QuRating: Selecting High-Quality Data for Training Language Models
QuRating: Selecting High-Quality Data for Training Language Models
Introduction
“좋은 학습 데이터”란 무엇인가? 기존 데이터 선택 방법들은 대부분 표면적 특성(perplexity, 도메인 유사도)에 의존해왔다. DSIR은 n-gram 분포 매칭을 사용했고, GPT-3는 Wikipedia와의 유사도로 필터링했다. 하지만 이런 접근은 “어떤 텍스트가 질적으로 더 좋은가?”라는 본질적 질문에 답하지 못한다.
QuRating은 데이터 품질을 4가지 기준으로 명시적으로 정의하고, GPT-3.5의 pairwise 비교를 통해 스칼라 품질 점수를 산출한다. 이 점수를 기반으로 260B 토큰의 SlimPajama 전체에 품질 어노테이션을 부여하고, 품질 기반 데이터 선택으로 학습 효율을 크게 향상시킨다.
핵심 결과: Educational value 기준으로 30B 토큰을 선택하면, 45B 토큰 균일 샘플링과 동등한 성능을 달성한다. 즉, 1.5배의 데이터 효율을 얻는다.
Method
4가지 품질 기준
QuRating은 텍스트 품질을 다음 4가지 차원으로 정의한다:
| 기준 | 프롬프트 | 직관 |
|---|---|---|
| Writing Style | “has a more polished and beautiful writing style” | 문체의 세련됨, 문학/학술적 표현 |
| Facts & Trivia | “contains more facts and trivia” | 구체적 사실과 지식 밀도 |
| Educational Value | “has more educational value, e.g., clear explanations, step-by-step reasoning” | 설명의 명확함, 교육적 가치 |
| Required Expertise | “requires greater expertise and prerequisite knowledge” | 이해에 필요한 전문성 수준 |
각 기준은 서로 다른 측면을 포착한다. 예를 들어 ArXiv 논문은 Required Expertise가 높지만 Educational Value는 낮을 수 있고, Wikipedia 문서는 Writing Style과 Educational Value 모두 높을 수 있다.
Pairwise 비교로 품질 판단 수집
왜 직접 점수를 매기지 않고 pairwise 비교를 사용할까? 저자는 실험적으로 pairwise 비교가 직접 점수 매기기보다 23% 더 높은 랭킹 상관도(Kendall tau 0.79 vs 0.61)를 보인다는 것을 확인했다. 두 텍스트를 나란히 놓고 비교하는 것이 절대적 점수를 매기는 것보다 LLM에게 더 쉬운 과제인 것이다.
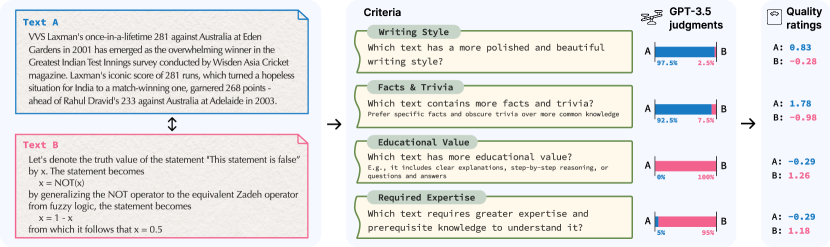
구체적 과정:
- 각 기준에 대해 25만 쌍의 텍스트를 GPT-3.5-turbo에게 비교시킨다
- 위치 편향(positional bias)을 줄이기 위해 양 방향 \((t_A, t_B)\)와 \((t_B, t_A)\) 모두 쿼리한다
- 여러 번 생성하여 평균을 내서 신뢰도 \(p_{B \succ A}\)를 산출한다
검증 결과, 인간 판단과의 일치율이 Writing Style 97%, Educational Value 98.2%, Required Expertise 98.5%로 매우 높다.
Bradley-Terry 모델로 스칼라 점수 도출
Pairwise 비교 결과를 스칼라 점수로 변환하기 위해 Bradley-Terry 모델을 사용한다:
\[p(B \succ A) = \sigma(s_B - s_A)\]여기서 \(\sigma\)는 sigmoid 함수이고, \(s\)는 각 텍스트의 품질 점수이다. 두 텍스트의 점수 차이가 클수록 이길 확률이 1에 가까워진다. 이 모델은 원래 체스 레이팅(Elo) 등에서 사용되는 것과 같은 원리이다.
QuRater 모델 학습
25만 쌍의 판단을 GPT-3.5로 수집하는 것은 가능하지만, 260B 토큰 전체에 대해 GPT-3.5를 호출하는 것은 비현실적이다. 그래서 QuRater 모델을 학습한다.
- 베이스 모델: Sheared-LLaMA-1.3B
- 구조: 4개 기준에 대한 개별 linear regression head
- 학습 손실: Binary cross-entropy
학습된 QuRater는 held-out 판단에서 93% 이상의 정확도를 달성한다. 이 모델로 SlimPajama 260B 토큰 전체에 품질 점수를 부여하는 데 514 H100 시간이 소요된다.
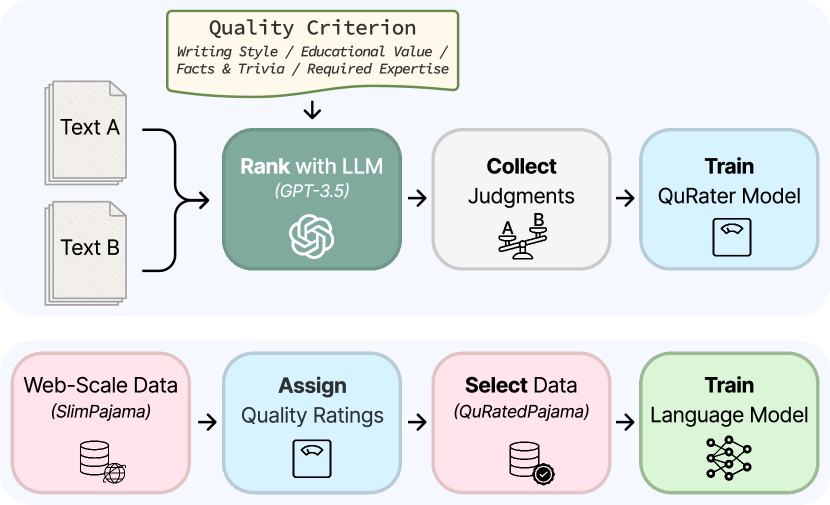
데이터 선택: Temperature Sampling
품질 점수를 기반으로 데이터를 선택할 때, 단순히 top-k를 뽑는 것은 다양성을 크게 훼손한다. 대신 temperature 기반 샘플링을 사용한다:
\[p(d_i) \propto \exp(s_i / \tau)\]- \(\tau \to 0\): top-k 선택 (품질 최대, 다양성 최소)
- \(\tau \to \infty\): 균일 샘플링 (다양성 최대, 품질 무시)
- \(\tau = 2.0\)이 최적: 품질과 다양성의 균형
Experiments
도메인별 품질 분포
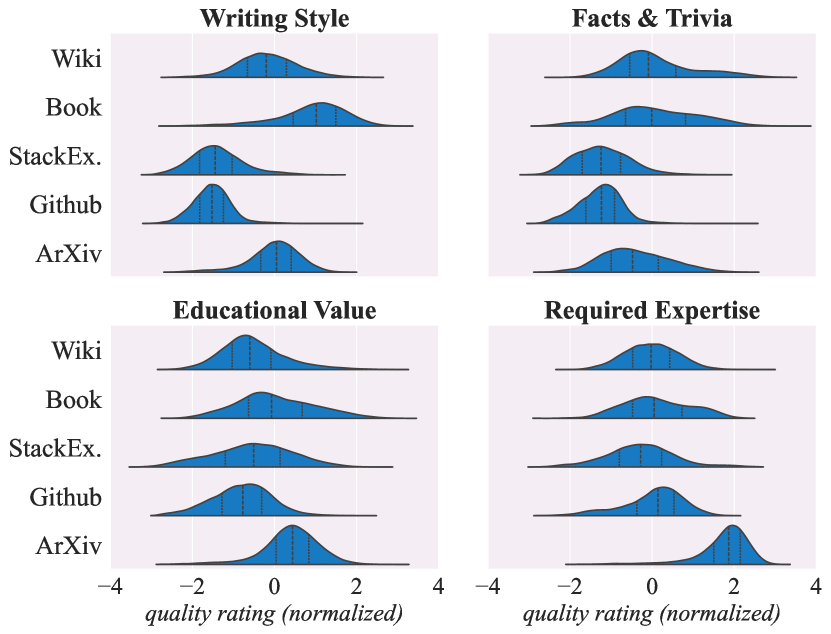
흥미로운 관찰: 모든 도메인 내부에 넓은 품질 범위가 존재한다. Wikipedia도 품질이 낮은 문서가 있고, GitHub 코드 중에도 Educational Value가 높은 문서가 있다. 이는 “도메인 = 품질”이라는 단순한 가정이 틀렸음을 보여준다.
Few-shot In-Context Learning 결과
1.3B 파라미터 모델을 30B 토큰으로 학습한 결과:
| 기준 (τ=2.0) | 평균 ICL 정확도 | vs 균일 샘플링 | 개선 태스크 수 |
|---|---|---|---|
| Educational Value | 46.7% | +1.8% | 10/10 |
| Facts & Trivia | 46.2% | +1.3% | 8/10 |
| Required Expertise | 46.0% | +1.1% | 7/10 |
| Writing Style | 45.6% | +0.7% | 6/10 |
| 균일 샘플링 (baseline) | 44.9% | — | — |
| DSIR (Wikipedia) | < 44.9% | 음수 | — |
| Perplexity 필터링 | < 44.9% | 음수 | — |
핵심 발견:
- Educational Value가 유일하게 모든 10개 태스크에서 개선을 달성했다
- Educational Value로 30B 토큰 선택 = 균일 샘플링 45B 토큰과 동등 (1.5배 데이터 효율)
- DSIR과 perplexity 필터링은 오히려 균일 샘플링보다 나쁜 성능을 보였다
Top-k vs Temperature Sampling
Top-k 선택(\(\tau = 0\))의 성능 저하는 극적이다:
| 기준 | τ=2.0 | top-k (τ=0) | 차이 |
|---|---|---|---|
| Educational Value | 46.7% | 39.1% | -7.6% |
| Facts & Trivia | 46.2% | 41.3% | -4.9% |
| Required Expertise | 46.0% | 42.6% | -3.4% |
Top-k는 “가장 좋은” 문서만 모으지만, 분포가 편향되어 모델이 학습하는 언어의 다양성이 크게 줄어든다. Perplexity도 마찬가지로 top-k에서 11.22까지 급등한다 (baseline 8.96).
Instruction Following 성능
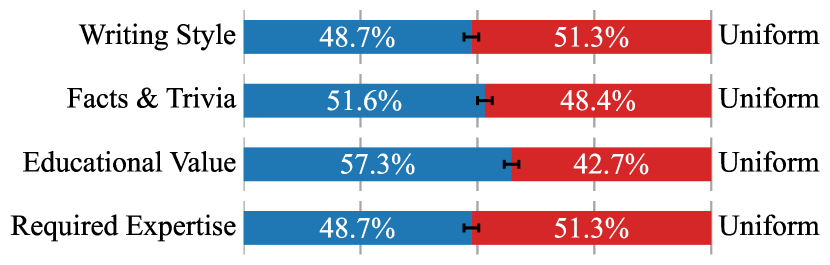
Educational Value로 선택한 모델은 instruction following에서도 균일 샘플링 대비 57.3% win rate를 달성했다. Facts & Trivia는 51.6%로 약간 우세, Writing Style과 Required Expertise는 거의 동등하다.
Perplexity ≠ 성능
흥미로운 결과 중 하나는 낮은 perplexity가 좋은 downstream 성능을 의미하지 않는다는 것이다:
| 기준 | Perplexity | ICL 정확도 |
|---|---|---|
| Writing Style (τ=2.0) | 8.90 (최저) | 45.6% |
| Educational Value (τ=2.0) | 8.91 | 46.7% (최고) |
| 균일 샘플링 | 8.96 | 44.9% |
Writing Style은 perplexity가 가장 낮지만, downstream 성능에서는 Educational Value에 크게 밀린다. 이는 perplexity 기반 데이터 필터링의 한계를 명확히 보여준다.
커리큘럼 학습
품질 점수를 데이터 선택뿐 아니라 학습 순서 결정에도 활용할 수 있다. Required Expertise를 기준으로 쉬운 것에서 어려운 것 순서로 학습하면, 데이터를 바꾸지 않고도 ICL 정확도가 +0.6% 향상된다.
Conclusion
QuRating은 “데이터 품질”을 명시적으로 정의하고 측정하는 프레임워크를 제시했다. 핵심 교훈은 세 가지이다:
- Educational Value가 가장 좋은 품질 지표이다 — 명확한 설명, 단계별 추론을 포함한 텍스트가 모델 학습에 가장 유용하다
- 품질과 다양성의 균형이 필수이다 — top-k 선택은 오히려 성능을 크게 떨어뜨린다
- Perplexity는 좋은 품질 지표가 아니다 — 낮은 perplexity ≠ 좋은 downstream 성능
다만 GPT-3.5의 편향에 의존한다는 한계가 있다. 여성 관련 직업이 Facts & Trivia에서 억제되는 등 사회적 편향도 확인되었고, 1.3B 스케일에서만 검증되어 대규모 모델로의 전이가능성은 불확실하다.
데이터 선택의 다른 접근이 궁금하다면 분포 매칭 기반의 DSIR과 학습 알고리즘 인식 기반의 DsDm도 참고하자.
참고 문헌
Enjoy Reading This Article?
Here are some more articles you might like to read next: