DsDm: Model-Aware Dataset Selection with Datamodels
Introduction
기존 데이터 선택 방법들은 “좋은 데이터”를 정의할 때 학습 알고리즘을 무시한다. DSIR은 타겟 분포와의 n-gram 유사도를, QuRating은 LLM이 판단한 텍스트 품질을 기준으로 삼는다. 하지만 이런 접근은 본질적인 질문을 빠뜨린다: “학습 알고리즘이 이 데이터를 실제로 어떻게 사용하는가?”
DsDm의 저자들은 먼저 충격적인 사실을 보여준다: DSIR, Classifier 기반 필터링, SemDeDup 등 기존 방법들이 랜덤 선택을 안정적으로 이기지 못한다. Wikipedia와 비슷한 데이터가 “고품질”이라는 가정 자체가 틀렸을 수 있다는 것이다.
DsDm은 완전히 다른 접근을 취한다. Datamodel을 사용하여 “어떤 학습 데이터가 타겟 태스크 성능에 실제로 기여하는가”를 직접 추정하고, 이를 기반으로 데이터를 선택한다. 결과적으로 DsDm으로 선택한 데이터로 학습하면, 랜덤 데이터 대비 2배의 compute 효율을 달성한다.
Background
Datamodel이란?
Datamodel은 “학습 데이터 구성 → 모델 출력”의 매핑을 근사하는 함수이다. 핵심 아이디어는 이렇다: 학습 데이터의 서브셋을 바꾸면 학습된 모델의 출력도 바뀐다. 이 관계를 명시적으로 모델링할 수 있다면, 최적의 학습 서브셋을 직접 계산할 수 있다.
구체적으로, 후보 데이터 풀 \(\mathcal{S}\)에서 크기 \(k\)의 서브셋 \(S\)를 선택할 때, 특정 타겟 샘플 \(x\)에 대한 예상 손실을 다음과 같이 정의한다:
\[\mathcal{L}_x(S) := \mathbb{E}[\ell(x; \mathcal{A}(S))]\]여기서 \(\mathcal{A}\)는 학습 알고리즘이고 \(\ell\)은 손실 함수이다. 이 함수를 정확히 계산하려면 모든 가능한 서브셋에 대해 모델을 학습시켜야 하므로 당연히 intractable하다.
TRAK Estimator
DsDm은 이 복잡한 매핑을 선형 함수로 근사한다:
\[\tau_{\theta_x}(\mathbb{1}_S) := \theta_x^\top \cdot \mathbb{1}_S\]| 여기서 \(\mathbb{1}_S\)는 서브셋 \(S\)의 indicator 벡터(\(S\)에 포함된 데이터는 1, 아니면 0)이고, $$\theta_x \in \mathbb{R}^{ | \mathcal{S} | }\(는 각 학습 데이터가 타겟 샘플\)x$$의 손실에 미치는 영향을 나타내는 파라미터이다. |
이 \(\theta_x\)를 추정하기 위해 TRAK (TRAining data Attribution using Kernel regression) estimator를 사용한다. TRAK은 여러 random 서브셋으로 proxy 모델을 학습시킨 뒤, 각 학습 데이터의 영향력을 추정한다.
Method
최적화 문제 정의
DsDm의 목표는 타겟 태스크 분포 \(\mathcal{D}_\text{targ}\)에 대한 손실을 최소화하는 크기 \(k\)의 서브셋을 찾는 것이다:
\[S^* := \underset{S \subset \mathcal{S},\ |S| = k}{\arg\min}\ \mathcal{L}_{\mathcal{D}_\text{targ}}(S)\]Datamodel 근사를 적용하면, 타겟 분포에 대한 예상 손실은:
\[\hat{\mathcal{L}}_{\mathcal{D}_\text{targ}}(S) = \mathbb{1}_S^\top \left( \frac{1}{n} \sum_{i=1}^{n} \theta_{x_i} \right)\]이것을 최소화하는 \(k\)개를 선택하면 된다. 즉, 타겟 샘플들에 대한 datamodel 파라미터를 평균한 뒤, 값이 가장 작은(= 손실을 가장 많이 줄이는) \(k\)개를 선택한다:
\[\hat{S}_\text{DM} := \text{argbot-}k \left( \frac{1}{n} \sum_{i=1}^{n} \theta_{x_i} \right)\]DsDm 알고리즘 전체 흐름
| 단계 | 내용 | 비용 |
|---|---|---|
| 1. Proxy 모델 학습 | C4의 랜덤 서브셋으로 125M 모델 다수 학습 | 주요 비용 |
| 2. TRAK 추정 | 각 타겟 샘플에 대한 \(\theta_x\) 계산 | amortizable |
| 3. 파라미터 평균 | 타겟 샘플들의 \(\theta_x\) 평균 | 무시할 수준 |
| 4. Top-k 선택 | 평균 파라미터가 가장 작은 \(k\)개 선택 | 무시할 수준 |
| 5. Full-scale 학습 | 선택된 데이터로 125M~1.3B 모델 학습 | — |
핵심 포인트: proxy 모델(125M)로 추정한 데이터 선택이 더 큰 모델(1.3B)에도 그대로 전이된다. 한 번 TRAK 파라미터를 계산하면 다양한 크기와 조합으로 재사용할 수 있어 비용이 amortize된다.
Experiments
실험 설정
- 후보 데이터 풀: C4 English (~2.17억 문서, 각 1024 토큰)
- 타겟 태스크: LAMBADA (언어 이해), SQuAD (독해), Jeopardy (세계 지식), CS-Algorithms (코딩)
- 모델 크기: 125M, 356M, 760M, 1.3B (Chinchilla-optimal 토큰 비율)
- Baseline: Random, DSIR, Classifier, SemDeDup
Task-Optimal 데이터 선택
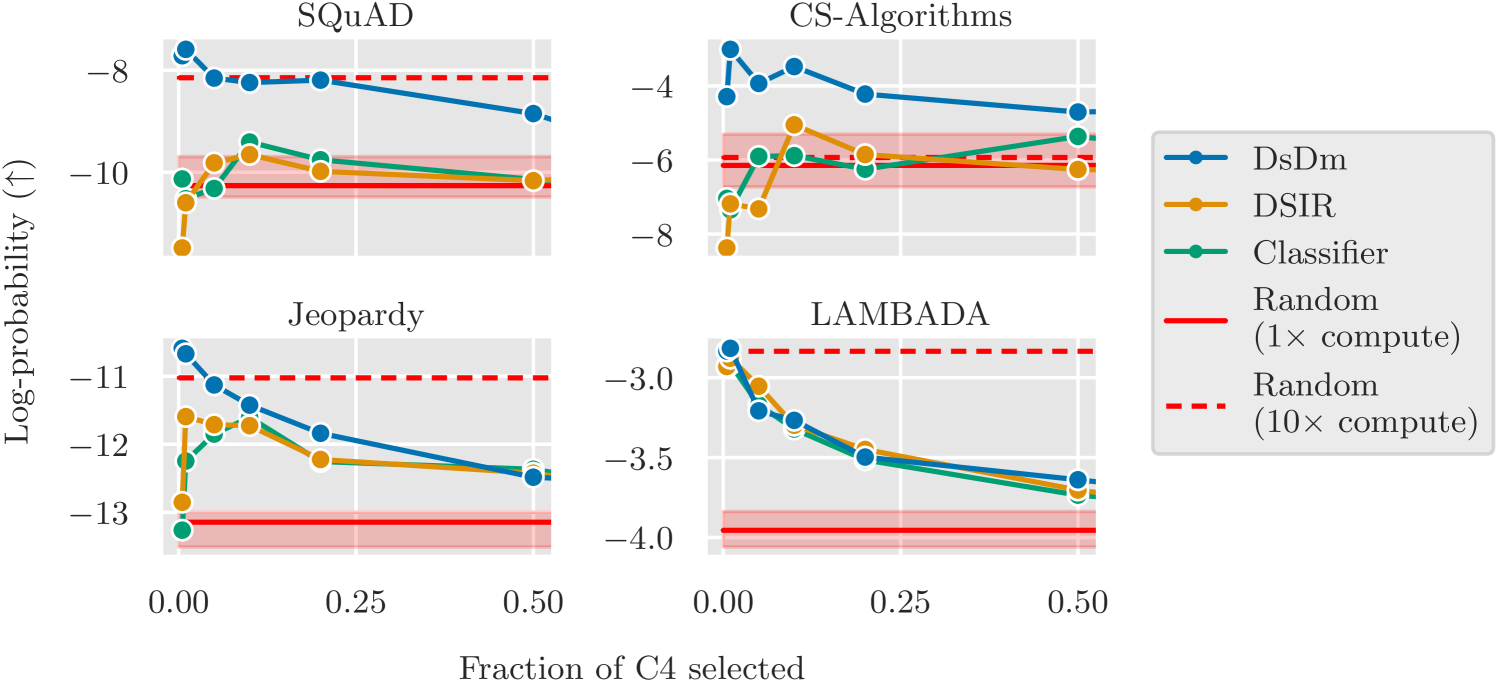
125M 모델에서 4개 타겟 태스크에 대한 결과이다. X축은 C4에서 선택한 데이터 비율, Y축은 log-probability (높을수록 좋음)이다.
- DsDm (파란선)은 모든 태스크에서 일관되게 최고 성능
- Classifier, DSIR (초록, 주황)은 랜덤 선택을 안정적으로 이기지 못함
- DsDm 125M 모델이 10배 compute의 Random 1.3B 모델(빨간 점선)에 필적하는 성능
이것은 놀라운 결과이다. DSIR이나 Classifier는 “Wikipedia와 비슷한 데이터 = 좋은 데이터”라는 가정에 기반하는데, 이 가정이 실제로는 맞지 않을 수 있다.
“유용한 데이터 ≠ 비슷한 데이터”
DsDm이 선택하는 데이터는 기존 방법과 질적으로 다르다:
- Classifier/DSIR: SQuAD 타겟 → Wikipedia 스타일의 “깔끔한” 텍스트 선택
- DsDm: SQuAD 타겟 → QA 형식의 텍스트 선택 (형식적으로는 덜 세련됨)
DsDm이 선택한 데이터 중 일부는 표면적으로 “질 낮아 보이는” 텍스트도 포함한다. 하지만 이 텍스트들이 실제로 모델의 독해 능력 향상에 기여한다. 외형적 품질이 아닌 학습 효용을 기준으로 선택하기 때문이다.
더 흥미로운 점: DsDm은 “유해한” 학습 데이터도 식별한다. QA 형식이지만 성능을 떨어뜨리는 데이터(잘못된 정보 등)는 낮은 순위로 밀려나는데, baseline 방법들은 이런 구분을 전혀 하지 못한다.
Broad Model Capabilities
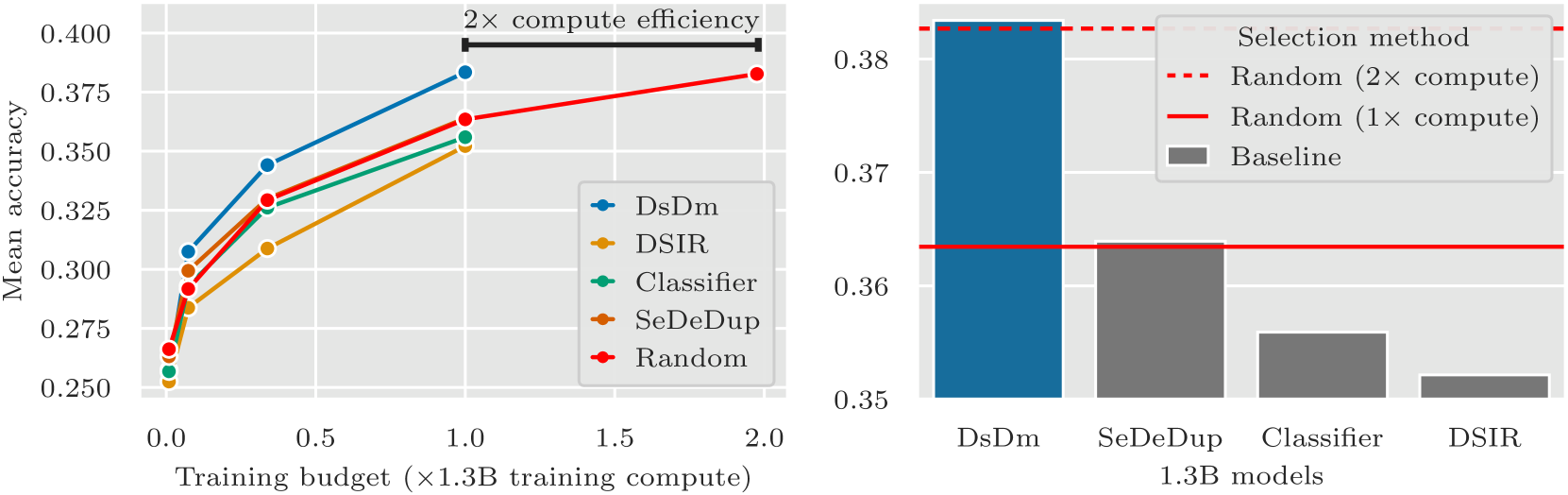
LAMBADA + SQuAD + Jeopardy를 결합한 타겟으로 125M~1.3B 모델을 학습하고, 15개 표준 벤치마크에서 평가한 결과이다.
왼쪽 그래프에서 핵심 관찰:
- DsDm 1.3B 모델의 성능 ≈ Random 2× compute 모델 → 2배 compute 효율
- DSIR, Classifier, SemDeDup 모두 Random과 동등하거나 그보다 나쁨
- Random이 오히려 강력한 baseline이라는 사실 자체가 기존 방법들의 한계를 보여줌
오른쪽 바 차트(1.3B 모델)에서도 DsDm만 Random (2× compute) 수준에 도달하고, 나머지는 Random (1× compute)과 비슷하다.
카테고리별 성능 분석
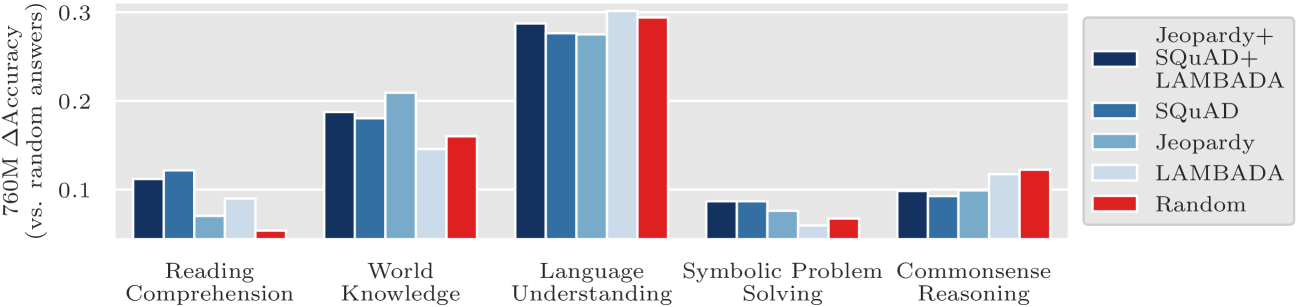
타겟 태스크를 바꾸면 개선되는 벤치마크 카테고리도 달라진다:
| 타겟 태스크 | 가장 큰 개선 카테고리 |
|---|---|
| SQuAD | Reading Comprehension (+3~8%) |
| Jeopardy | World Knowledge (+3~8%) |
| LAMBADA | Language Understanding |
| 3개 결합 | 전체적으로 균형 잡힌 개선 |
이를 통해 타겟 태스크의 선택이 모델의 능력 프로필을 직접적으로 형성한다는 것을 알 수 있다. 특정 도메인만 타겟하면 다른 도메인은 소폭 저하될 수 있으므로, 복합 타겟이 가장 균형 잡힌 모델을 만든다.
1.3B 모델 상세 벤치마크
| 카테고리 | 대표 벤치마크 | DsDm | Random (1×) | 차이 |
|---|---|---|---|---|
| Reading Comp. | CoQA | +7% | baseline | +7% |
| Reading Comp. | NewsQA | +8% | baseline | +8% |
| World Knowledge | BB QA Wikidata | +8% | baseline | +8% |
| Language Understanding | LAMBADA | +2% | baseline | +2% |
| Commonsense | HellaSwag | +1% | baseline | +1% |
가장 큰 개선은 Reading Comprehension과 World Knowledge에서 나타난다. Commonsense Reasoning은 상대적으로 개선폭이 작다.
Inverse-DsDm: 검증 실험
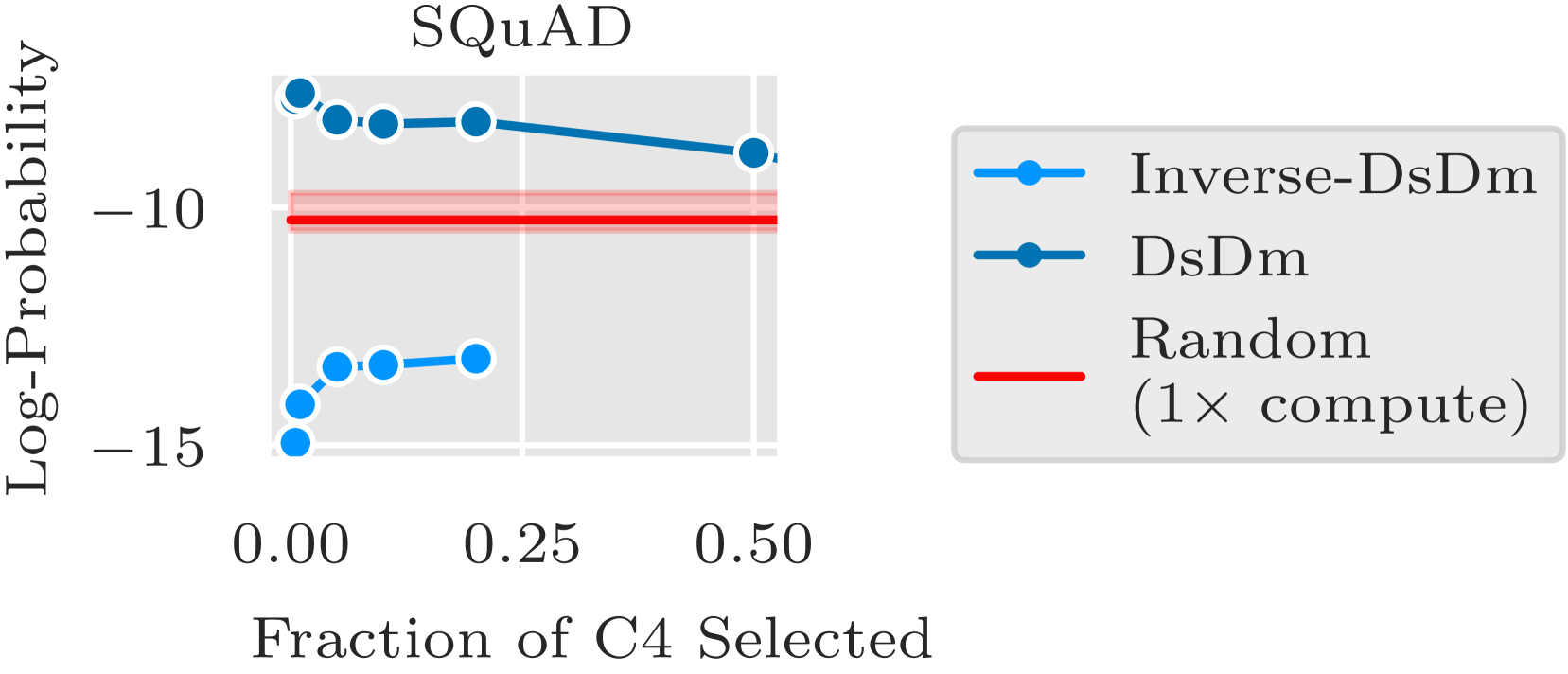
DsDm이 실제로 의미 있는 신호를 포착하는지 확인하기 위해, Inverse-DsDm (DsDm 점수가 가장 높은, 즉 가장 “나쁜” 데이터를 선택)을 실행했다. 예상대로 Inverse-DsDm은 Random보다 훨씬 나쁜 성능을 보여, DsDm의 데이터 순위가 실제로 학습 효용을 반영한다는 것을 확인할 수 있다.
Conclusion
DsDm은 데이터 선택 문제를 학습 알고리즘의 관점에서 재정의했다. 핵심 메시지는 두 가지이다:
- “좋은 데이터”의 기존 정의는 틀렸다 — Wikipedia와의 유사도, perplexity, 텍스트 품질 같은 휴리스틱은 모델이 실제로 무엇을 배우는지 반영하지 못한다
- 학습 알고리즘을 인식하는 데이터 선택이 필요하다 — Datamodel을 통해 각 학습 데이터의 실제 기여도를 측정하면 2배의 compute 효율을 달성할 수 있다
한계점으로는, 다수의 proxy 모델 학습이 필요한 초기 비용이 크다는 점과, 특정 태스크만 타겟하면 다른 도메인 성능이 저하될 수 있다는 점이 있다. 하지만 proxy 모델 비용은 한 번 계산하면 재사용 가능하므로 대규모 데이터셋의 수명 동안 amortize할 수 있다.
데이터 선택의 다른 접근이 궁금하다면 분포 매칭 기반의 DSIR과 LLM 품질 판단 기반의 QuRating도 참고하자.
참고 문헌
Enjoy Reading This Article?
Here are some more articles you might like to read next: