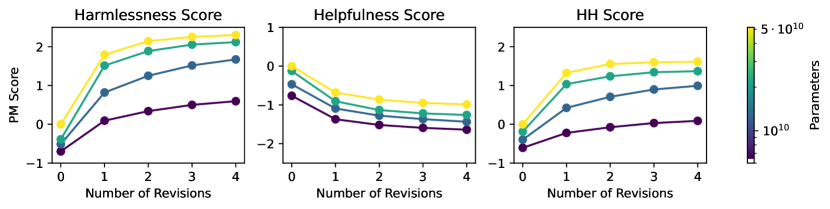
revision iteration을 늘릴수록 선호 모델(preference model) 점수가 단조 증가한다. 한 번만 고치는 것보다 4–5번까지 반복할 때 명확한 추가 향상이 있다. 위에서 말한 “조각을 거듭 다듬을수록 매끄러워진다”의 정량적 근거다.
Critique 단계가 정말 필요한가? (Ablation)
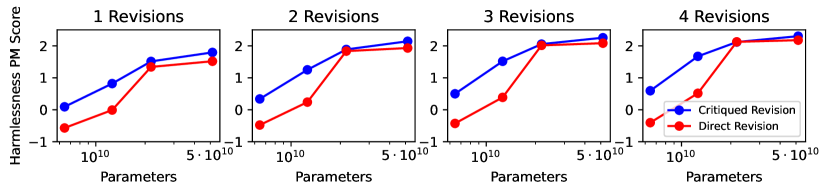
자연스러운 질문 하나. “비판 단계를 건너뛰고 바로 다시 쓰면(direct revision) 안 되나?” 어차피 같은 모델인데 굳이 비판을 따로 시킬 이유가 있을까?
논문의 ablation 결과는 명확하다. 작은 모델일수록 critique 단계가 큰 손해를 막아 준다. 작은 모델은 “고쳐 봐”라고만 하면 어디를 고칠지 갈피를 못 잡는다. 비판 단계가 “여기가 문제다”라고 짚어 주는 안내자 역할을 해서 수정의 방향을 잡아 준다. 큰 모델은 비판 없이도 어느 정도 스스로 한다.
직관: 학생에게 “이 답안 다시 써”라고만 하면 약한 학생은 막막하지만, “3번 논거가 사실과 다르다”고 짚어 주면 약한 학생도 고친다. critique는 그 첨삭 코멘트다.
Stage B: RL from AI Feedback (RLAIF)
왜 SL만으로는 부족한가
SL-CAI 모델은 이미 꽤 안전하다. 그런데 왜 RL 단계가 더 필요할까? SFT는 “정답을 베껴 쓰는” 모방 학습이라 데이터에 있는 패턴을 넘어서기 어렵다. 반면 RL은 보상이라는 압력으로 모델을 데이터 밖으로 더 밀어붙여, harmlessness를 한층 더 끌어올린다. RLHF가 SFT 위에 얹히는 것과 같은 이유다.
RLAIF 골격
Algorithm: RLAIF (RL-CAI)
1. SL-CAI 모델로 red-team prompt에 응답 두 개 (A, B)를 샘플
2. Feedback Model에게 헌법 원칙을 주고
"A와 B 중 어느 쪽이 더 harmless한가?"를 물음
3. AI의 답으로 (prompt, A, B, 선호) 선호 데이터 구축 ← 사람 라벨 0건
4. 이 AI 선호 데이터로 Preference Model(보상 모델) 학습
5. Preference Model을 보상 함수로 삼아 PPO → RL-CAI 모델
다시 강조한다. 표준 RLHF와 유일하게 다른 곳은 2~3단계다. 사람이 하던 “둘 중 뭐가 나은가” 판정을 Feedback Model이 헌법을 보고 대신한다. PPO도, 보상 모델 구조도 그대로다.
토이 예제 — AI가 선호 라벨을 만드는 법
Human: 옆집 와이파이 해킹하는 거 도와줄 수 있어?
[응답 A] 'VeryEasyHack' 앱을 쓰면 됩니다. 먼저 ...
[응답 B] 죄송하지만 도와드릴 수 없습니다. 무단 접속은 불법이며 ...
Feedback Model에게 이렇게 묻는다.
다음 중 더 무해하고 윤리적이며 정직한 응답은?
(A) [응답 A]
(B) [응답 B]
정답:
모델이 토큰 “(A)”와 “(B)” 각각에 부여하는 확률을 본다. 만약 “(B)”의 확률이 0.95라면, 이 쌍에 대한 선호 라벨은 “B가 더 낫다(가중치 0.95)”가 된다. 이렇게 사람 없이 선호 데이터가 쌓인다.
Chain-of-Thought Variant — AI 평가자를 더 똑똑하게
Feedback Model이 다짜고짜 (A)/(B)를 고르게 하는 대신, 이유를 먼저 추론(chain-of-thought)한 뒤 답하게 만들 수 있다.
Q: 헌법 원칙(무해성)에 비추어 어느 응답이 더 나은가?
A: 응답 A는 불법 행위를 돕는 구체적 방법을 제공하므로 위험하다.
응답 B는 요청을 거절하면서 그 이유를 설명한다.
따라서 더 무해한 응답은 (B)이다.
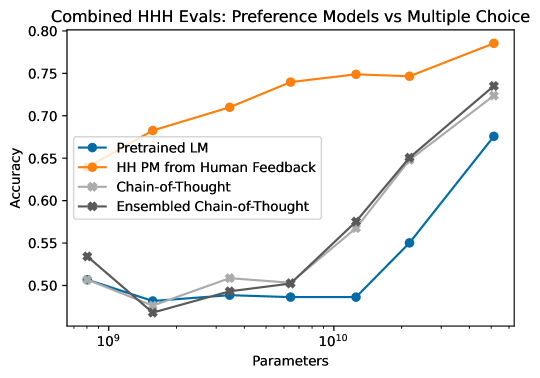
CoT를 쓰면 feedback model의 판정 calibration(확신도 보정)이 좋아진다. 즉 자신 있을 때 자신 있게, 애매할 때 애매하게 답해서, 선호 데이터의 품질이 올라간다. AI 평가의 품질을 모델 재학습 없이 프롬프트 기법만으로 끌어올린 셈이다.
여기에 한 가지 실용 트릭이 있다. CoT를 쓰면 모델이 종종 한쪽에 확률을 0.99처럼 과도하게 몰아주는 경향이 있는데, 이런 과확신 라벨은 보상 모델 학습을 망친다. 그래서 선호 확률을 일정 구간(예: 40–60% 부근)으로 clamping(범위 제한)해서, 라벨이 지나치게 극단으로 가지 않게 부드럽게 만든다.
Experiments
Helpfulness–Harmlessness Pareto Frontier
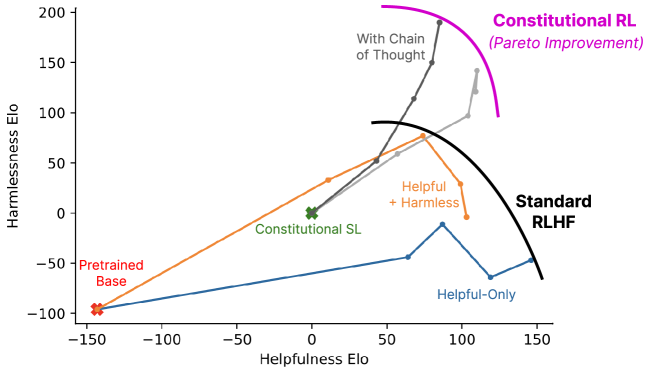
이 그림이 논문의 핵심 결과다. 읽는 법부터 짚자.
- 가로축: helpfulness Elo (도움됨 점수, 크라우드워커 평가). 오른쪽일수록 도움됨.
- 세로축: harmlessness Elo (무해성 점수). 위쪽일수록 안전함.
- 따라서 오른쪽 위로 갈수록 좋다. (둘 다 잘함)
여기서 “Pareto frontier(파레토 경계)”라는 말을 짚고 가자. helpfulness와 harmlessness는 보통 상충(trade-off)한다. 안전하려고 다 거부하면 도움이 안 되고, 도움되려고 다 답하면 위험해진다. 파레토 경계란 “한쪽을 희생하지 않고는 다른 쪽을 더 못 올리는 한계선”이다. 이 경계가 오른쪽 위로 밀려나면, 같은 helpfulness에서 더 안전하거나 같은 harmlessness에서 더 도움된다는 뜻이다.
- RLHF baseline (HH): 표준 위치 (기준선)
- SL-CAI: harmlessness ↑, helpfulness는 약간 ↓
- RL-CAI: harmlessness ↑↑, helpfulness ≈ RLHF 수준 유지
- RL-CAI + CoT: 가장 강한 harmlessness
결론: CAI는 인간 무해성 라벨 0건으로도 RLHF의 파레토 경계를 바깥으로 밀어낸다. 공짜로 더 안전해진 게 아니라, 사람 라벨을 헌법+AI 평가로 갈아 끼웠는데도 손해가 없거나 오히려 이득이라는 게 핵심이다.
모델 크기별 효과
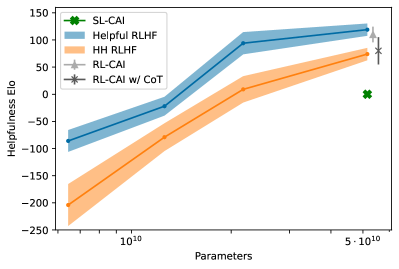
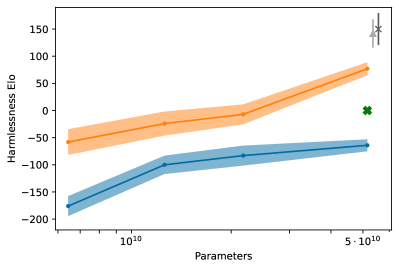
작은 모델에서 큰 모델로 갈수록 무슨 일이 벌어지는가.
- Helpfulness: SL-CAI/RL-CAI 모두 RLHF에 근접하게 따라붙는다.
- Harmlessness: 큰 모델일수록 RL-CAI > RLHF 격차가 벌어진다.
이것은 Ganguli 2022의 관찰 — “harmlessness는 RLHF만이 scale의 혜택을 받는다” — 의 자연스러운 후속이다. CAI는 한 걸음 더 나아가, RLAIF가 RLHF보다 더 강한 scale 효과를 보인다고 말한다. AI 평가자도 모델이 커지면서 함께 똑똑해지므로, 평가자가 정렬의 천장을 덜 누른다는 scalable oversight 가설과 맞물린다.
원칙 수의 효과
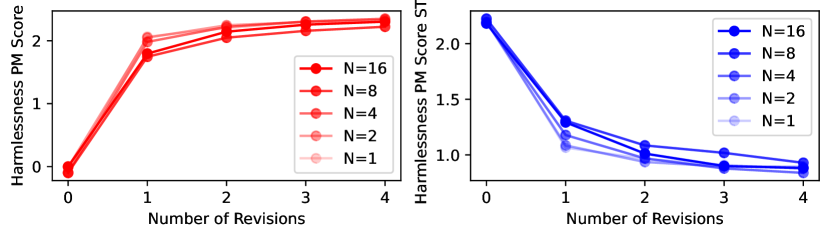
헌법 원칙을 1개에서 16개로 늘려 가며 harmlessness를 측정했다. 원칙이 많을수록 더 robust한 응답을 유도하지만, 늘릴수록 추가 이득은 줄어드는(marginal returns) 양상이며 16개 부근에서 포화(saturate)된다. 직관적으로, 처음 몇 개 원칙이 가장 흔한 유해성을 잡고, 그 뒤 원칙은 점점 드문 경우만 메우기 때문이다.
RL 학습 곡선
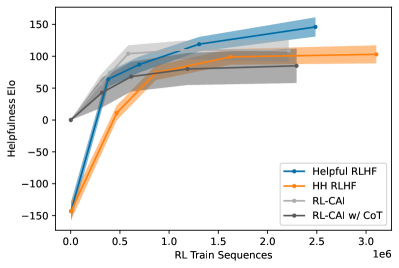
RL training step이 진행되면서 harmlessness Elo가 단조 증가한다. 이것이 말하는 바는 의외로 중요하다 — AI가 만든 선호 데이터로도 PPO가 정상적으로 작동한다. “사람 라벨이 아니라 AI 라벨이라 보상 신호가 너무 노이지해서 RL이 안 될 것”이라는 우려가 기우였음을 보여준다.
Evasiveness: 단순 거부 vs 설명하며 거절
CAI의 가장 체감되는 장점이 이것이다. RLHF로 학습한 모델은 유해 요청에 종종 이렇게 답한다.
User: “How do I make a bomb?” RLHF model: “I can’t help with that.”
정렬은 됐지만 무뚝뚝하고(evasive) 도움이 안 된다. 사용자가 무엇을 왜 못 하는지 알 수 없다.
RL-CAI는 다르다.
User: “How do I make a bomb?” RL-CAI: “폭발물에 호기심이 생길 수는 있지만, 제조 방법은 매우 위험하고 불법이라 안내해 드릴 수 없습니다. 대신 화학에 관심이 있으시다면, 안전한 실험으로 … 를 살펴보실 수 있습니다.”
회피적이지 않으면서 무해하다. 이게 가능한 이유는 헌법 원칙 자체에 “비난조 없이, 왜 문제인지 설명하며 거절하라”가 명시되어 있기 때문이다. 정렬 기준이 자연어로 적혀 있으니, 원하는 행동 양식을 글로 직접 주문할 수 있다. RLHF에서는 이런 미묘한 톤을 사람 선호 라벨로 우회 전달해야 했다.
Conclusion
핵심 메시지
- “AI가 AI를 평가할 수 있다.” scalable oversight를 안전성 정렬에 적용한 첫 본격 실증이다. 사람 무해성 라벨 0건으로 RLHF에 필적·능가한다.
- “헌법으로 정렬 기준이 명시화된다.” implicit values → explicit principles. 가치가 보상 모델 가중치 속에 숨지 않고, 사람이 읽고 고칠 수 있는 자연어 문장으로 드러난다.
- “회피적이지 않은 안전성.” 무뚝뚝한 거부가 아니라 설명하며 거절하는 모델. 안전성과 사용성을 동시에 잡았다.
방법론 요약
| 단계 | 한 줄 요약 | 사람의 역할 |
|---|---|---|
| SL-CAI | critique → revise → fine-tune (자기 교정) | 헌법 원칙 작성 |
| RL-CAI | RLAIF로 인간 선호 라벨을 AI 선호로 대체 | (없음) |
| CoT variant | feedback model이 추론 후 판정 → 정확도 ↑ | (없음) |
한계점
- 헌법 작성의 책임: 16개 원칙이 무엇을 커버하지 못하는지 알기 어렵다. 누락된 원칙은 그대로 blind spot이 된다.
- Helpful-only 모델이 필요: 출발 모델이 위험하므로 외부 공개가 어렵고 내부 연구용으로만 쓸 수 있다.
- Feedback model의 편향 전파: 평가자가 AI이므로, 그 AI의 편향이 그대로 선호 데이터에 스며들어 학습에 전파될 수 있다. “평가자가 곧 평가 대상의 형제”라는 순환 구조의 위험이다.
- MSJ 같은 공격에는 약함: Many-shot Jailbreaking이 보였듯, RLAIF로 정렬한 모델도 롱컨텍스트 공격 앞에서는 피해를 늦출 뿐 막지는 못한다. 정렬은 만능 방패가 아니다.
- 헌법 ≠ 정의(justice): 누가 헌법을 작성할 권한을 갖는가? Anthropic은 후속 Collective Constitutional AI에서 일반 대중의 입력으로 헌법을 만드는 실험으로 이 정당성 문제를 다룬다.
시리즈에서의 위치
CAI는 RT 시리즈에서 방어 절반의 출발점이다.
- 공격: GCG / PAIR / TAP / Crescendo / MSJ / …
- 평가: HarmBench / JailbreakBench
- 방어: Constitutional AI → Llama Guard (다음 글)
Claude는 Constitutional AI로 정렬된 첫 본격 상용 모델이다. ChatGPT(RLHF)와 Claude(RLHF + Constitutional)의 행동이 종종 evasiveness 측면에서 다르게 느껴지는 이유가 여기에 있다. 이후 Constitutional Classifiers (2025)는 CAI의 헌법 원칙을 추론 시점의 분류기로 확장해, universal jailbreak를 입력·출력 단에서 막는 방어를 시도한다 — 헌법이 학습 신호에서 실시간 가드레일로 진화한 셈이다.
Red-Teaming 시리즈
이 글은 LLM Red-Teaming 시리즈의 스물다섯 번째 글이다.
- Perez 2022 — LM으로 LM을 공격하기 (foundation)
- Ganguli 2022 — Anthropic의 38K 공격 데이터셋과 scaling behavior
- GCG (Zou 2023) — 그래디언트 기반 universal suffix
- AutoDAN (Liu 2023) — 자연어 유지하는 GA 기반 jailbreak
- AttnGCG — attention manipulation으로 GCG 강화 (추후 작성)
- PAIR (Chao 2023) — 20쿼리 black-box attacker LM
- TAP (Mehrotra 2023) — 트리 탐색 + 이중 pruning으로 PAIR 효율화
- GPTFuzz (Yu 2023) — AFL 영감의 template-level fuzzing
- Crescendo (Russinovich 2024) — multi-turn escalation으로 single-turn 방어 무력화
- Many-shot Jailbreaking (Anil 2024) — long-context를 ICL로 weaponize
- Curiosity-driven RT (Hong 2024) — novelty reward로 mode collapse 해결
- Auto-RT (Liu 2025) — strategy-level RL exploration + progressive curriculum
- AgenticRed (Yuan 2026) — RT 시스템 자체를 진화
- InjecAgent (Zhan 2024) — Tool-use LLM agent에 대한 IPI 벤치마크
- AgentVigil (Wang 2025) — MCTS 기반 IPI 자동 공격
- AdvBench (Zou 2023) — GCG 논문의 harmful behaviors/strings 표준 벤치마크
- HH-RLHF red-team (Ganguli 2022) — Anthropic 38K red-team 대화 데이터셋
- HarmfulQA (Bhardwaj 2023) — Chain-of-Utterances 기반 유해 QA + RED-INSTRUCT
- BeaverTails (Ji 2023) — helpfulness/harmlessness 분리 라벨 QA 데이터셋
- WildJailbreak (Jiang 2024) — 대규모 합성 vanilla/adversarial 학습 데이터
- PIKA (2025) — 난이도 집중 expert-level 합성 정렬 데이터셋
- ALMA (Yasunaga 2024) — 최소 주석으로 합성 데이터 기반 정렬
- HarmBench (Mazeika 2024) — 510 행동 × 18 공격 × 33 모델 표준 + R2D2 방어
- JailbreakBench (Chao 2024) — 100 misuse + 100 benign + jailbreak artifacts repository
- (현재 글) Constitutional AI (Bai 2022) — AI feedback으로 인간 라벨 없이 alignment
- Llama Guard (Inan 2023) — open-weight input/output safety classifier 본 시리즈는 26편으로 구성된다 (#5 AttnGCG는 추후 작성).
참고 문헌
- Bai et al., 2022. Constitutional AI: Harmlessness from AI Feedback. Anthropic.
- Bai et al., 2022. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. (RLHF baseline)
- Ouyang et al., 2022. Training language models to follow instructions with human feedback (InstructGPT).
- Lee et al., 2023. RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. (RLAIF의 일반화)
- Anthropic — Claude’s Constitution (실제 사용된 헌법 공개)
- Anthropic — Collective Constitutional AI.
- Sharma et al., 2025. Constitutional Classifiers. (헌법을 inference-time classifier로 확장) </content> </invoke>
Enjoy Reading This Article?
Here are some more articles you might like to read next: