Data Selection for Language Models via Importance Resampling
Data Selection for Language Models via Importance Resampling
Introduction
언어 모델의 성능은 학습 데이터의 품질에 크게 좌우된다. GPT-3는 Common Crawl에서 품질 필터링을 거친 데이터를 사용했고, PaLM은 소셜 미디어 대화와 웹 문서를 섞어서 썼다. 하지만 이런 데이터 선택 과정은 대부분 휴리스틱에 의존하거나, 전문가가 수작업으로 큐레이션하는 방식이었다.
이 논문은 데이터 선택 문제를 분포 매칭(distribution matching) 관점에서 형식화한다. 핵심 질문은 이렇다: “대규모 raw 데이터셋에서, 원하는 타겟 분포와 가장 비슷한 서브셋을 어떻게 효율적으로 선택할 수 있을까?”
저자는 DSIR (Data Selection with Importance Resampling)을 제안한다. 통계학의 importance resampling 기법을 텍스트 데이터에 적용하되, hashed n-gram feature 공간에서 분포를 추정하여 계산 비용을 극적으로 낮춘다. 결과적으로 The Pile의 1억 문서를 4.5시간 만에 단일 CPU 노드에서 처리할 수 있다.
Background
Importance Resampling이란
Importance resampling은 한 분포(raw 분포 \(q\))에서 뽑은 샘플을, 다른 분포(타겟 분포 \(p\))에서 뽑은 것처럼 변환하는 기법이다. 핵심은 importance weight를 계산하는 것이다:
\[w(x) = \frac{p(x)}{q(x)}\]타겟 분포 \(p\)에서 나올 확률이 높은 샘플일수록 weight가 크고, raw 분포 \(q\)에서만 자주 나오는 샘플은 weight가 작다. 이 weight에 비례하여 리샘플링하면, 결과적으로 타겟 분포에 가까운 서브셋을 얻을 수 있다.
문제: 고차원 텍스트에서의 밀도 추정
하지만 텍스트는 고차원 데이터이다. Raw 텍스트 공간에서 \(p(x)\)와 \(q(x)\)를 직접 추정하는 것은 통계적으로 불가능하다(intractable). 그래서 DSIR은 저차원 feature 공간에서 분포를 추정하는 접근을 취한다.
Method
Step 1: Hashed N-gram Feature Extraction
DSIR은 텍스트를 hashed n-gram feature로 변환한다. 구체적으로:
- 각 텍스트 \(x\)에서 unigram과 bigram 목록을 생성한다
- 각 n-gram을 \(m\)개의 버킷 중 하나로 해싱한다 (논문에서는 \(m = 10{,}000\))
- 각 버킷의 등장 횟수를 세어 \(m\)차원 벡터 \(z \in \mathbb{N}^m\)을 만든다
예를 들어 “Alice is eating”이라는 텍스트는:
- Unigrams: [Alice, is, eating]
- Bigrams: [Alice is, is eating]
- 각 n-gram을 해싱 → 해시 인덱스 [1, 3, 3, 2, 0]
- 카운트 벡터 → \(z = [1, 1, 1, 2, 0, \ldots]\)
이렇게 하면 텍스트의 표면적 어휘 분포를 포착하면서도, \(m = 10{,}000\)차원이라는 다루기 쉬운 공간으로 축소할 수 있다.
Step 2: Bag-of-Ngrams 생성 모델로 분포 추정
Feature 공간에서 raw 분포 \(\hat{q}_\text{feat}\)과 타겟 분포 \(\hat{p}_\text{feat}\)를 추정해야 한다. DSIR은 bag-of-ngrams 생성 모델을 사용한다:
\[\mathbb{P}(z; \gamma) = \prod_{j=1}^{m} \gamma[j]^{z[j]}\]여기서 \(\gamma[j]\)는 \(j\)번째 해시 버킷의 발생 확률이다. 이 파라미터는 단순히 빈도를 세는 것만으로 추정할 수 있다:
\[\hat{\gamma} = \frac{1}{\sum_i \mathbf{1}^\top \tilde{z}_i} \sum_j \tilde{z}_j\]즉, 전체 데이터에서 각 해시 버킷이 나타나는 비율을 계산하면 된다. 이 과정을 raw 데이터와 타겟 데이터 각각에 대해 수행하면 \(\hat{q}_\text{feat}\)와 \(\hat{p}_\text{feat}\)를 얻는다.
Step 3: Importance Resampling
각 raw 데이터 포인트 \(z_i\)에 대해 importance weight를 계산한다:
\[w_i = \frac{\hat{p}_\text{feat}(z_i)}{\hat{q}_\text{feat}(z_i)}\]그리고 이 weight에 비례하는 확률로 \(k\)개의 샘플을 비복원 추출(without replacement)한다. 비복원 추출은 Gumbel top-k trick을 사용하여 효율적으로 수행한다.
이 세 단계를 정리하면 다음과 같다:
| 단계 | 내용 | 계산 비용 |
|---|---|---|
| 1. Feature 추출 | hashed n-gram 벡터 계산 | 전체 시간의 ~97% |
| 2. 분포 추정 | 빈도 카운팅으로 \(\hat{p}, \hat{q}\) 학습 | 무시할 수준 |
| 3. 리샘플링 | weight 기반 비복원 추출 | 6분 이내 |
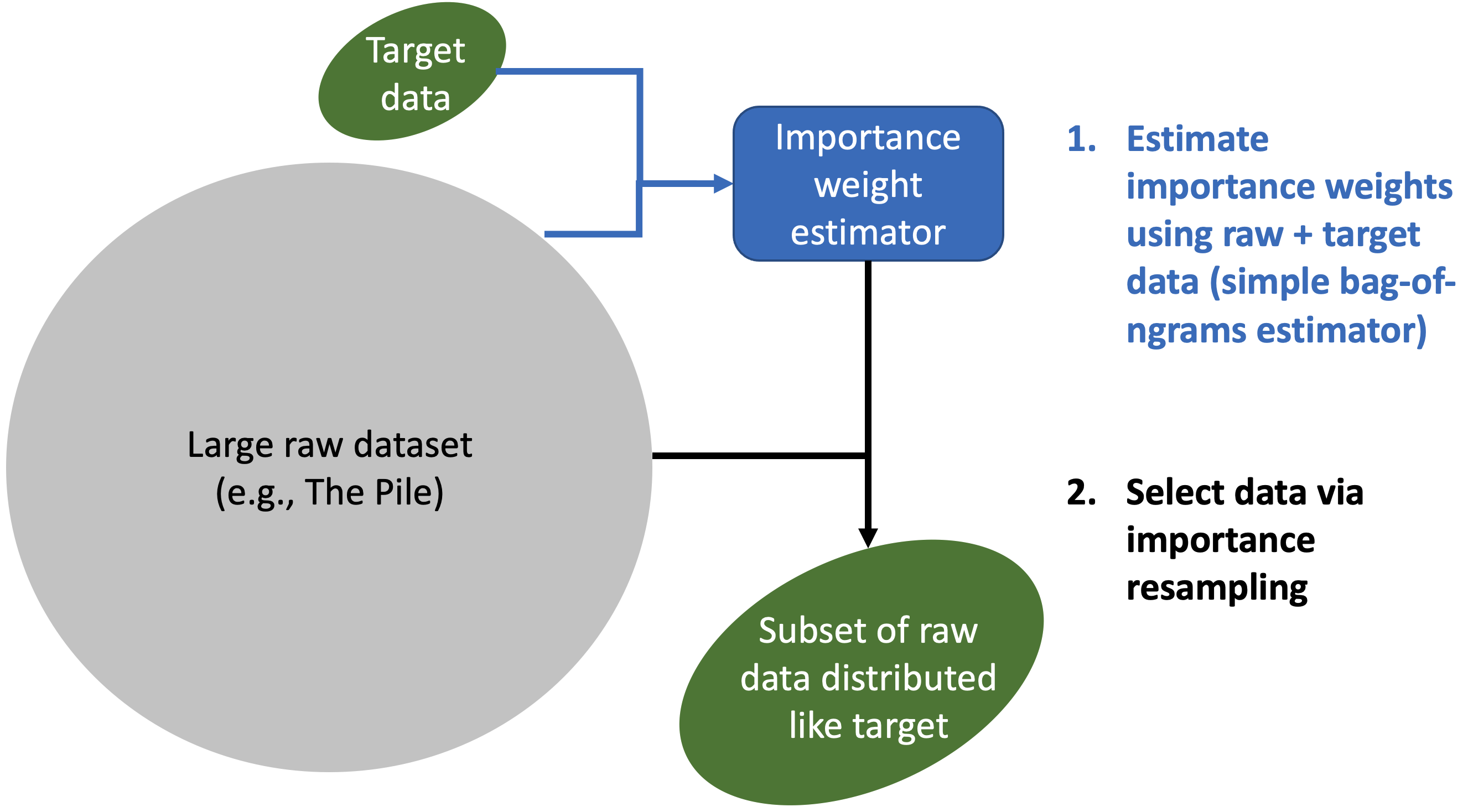
DSIR 파이프라인의 핵심은 단순함이다. 뉴럴 네트워크 학습도 없고, GPU도 필요 없다. 해시 버킷 빈도만 세면 된다.
KL Reduction: 데이터 선택 품질 측정 지표
저자는 데이터 선택 방법의 품질을 측정하는 지표로 KL reduction을 제안한다:
\[\text{KL-reduction}(p'_\text{feat}; \hat{q}_\text{feat}, \mathcal{T}) = \frac{1}{|\mathcal{T}|} \sum_{\hat{p}_\text{feat} \in \mathcal{T}} \left[ \text{KL}(\hat{p}_\text{feat} \| \hat{q}_\text{feat}) - \text{KL}(\hat{p}_\text{feat} \| p'_\text{feat}) \right]\]직관적으로 해석하면, “선택된 데이터의 분포 \(p'_\text{feat}\)이 랜덤 선택(\(\hat{q}_\text{feat}\)) 대비 타겟 분포에 얼마나 더 가까워졌는가”를 측정하는 것이다. KL reduction이 클수록 타겟 분포에 더 잘 매칭된 것이다.
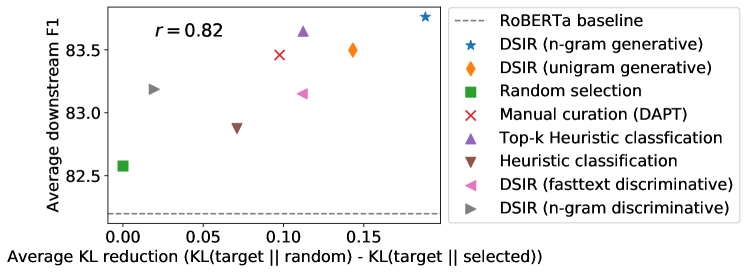
8개의 데이터 선택 방법에 걸쳐 KL reduction과 downstream 정확도 사이의 Pearson 상관계수가 r = 0.82로 매우 높다. 이는 hashed n-gram feature 공간에서의 KL reduction이 실제 downstream 성능을 잘 예측한다는 것을 의미한다.
Experiments
Domain-Specific Continued Pretraining
8개의 도메인별 타겟 데이터셋(CS, Biomedical, News, Reviews)에 대해 The Pile에서 데이터를 선택하고, RoBERTa를 continued pretraining한 뒤 downstream 태스크를 평가했다.
| Method | Avg F1 |
|---|---|
| RoBERTa (continued pretrain 없음) | 82.20 |
| Random selection | 82.58 |
| Heuristic classification | 82.88 |
| Top-k Heuristic | 83.65 |
| DAPT (전문가 큐레이션) | 83.46 |
| DSIR | 83.76 |
- DSIR은 전문가 큐레이션(DAPT)보다 0.3% 높은 성능을 달성했다
- 랜덤 선택 대비 1.18% 향상
- 8개 도메인 중 대부분에서 top-k보다 같거나 높은 성능
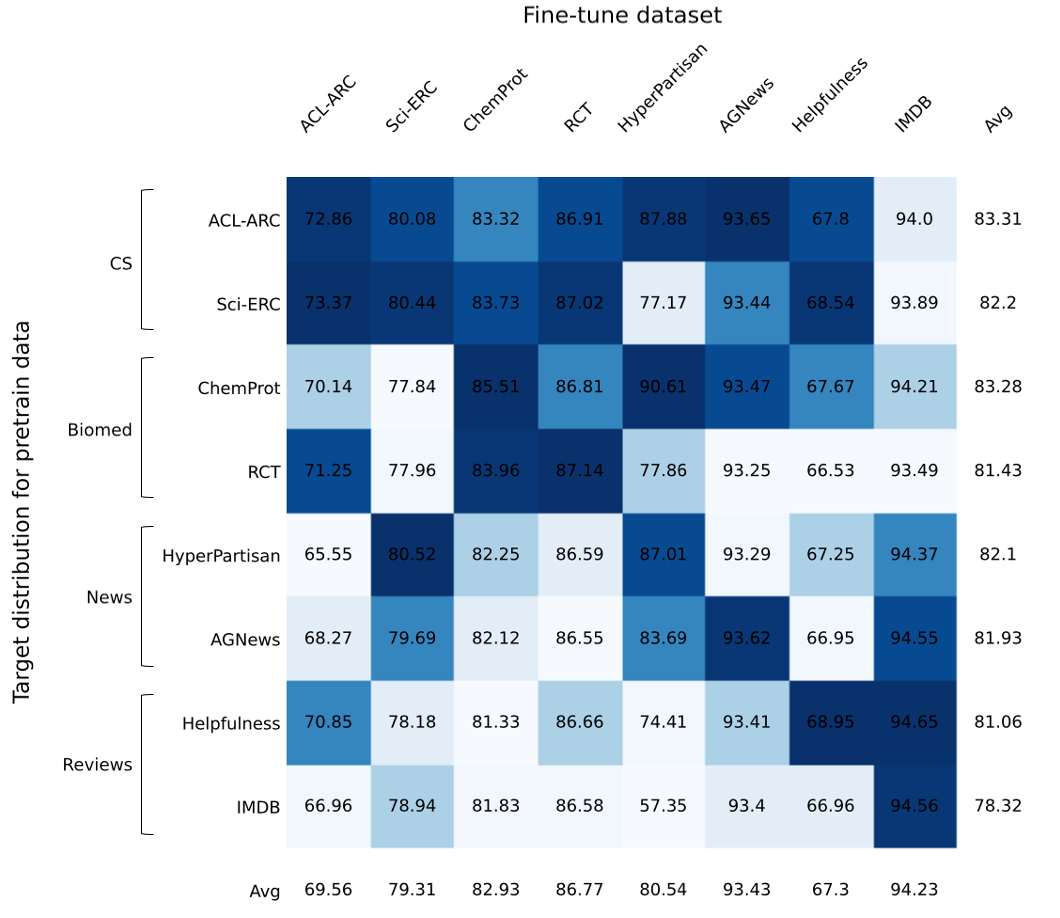
위 히트맵은 각 타겟 분포로 선택한 pretraining 데이터가 서로 다른 fine-tune 태스크에 얼마나 잘 전이되는지 보여준다. 같은 도메인 내에서의 F1 (82.9%)이 교차 도메인 F1 (81.2%)보다 1.7% 높아, 도메인 매칭이 실제로 중요하다는 것을 확인할 수 있다.
DSIR이 선택하는 데이터의 분포
DSIR이 어떤 데이터를 선택하는지 살펴보면 직관적으로 이해할 수 있다.
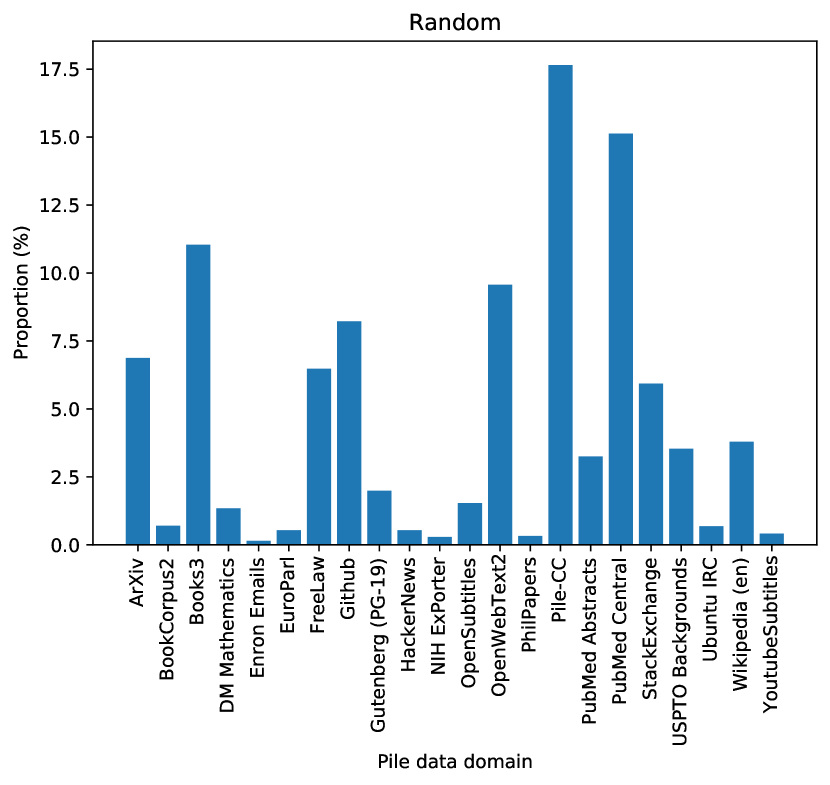
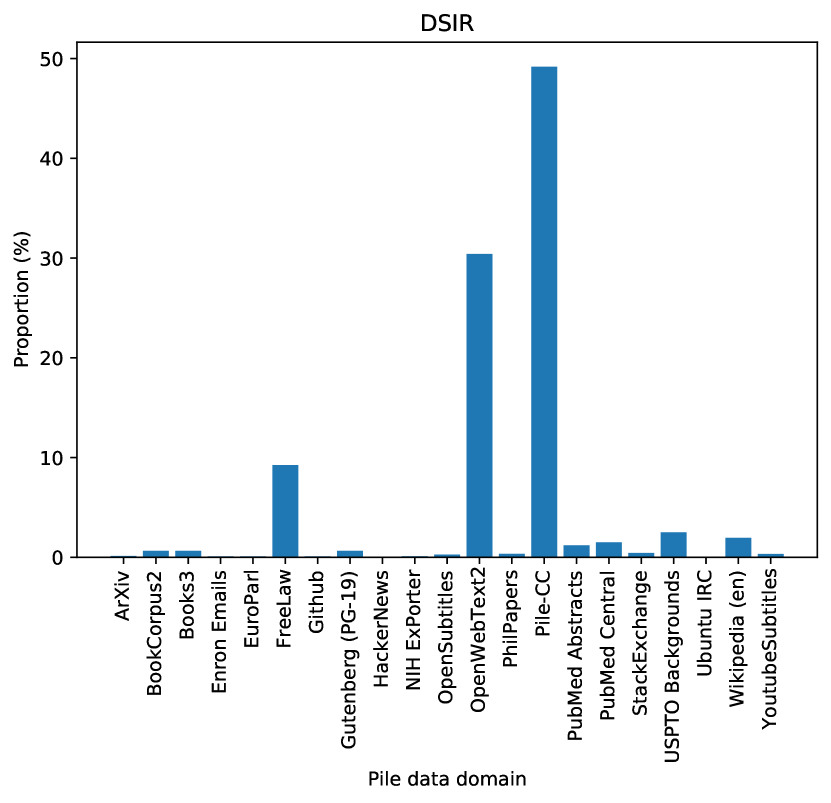
왼쪽은 랜덤 선택, 오른쪽은 DSIR 선택의 Pile 도메인별 비율이다. 타겟이 Wikipedia+Books일 때, DSIR은 Pile-CC (49%)와 OpenWebText2 (30%)에 집중하는 반면, 랜덤은 모든 도메인에서 고르게 뽑는다. DSIR이 타겟과 유사한 텍스트 분포를 가진 도메인을 자동으로 식별한다는 것을 보여준다.
도메인별 타겟에서는 더 극적이다:
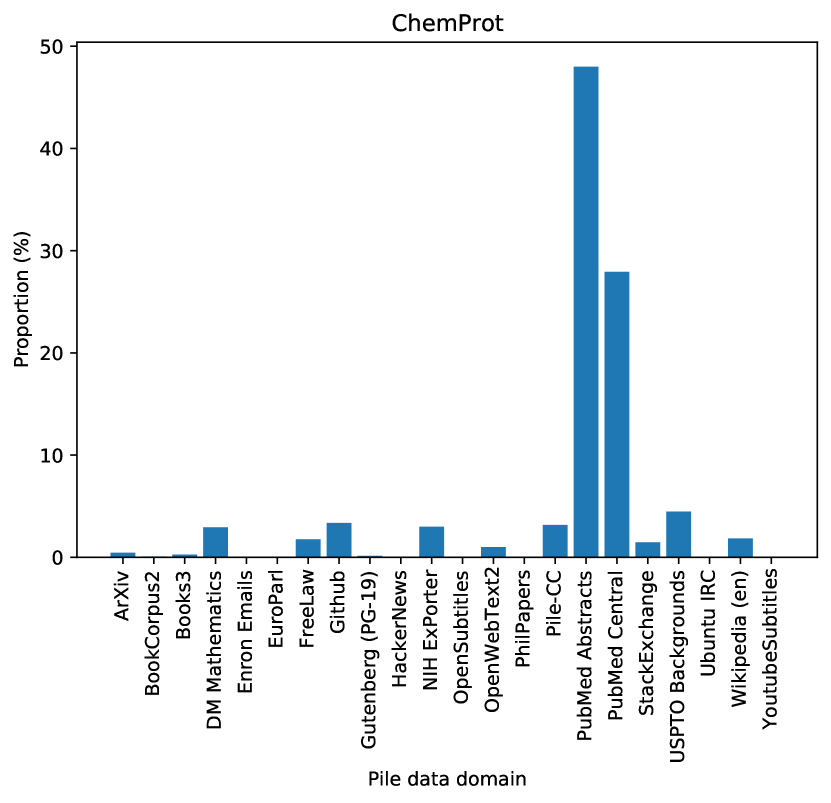
ChemProt(생화학) 타겟의 경우, DSIR은 PubMed Abstracts (48%)와 PubMed Central (28%)을 집중 선택한다. 생물의학 논문 도메인이 화학-단백질 관계 추출 태스크에 가장 유용한 pretraining 데이터라는 직관과 정확히 일치한다.
General-Domain Pretraining
타겟을 Wikipedia + Books로 설정하여 범용 언어 모델을 학습한 결과:
| Method | GLUE Avg |
|---|---|
| Random selection | 80.25 |
| Heuristic classification | 79.85 |
| Top-k Heuristic | 81.47 |
| DSIR | 82.30 |
| Top-k DSIR | 81.38 |
DSIR은 랜덤 선택 대비 GLUE에서 +2.05% 향상을 달성했다. 흥미로운 점은 top-k 선택보다 importance resampling이 더 좋다는 것이다. Top-k는 weight가 가장 높은 \(k\)개만 선택하므로 다양성이 부족해지지만, importance resampling은 weight에 비례하여 확률적으로 샘플링하므로 관련성(relevance)과 다양성(diversity) 사이의 균형을 자동으로 맞춘다.
확장성 (Scalability)
| 단계 | 소요 시간 |
|---|---|
| Importance weight 계산 | 4.36시간 |
| Resampling (1억 문서) | < 6분 |
| 전체 | ~4.5시간 |
96코어 CPU 노드 1대, 96GB RAM으로 The Pile 전체(1억 문서)를 처리한다. 특히 리샘플링 단계는 선택할 문서 수와 무관하게 6분 이내로 완료되므로, 한 번 weight를 계산하면 다양한 크기의 서브셋을 즉시 만들 수 있다.
Conclusion
DSIR은 데이터 선택 문제를 importance resampling이라는 통계적 프레임워크로 형식화하고, hashed n-gram이라는 극도로 단순한 feature 공간에서 이를 효율적으로 구현했다. 전문가 큐레이션과 비슷하거나 더 좋은 성능을 GPU 없이 수 시간 만에 달성한다는 점에서 실용적 가치가 크다.
다만 hashed n-gram은 표면적 어휘 분포만 포착하므로, 깊은 의미나 구조적 품질을 반영하지 못한다는 한계가 있다. 이후 연구인 QuRating은 LLM 기반 품질 판단을, DsDm은 학습 알고리즘 인식(model-aware) 접근을 통해 이 한계를 각각 다른 방향에서 극복하려 시도한다.
참고 문헌
Enjoy Reading This Article?
Here are some more articles you might like to read next: