FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Introduction
Transformer의 핵심인 attention은 시퀀스 길이에 대해 \(O(N^2)\)의 연산량을 가지고, LLM과 long-context 애플리케이션에서 가장 큰 병목이다. FlashAttention은 tiling과 kernel fusion으로 HBM IO를 줄여서 이를 해결했고, FlashAttention-2는 non-matmul FLOPs 감소와 warp partitioning 개선으로 한 단계 더 발전했다.
하지만 FlashAttention-2는 H100 GPU에서 이론 성능의 35%밖에 활용하지 못한다. 최적화된 GEMM 커널이 80~90%를 달성하는 것과 비교하면 매우 낮은 수치다. 그 이유는 FlashAttention-2가 동기적(synchronous) 모델을 사용하고, Hopper 아키텍처의 새로운 하드웨어 기능을 활용하지 않기 때문이다.
근본적으로, FlashAttention-2의 알고리즘은 단순화된 동기 모델을 따르며 비동기성과 저정밀도를 명시적으로 활용하지 않는다. 비동기성은 하드웨어 전문화의 결과다. 행렬곱을 수행하는 Tensor Core, 메모리 로드를 담당하는 TMA 등 서로 독립적인 하드웨어 유닛이 존재하기 때문에, 이들을 동시에 활용하려면 소프트웨어도 이에 맞춰 설계해야 한다.
저자는 이 문제를 해결하기 위해 세 가지 기법을 제안한다.
- Producer-Consumer 비동기 처리: Warp specialization으로 데이터 전송과 연산을 분리하고, ping-pong 스케줄링으로 GEMM과 softmax를 겹쳐서 실행한다.
- Intra-warpgroup 파이프라이닝: 하나의 warpgroup 안에서도 WGMMA의 비동기 특성을 이용하여 GEMM과 softmax를 겹친다.
- FP8 저정밀도 + Incoherent Processing: 블록 양자화와 Hadamard 변환으로 FP8의 정확도 손실을 최소화한다.
결과적으로 FlashAttention-3는 H100에서 FP16 기준 740 TFLOPS/s (75% 활용률), FP8 기준 1.2 PFLOPS/s를 달성하며, FlashAttention-2 대비 1.5~2.0배 빠르다.
Background
Multi-Head Attention
Query, Key, Value \(Q, K, V \in \mathbb{R}^{N \times d}\)에 대해 attention output \(O \in \mathbb{R}^{N \times d}\)는 다음과 같이 계산된다.
\[S = \alpha QK^\top \in \mathbb{R}^{N \times N}, \quad P = \text{softmax}(S) \in \mathbb{R}^{N \times N}, \quad O = PV \in \mathbb{R}^{N \times d}\]여기서 \(\alpha = 1/\sqrt{d}\)이고, softmax는 row-wise로 적용된다. 실제로는 수치 안정성을 위해 \(S\)에서 \(\text{rowmax}(S)\)를 빼고 exponential을 취한다.
Multi-head attention(MHA)에서는 각 head가 자기만의 \(Q, K, V\)를 가지며, 여러 head와 batch에 대해 독립적으로 병렬 처리된다.
Backward Pass
손실 함수를 \(\phi\), 그 gradient를 \(d(\cdot) = \partial \phi / \partial (\cdot)\)라고 하자. Output gradient \(dO \in \mathbb{R}^{N \times d}\)가 주어지면 chain rule에 따라 \(dQ, dK, dV\)를 다음과 같이 계산한다.
\[dV = P^\top dO \in \mathbb{R}^{N \times d}\] \[dP = dOV^\top \in \mathbb{R}^{N \times N}\] \[dS = \text{dsoftmax}(dP) \in \mathbb{R}^{N \times N}\] \[dQ = \alpha \cdot dS \cdot K \in \mathbb{R}^{N \times d}\] \[dK = \alpha \cdot dS^\top Q \in \mathbb{R}^{N \times d}\]여기서 \(ds = (\text{diag}(p) - pp^\top)dp\), 즉 \(p = \text{softmax}(s)\)에 대해 row-wise로 적용된다. 이를 \(\text{dsoftmax}(dP)\)라고 쓴다. Forward pass에서 2개의 matmul(\(QK^\top, PV\))이 필요했다면, backward pass에서는 5개의 matmul이 필요하다. 이 때문에 backward의 FLOPs는 forward의 2.5배이다.
GPU 하드웨어 특성과 실행 모델
FlashAttention-3를 이해하려면 Hopper GPU의 메모리 계층과 실행 모델을 알아야 한다.
메모리 계층
H100 SXM5 GPU의 메모리 계층은 다음과 같다.
| 하드웨어 레벨 | 병렬 단위 | 메모리 | 용량 & 대역폭 |
|---|---|---|---|
| Chip | Grid | GMEM (HBM) | 80 GiB @ 3.35 TB/s |
| GPC | Threadblock Cluster | L2 | 50 MiB @ 12 TB/s |
| SM | Threadblock (CTA) | SMEM | 228 KiB per SM, 31TB/s per GPU |
| Thread | Thread | RMEM (Register) | 256 KiB per SM |
아래로 갈수록 빠르고 작다. FlashAttention의 핵심 아이디어는 GMEM(HBM) 접근을 최소화하고 SMEM과 RMEM에서 최대한 연산을 수행하는 것이었다.
쓰레드 계층
GPU의 실행 단위도 계층적이다.
- Thread: 가장 작은 실행 단위
- Warp: 32개 thread 묶음, SIMT(Single Instruction Multiple Thread) 방식으로 동시 실행
- Warpgroup: 4개 warp (128 threads), Hopper에서 새로 도입된 단위. WGMMA의 실행 단위이다.
- Threadblock (CTA): 같은 SM에서 실행되는 warpgroup들의 묶음. SMEM을 공유한다.
- Threadblock Cluster: 같은 GPC에서 실행되는 threadblock 묶음. L2를 공유한다.
- Grid: 전체 커널의 모든 threadblock
비동기 실행과 Warp Specialization
Hopper에는 두 가지 핵심 하드웨어 기능이 있다.
TMA (Tensor Memory Accelerator): HBM과 SMEM 사이의 데이터 전송을 전담하는 하드웨어 유닛이다. 기존에는 warp 내의 모든 thread가 인덱스 계산, 범위 검사, 메모리 복사를 직접 수행해야 했다. TMA는 이 모든 것을 하드웨어가 자동으로 처리한다. 덕분에 warp은 데이터 전송에서 완전히 해방되어 연산에만 집중할 수 있다.
WGMMA (Warpgroup Matrix Multiply-Accumulate): 기존 Ampere의 mma.sync를 대체하는 명령어다. mma.sync는 이름 그대로 동기적이어서, 명령을 발행하면 결과가 나올 때까지 해당 warp이 대기해야 했다. 반면 WGMMA는 비동기적이다. WGMMA 명령을 발행한 후 결과를 기다리지 않고 다른 연산(softmax의 exp, max 등)을 수행할 수 있다. 또한 WGMMA는 SMEM에서 직접 operand를 읽을 수 있어서, 레지스터로 복사하는 단계를 생략할 수 있다.
이 두 기능 덕분에 Hopper에서는 warp을 역할별로 나눌 수 있다.
- Producer warp: TMA로 HBM → SMEM 데이터 로드만 담당. 레지스터를 거의 사용하지 않으므로
setmaxnreg로 레지스터를 반환한다. - Consumer warp: WGMMA로 행렬 연산만 담당. Producer가 반환한 레지스터를 가져와 더 큰 타일로 연산할 수 있다.
이 구조를 warp specialization이라고 하며, 데이터 전송과 연산이 동시에 일어나게 된다. Producer가 다음 블록의 \(K, V\)를 로드하는 동안 consumer는 현재 블록으로 행렬곱을 수행한다.
저정밀도 연산
Hopper의 WGMMA는 FP8(e4m3)을 지원한다. FP8 Tensor Core의 처리량은 FP16 대비 2배이다 (989 TFLOPS → 약 1978 TFLOPS). 하지만 FP8은 mantissa 3bit, exponent 4bit으로 정밀도가 낮아서 단순히 적용하면 정확도가 크게 떨어진다.

또한 FP8 WGMMA에는 레이아웃 제약이 있다. FP16 WGMMA는 mn-major와 k-major 입력 모두 지원하지만, FP8 WGMMA는 k-major만 지원한다. 이 제약은 attention처럼 연속된 두 GEMM(\(S = QK^\top\), \(O = PV\))을 수행할 때 FP32 accumulator와 FP8 operand의 레이아웃이 충돌하는 문제를 야기한다.
Standard Attention과 FlashAttention 복습
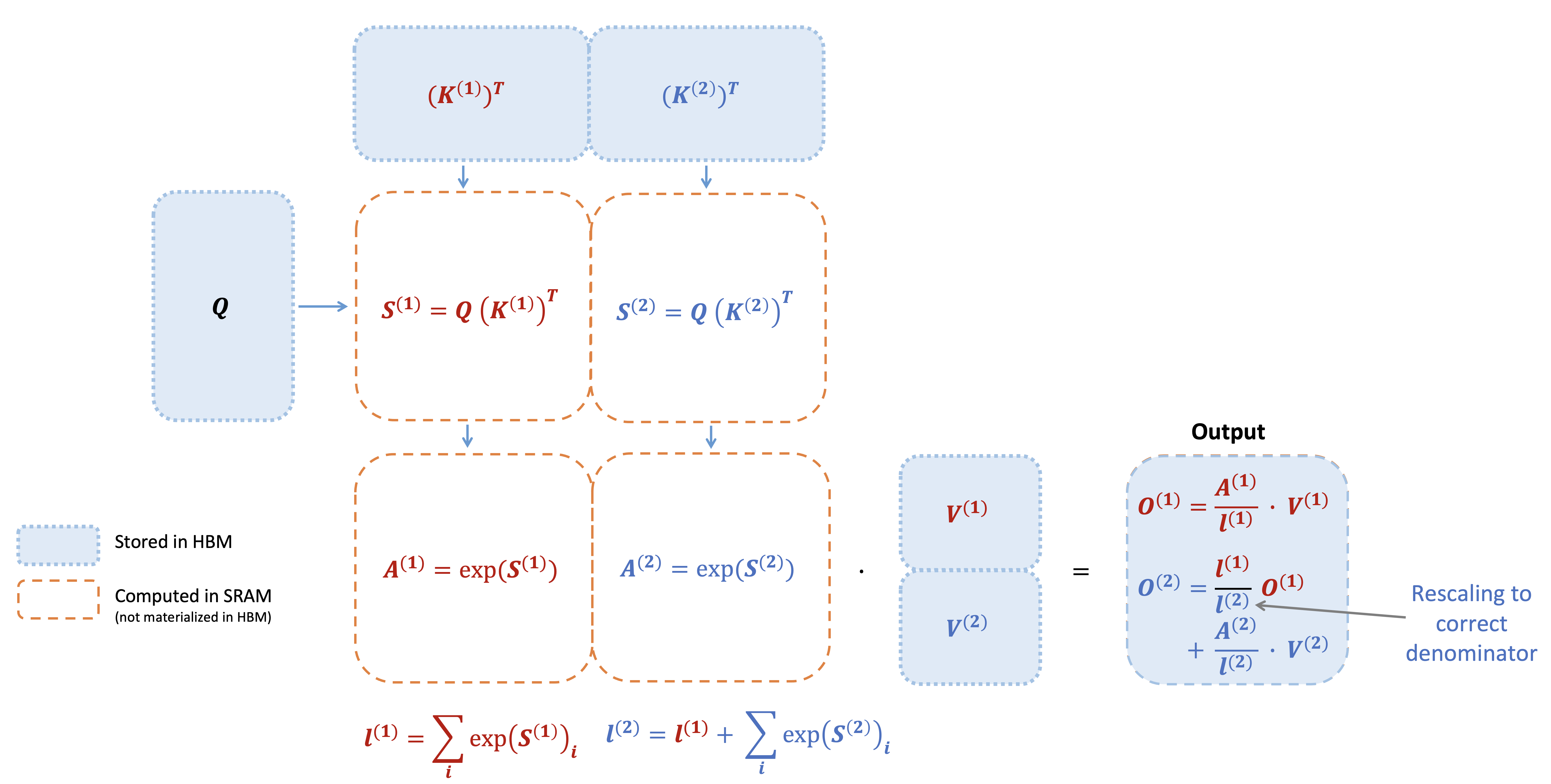
Standard attention은 중간 행렬 \(S\)와 \(P\)를 HBM에 저장한다. 이로 인해 \(O(N^2)\)의 메모리가 필요하고, HBM 읽기/쓰기가 병목이 된다.
FlashAttention의 핵심은 \(S\)와 \(P\)를 HBM에 쓰지 않는 것이다. Tiling을 통해 \(Q, K, V\)를 블록 단위로 SMEM에 올리고, on-chip에서 local softmax를 계산한 뒤 결과를 점진적으로 누적한다. 이때 online softmax 알고리즘을 사용하여 전체 row를 보지 않고도 softmax를 정확히 계산한다. Backward에서는 \((m, l)\) 통계량만 저장해두고 \(S, P\)를 recomputation한다.
FlashAttention-3도 이 기본 구조는 동일하다. 차이점은 어떻게 실행하느냐에 있다.
FlashAttention-3: Algorithm
기본 구조: Warp Specialization 적용
FlashAttention-3의 forward pass는 batch, head, query sequence length에 대해 embarrassingly parallel하다. 각 CTA는 query의 한 타일 \(Q_i \in \mathbb{R}^{B_r \times d}\)를 담당하여 output 타일 \(O_i\)를 계산한다. \(Q\)를 \(T_r = \lceil N/B_r \rceil\)개의 블록으로, \(K, V\)를 \(T_c = \lceil N/B_c \rceil\)개의 블록으로 나눈다.
Producer warp과 consumer warp이 \(s\)-stage circular SMEM buffer를 통해 협력한다. 이 버퍼는 \(K, V\) 블록을 \(s\)개까지 미리 로드해둘 수 있는 원형 큐이다.
Algorithm 1: Forward Pass (Warp Specialization, without intra-consumer overlapping)
Producer warpgroup:
-
setmaxnreg로 레지스터를 반환한다 (producer는 레지스터가 거의 필요 없다). - \(Q_i\)를 HBM에서 SMEM으로 로드하고, consumer에게 알린다.
- \(j = 0, \ldots, T_c - 1\)에 대해:
- 버퍼의 \((j \bmod s)\)번째 스테이지가 소비될 때까지 대기한다.
- \(K_j, V_j\)를 HBM에서 SMEM의 해당 스테이지에 로드한다.
- 로드 완료를 consumer에게 알린다.
TMA 덕분에 로드 명령은 비동기적이며, 처음 \(s\)번의 이터레이션까지는 대기 없이 연속으로 발행할 수 있다.
Consumer warpgroup:
-
setmaxnreg로 추가 레지스터를 확보한다. - On-chip에서 초기화: \(O_i = 0 \in \mathbb{R}^{B_r \times d}\), \(l_i = 0 \in \mathbb{R}^{B_r}\), \(m_i = -\infty \in \mathbb{R}^{B_r}\)
- \(Q_i\)가 SMEM에 로드되기를 기다린다.
- \(j = 0, \ldots, T_c - 1\)에 대해:
- \(K_j\)가 SMEM에 로드되기를 기다린다.
- SS-GEMM: \(S_i^{(j)} = Q_i K_j^\top \in \mathbb{R}^{B_r \times B_c}\). Commit and wait.
- \(m_i^{\text{old}} = m_i\)를 저장한다.
- \[m_i = \max(m_i^{\text{old}}, \text{rowmax}(S_i^{(j)}))\]
- \[\tilde{P}_i^{(j)} = \exp(S_i^{(j)} - m_i) \in \mathbb{R}^{B_r \times B_c}\]
- \[l_i = \exp(m_i^{\text{old}} - m_i) \cdot l_i + \text{rowsum}(\tilde{P}_i^{(j)})\]
- \(V_j\)가 SMEM에 로드되기를 기다린다.
- 이전 결과 보정: \(O_i = \text{diag}(\exp(m_i^{\text{old}} - m_i))^{-1} \cdot O_i\)
- RS-GEMM: \(O_i = O_i + \tilde{P}_i^{(j)} V_j\). Commit and wait.
- 버퍼의 \((j \bmod s)\)번째 스테이지를 producer에게 반환한다.
- 최종 정규화: \(O_i = \text{diag}(l_i)^{-1} O_i\)
- \(L_i = m_i + \log(l_i)\)를 계산한다 (backward용 logsumexp 저장).
- \(O_i\)와 \(L_i\)를 HBM에 기록한다.
여기서 SS-GEMM은 두 operand 모두 SMEM에서 오는 GEMM이고, RS-GEMM은 한쪽이 Register(accumulator)에서 오는 GEMM이다.
이 구조만으로도 FlashAttention-2의 350 TFLOPS에서 540~570 TFLOPS로 성능이 향상된다. Producer가 다음 \(K_{j+1}, V_{j+1}\)을 로드하는 동안 consumer가 현재 \(K_j, V_j\)로 연산하기 때문이다.
Ping-Pong 스케줄링: GEMM과 Softmax 겹치기
여기까지만 해도 빨라졌지만, 아직 해결되지 않은 문제가 있다. Consumer warpgroup 안에서 GEMM과 softmax가 순차적으로 실행된다는 점이다.
왜 이게 문제일까? H100의 처리량을 보자.
| 연산 | 처리량 (FP16) | 비고 |
|---|---|---|
| 행렬곱 (WGMMA) | 989 TFLOPS | Tensor Core |
| 지수함수 (exp 등) | 3.9 TFLOPS | Multi-function Unit |
행렬곱이 지수함수보다 약 256배 빠르다. 그런데 attention forward pass에서 matmul FLOPs와 exponential FLOPs의 비율을 계산해보면, head dimension \(d = 128\) 기준:
- matmul FLOPs: \(4 \times N^2 \times d\) (\(QK^\top\)와 \(PV\), 각각 \(2N^2d\))
- exponential FLOPs: \(\sim N^2\) (softmax의 exp 연산)
- 비율: \(4d = 512\)
matmul이 512배 더 많지만, exponential이 256배 느리니까, softmax가 전체 사이클에서 차지하는 비중은:
\[\frac{1}{1 + 512/256} = \frac{1}{3} \approx 33\%\]즉, 아무리 GEMM을 빠르게 해도 softmax 때문에 전체 시간의 약 1/3은 Tensor Core가 놀게 된다. FP8에서는 더 심각하다. GEMM 처리량이 2배로 늘어나지만 exp 속도는 그대로이므로, softmax 비중이 더 커진다.
해결책은 softmax를 GEMM 뒤에 숨기는 것이다. WGMMA가 Tensor Core에서 실행되고, exp는 Multi-function Unit(SFU)에서 실행되므로, 둘은 서로 다른 하드웨어 유닛이다. 동시에 실행할 수 있다면 softmax의 비용이 사라진다.
저자는 2개의 consumer warpgroup을 사용하는 ping-pong 스케줄링을 제안한다. 동기화 배리어(bar.sync)를 사용하여 다음과 같이 강제한다.
- Warpgroup 1의 GEMM1(\(PV\))과 다음 iteration의 GEMM0(\(QK^\top\))이 먼저 스케줄링된다.
- 이 GEMM들이 Warpgroup 2의 GEMM들 이전에 스케줄링되도록 배리어로 순서를 강제한다.
- 결과적으로 Warpgroup 2가 GEMM을 하는 동안, Warpgroup 1은 softmax를 실행한다.
- 그 다음에는 역할이 뒤바뀐다.
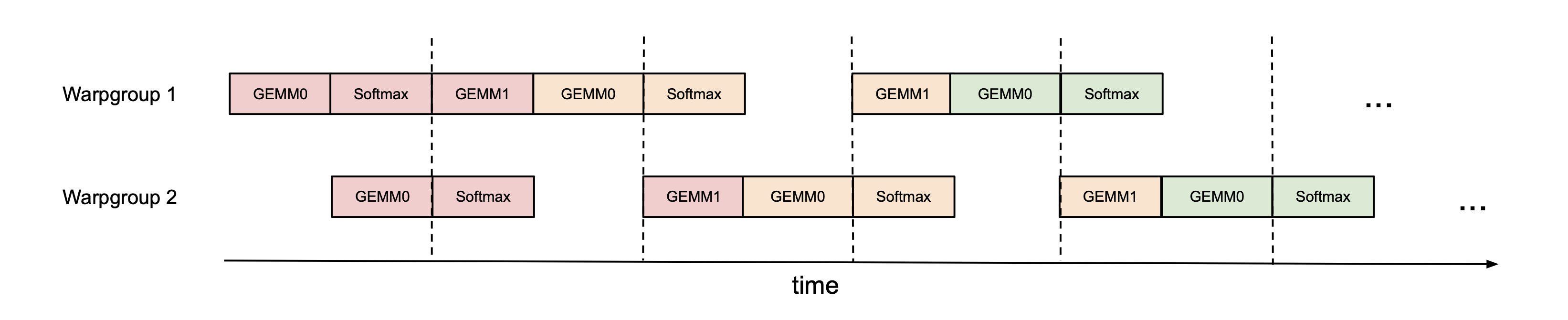
그림에서 같은 색은 같은 iteration을 의미한다. 핵심은 한 warpgroup이 softmax를 하는 시간이 다른 warpgroup의 GEMM 시간에 완전히 가려진다는 것이다.
이 기법으로 570 TFLOPS → 620~640 TFLOPS로 성능이 향상된다 (FP16, hdim=128, seqlen=8192 기준).
Intra-Warpgroup 2-Stage 파이프라이닝
Ping-pong이 warpgroup 사이의 겹침이었다면, 2-stage 파이프라이닝은 하나의 warpgroup 안에서의 겹침이다.
Algorithm 1의 consumer 내부 루프를 보면, 한 iteration 안에서 다음과 같은 의존성이 있다.
- GEMM0 (\(S = QK^\top\)) → 결과 \(S\)가 나와야
- Softmax (\(\tilde{P} = \exp(S - m)\) 등) → 결과 \(\tilde{P}\)가 나와야
- GEMM1 (\(O += \tilde{P}V\)) → 다음 iteration 시작
이 세 단계가 순차적으로 실행되기 때문에, WGMMA가 비동기적이더라도 wait가 필요하다.
하지만 iteration을 넘나들면 겹칠 수 있다. 핵심 관찰은 이것이다.
Iteration \(j\)의 GEMM0 결과(\(S_{\text{next}}\))는 iteration \(j\)의 softmax에만 필요하다. 한편 iteration \(j-1\)의 GEMM1(\(\tilde{P}_{\text{cur}} V_{j-1}\))은 iteration \(j-1\)의 softmax 결과에만 의존한다.
따라서 다음과 같이 겹칠 수 있다.
Algorithm 2: Consumer Warpgroup Forward Pass (2-Stage)
- \(O_i = 0, l_i = 0, m_i = -\infty\) 초기화
- \(Q_i\)와 \(K_0\)가 로드되기를 기다린다.
- \(S_{\text{cur}} = Q_i K_0^\top\) (WGMMA). Commit and wait.
- \(S_{\text{cur}}\)에서 \(m_i, \tilde{P}_{\text{cur}}, l_i\) 계산하고 \(O_i\) rescale.
- \(j = 1, \ldots, T_c - 1\)에 대해:
- \(K_j\)가 로드되기를 기다린다.
- \(S_{\text{next}} = Q_i K_j^\top\) (WGMMA). Commit but do not wait. ← 핵심!
- \(V_{j-1}\)이 로드되기를 기다린다.
- \(O_i = O_i + \tilde{P}_{\text{cur}} V_{j-1}\) (WGMMA). Commit but do not wait.
- \(S_{\text{next}}\)의 WGMMA를 기다린다.
- \(S_{\text{next}}\)에서 \(m_i, \tilde{P}_{\text{next}}, l_i\) 계산하고 \(O_i\) rescale.
- \(\tilde{P}_{\text{cur}} V_{j-1}\)의 WGMMA를 기다린다.
- \(O_i\) rescale 반영.
- \[S_{\text{next}} \to S_{\text{cur}}, \tilde{P}_{\text{next}} \to \tilde{P}_{\text{cur}}\]
- 마지막 \(V_{T_c-1}\) 처리
- 최종 정규화: \(O_i = \text{diag}(l_i)^{-1} O_i\)
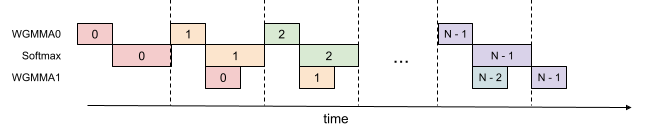
그림에서 같은 색은 같은 iteration을 나타낸다.
- WGMMA0 (\(QK^\top\))이 iteration 1을 계산하는 동안
- Softmax는 iteration 0의 \(S\)를 처리하고
- WGMMA1 (\(\tilde{P}V\))은 iteration 0의 softmax 결과를 사용한다.
5번 단계에서 \(S_{\text{next}}\)와 \(\tilde{P}_{\text{cur}} V_{j-1}\)을 동시에 발행하고 나중에 각각 기다리는 것이 핵심이다. 두 WGMMA가 동시에 실행되는 동안 softmax 연산이 끼어든다.
트레이드오프: 레지스터 압력
이 기법의 대가는 \(S\)를 두 개 동시에 보관해야 한다는 것이다 (\(S_{\text{cur}}\)와 \(S_{\text{next}}\)). 추가 레지스터 사용량은 \(B_r \times B_c \times \text{sizeof(float)}\)이다. 블록 크기를 키우면 memory IO는 줄지만 레지스터 압력이 커져서, GPU마다 최적 블록 크기를 조정해야 한다.
컴파일러 주의사항
이 의사코드는 이상적인 실행 순서를 나타내지만, NVCC 컴파일러가 최적화를 위해 WGMMA 명령의 순서를 재배치할 수 있다. 이 경우 의도한 파이프라이닝이 깨질 수 있으므로, SASS 코드를 확인하여 컴파일러가 올바른 순서를 생성하는지 검증해야 한다.
이 기법으로 620 TFLOPS → 640~661 TFLOPS까지 향상된다.
Backward Pass
Backward pass도 forward와 유사한 warp specialization 구조를 사용한다. 다만 한 가지 추가 역할이 필요하다. Forward에서는 각 CTA가 \(Q_i\)를 담당하여 \(O_i\)를 독립적으로 계산했지만, backward에서는 \(dQ\)의 누적이 필요하다. 여러 CTA가 같은 \(dQ_i\)에 값을 더해야 하므로, 메모리 경합(contention)이 발생한다.
이를 해결하기 위해 dQ-writer warp이라는 세 번째 역할을 추가한다.
- Producer warp: \(K_j, V_j, Q_i, dO_i\) 등을 HBM에서 SMEM으로 로드
- Consumer warp: WGMMA로 \(dV_j, dK_j, dQ_i^{(\text{local})}\) 계산 후 SMEM에 기록
- dQ-writer warp: \(dQ_i^{(\text{local})}\)를 SMEM에서 읽어 HBM의 \(dQ_i\)에 semaphore를 이용하여 원자적으로 누적
이 구조 덕분에 dQ 누적의 메모리 경합이 consumer의 연산을 블로킹하지 않는다.
Low-precision FlashAttention: FP8
FP8 WGMMA의 레이아웃 문제
FP8로 FlashAttention-3를 구현할 때 가장 큰 기술적 난관은 레이아웃 충돌이다.
GEMM에서 행렬 \(A \times B\)를 계산할 때, \(A\)나 \(B\)가 mn-major (outer dimension이 연속)인지 k-major (inner dimension이 연속)인지에 따라 WGMMA 명령이 달라진다. FP16에서는 둘 다 지원하지만, FP8에서는 k-major만 지원한다.
Attention에서는 두 개의 연속된 GEMM이 있다.
- GEMM0: \(S = QK^\top\) → \(S\)는 FP32 accumulator에 저장됨
- GEMM1: \(O = \tilde{P}V\) → \(\tilde{P}\)는 \(S\)에서 softmax를 취한 결과
문제는 FP32 accumulator의 레지스터 레이아웃(아래 그림)이 FP8 operand A의 레이아웃(아래 그림)과 다르다는 것이다.
FP16에서는 이 레이아웃 차이를 mn-major 모드로 우회할 수 있었지만, FP8에서는 k-major만 지원하므로 불가능하다.
저자는 두 가지 방법으로 이를 해결한다.
- V의 in-kernel transpose: LDSM(Load Shared Memory to Register)과 STSM(Store Register to Shared Memory) 명령어를 이용하여 \(V\) 타일을 SMEM에서 읽어 transpose한 후 다시 SMEM에 쓴다. 이 과정은 producer warp에서 실행되며, 다음 \(V\) 타일을 TMA로 로드하는 시간에 숨길 수 있다.
- \(\tilde{P}\)의 byte permute: Accumulator의 레이아웃을 FP8 operand A 형식에 맞추기 위해 byte permute 명령어를 사용한다. 구체적으로
{d0 d1 d4 d5 d2 d3 d6 d7}순서로 재배열한다.
이 두 변환 모두 다른 연산에 숨길 수 있어서 추가 비용이 거의 없다.
Block Quantization
전체 텐서에 하나의 스케일링 값을 사용하는 per-tensor scaling은 이상치 하나가 전체 텐서의 양자화 범위를 지배할 수 있다. 이를 완화하기 위해 블록 단위 양자화를 사용한다.
\(Q, K, V\) 각각을 \(B_r \times d\) 또는 \(B_c \times d\) 크기의 블록으로 나누고, 블록별로 하나의 스케일링 값을 유지한다.
\[s_Q = \frac{\max(|Q_{\text{block}}|)}{448}, \quad Q_{\text{fp8}} = \text{round}\left(\frac{Q_{\text{block}}}{s_Q}\right)\]여기서 448은 FP8 e4m3의 최대 표현값이다.
FlashAttention-3는 이미 블록 단위로 \(Q, K, V\)를 처리하므로, 각 블록의 \(S\)에 대해 \(s_Q \cdot s_K\)를 곱해주면 된다. 이 양자화는 rotary embedding 같은 memory-bound 연산에 fuse할 수 있어서 추가 slowdown이 없다 (rotary embedding 자체가 memory-bandwidth bounded이므로).
Incoherent Processing
블록 양자화만으로는 부족하다. LLM의 활성화값에는 이상치(outlier)가 존재하는데, 전체 원소의 0.1% 정도가 나머지보다 매우 큰 값을 가진다. 이 소수의 큰 값이 블록의 양자화 범위를 지배하면 나머지 99.9%의 값들이 좁은 범위에 몰려서 정밀도가 크게 떨어진다.
저자는 양자화 문헌에서 사용되는 incoherent processing 기법을 도입한다. 아이디어는 양자화 전에 \(Q\)와 \(K\)에 랜덤 직교행렬 \(M\)을 곱해서 이상치를 분산시키는 것이다.
\(M\)이 직교행렬이므로 \(MM^\top = I\)이고:
\[(QM)(KM)^\top = QMM^\top K^\top = QK^\top\]따라서 attention 결과는 전혀 변하지 않지만, \(QM\)의 각 원소는 원래 \(Q\)의 원소들의 가중합이 된다. 이상치의 영향이 여러 원소로 분산되어, 각 원소의 크기가 균등해진다.
왜 분산될까?
직관적으로 이해하면, \(Q\)의 한 행 \(q = [1, 1, 1, 100, 1, \ldots]\)처럼 이상치가 있다고 하자. \(M\)을 곱하면 \(qM\)은 \(q\)의 모든 원소를 섞은 값이 된다. 100이라는 큰 값이 다른 원소들과 합쳐져서 각 원소가 대략 비슷한 크기가 된다.
실제 구현
실제로 \(M\)을 \(N \times N\) 임의의 직교행렬로 사용하면 \(O(d^2)\)의 연산이 필요하다. 대신 \(M = HD\)로 구성한다.
- \(D\): \(\pm 1\)을 원소로 가지는 랜덤 대각행렬 (\(O(d)\))
- \(H\): Hadamard 행렬 (\(O(d \log d)\), Fast Walsh-Hadamard Transform)
\(HD\)의 곱은 \(O(d \log d)\)에 계산 가능하다. 또한 이 변환은 rotary embedding과 같은 memory-bound 연산에 fuse할 수 있어서 사실상 공짜다. Rotary embedding은 어차피 HBM에서 \(Q, K\)를 읽고 써야 하므로 memory-bandwidth bounded인데, Hadamard 변환을 추가해도 메모리 대역폭은 변하지 않기 때문이다.
수치 오차 검증
이상치가 있는 분포에서 수치 오차를 비교한다. \(Q, K, V\)의 원소를 다음과 같이 생성한다.
\[\mathcal{N}(0, 1) + \mathcal{N}(0, 100) \cdot \text{Bernoulli}(0.001)\]즉, 대부분은 표준정규분포이지만 0.1%의 원소에 표준편차 10의 이상치가 추가된다. FP64 구현을 기준(ground truth)으로 RMSE를 측정한 결과:

| 방법 | RMSE |
|---|---|
| Baseline FP16 (standard attention) | 3.2e-4 |
| FlashAttention-2 FP16 | 1.9e-4 |
| FlashAttention-3 FP16 | 1.9e-4 |
| Baseline FP8 (per-tensor scaling) | 2.4e-2 |
| FlashAttention-3 FP8 (block quant + incoherent) | 9.1e-3 |
| FlashAttention-3 FP8 (block quant만, no incoherent) | 9.3e-3 |
| FlashAttention-3 FP8 (no block quant) | 2.4e-2 |
주목할 점:
- FP16에서 FlashAttention-2/3는 standard attention보다 1.7배 더 정확하다. 중간 결과(softmax)를 FP32로 유지하기 때문이다.
- FP8에서 block quantization + incoherent processing을 적용하면 baseline 대비 2.6배 오차가 줄어든다.
- Block quantization만으로도 대부분의 개선이 이루어지고, incoherent processing이 추가적인 개선을 제공한다.
Empirical Validation
H100 80GB SXM5 GPU에서 벤치마크를 수행했다. Hidden dimension은 2048, 시퀀스 길이는 512~16K, head dimension은 64, 128, 256으로, total token 수가 16K가 되도록 batch size를 조절했다. Forward FLOPs는 다음과 같이 계산한다.
\[\text{FLOPs} = 4 \times \text{seqlen}^2 \times \text{head\_dim} \times \text{num\_heads}\]Causal masking이 있으면 약 절반만 계산하므로 2로 나눈다. Backward FLOPs는 forward의 2.5배이다 (forward에 matmul 2개, backward에 5개).
FP16 Forward Pass
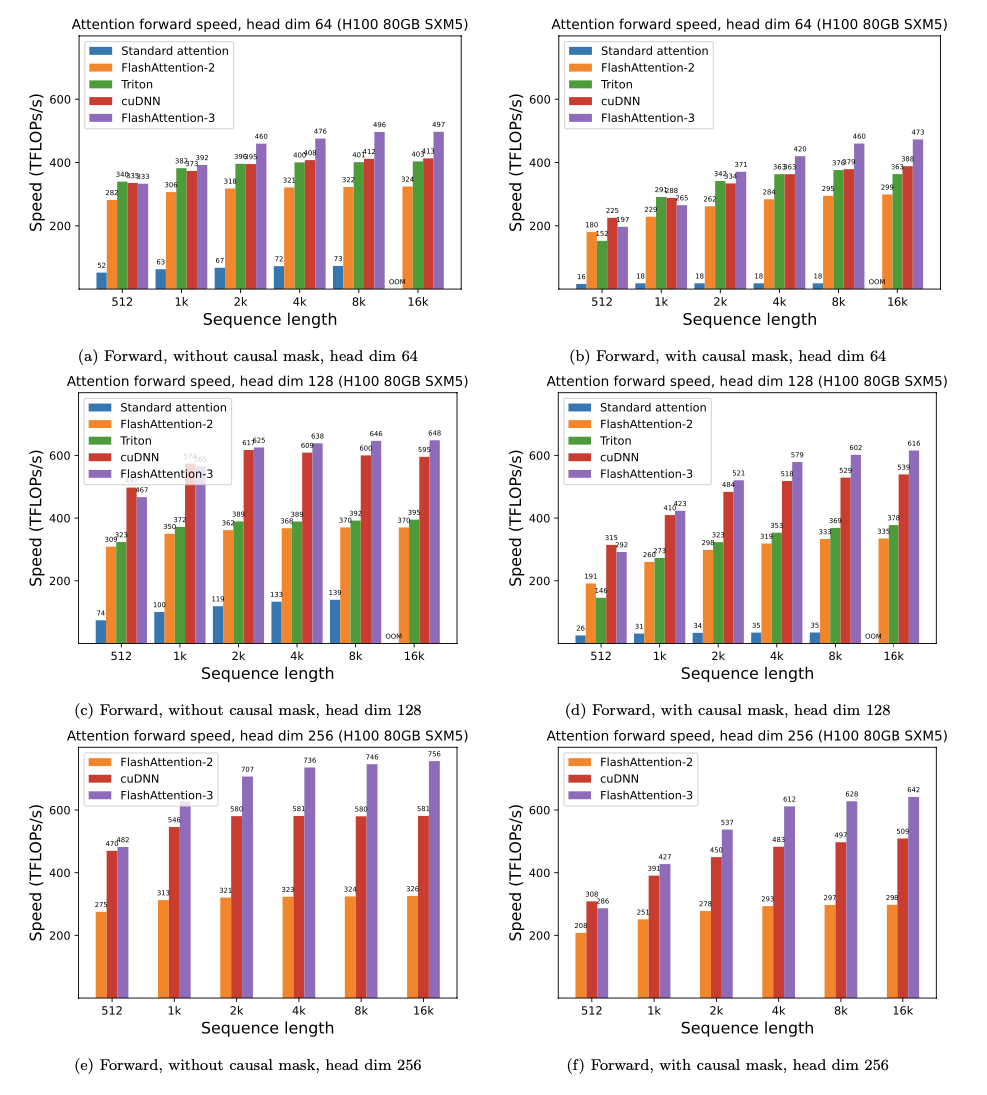
FlashAttention-3는 FlashAttention-2 대비 1.5~2.0배 빠르다.
- Head dim 64: Non-causal, seqlen 16K 기준 — Standard 73, FA-2 332, cuDNN 412, FA-3 497 TFLOPS
- Head dim 128: Non-causal, seqlen 8K 기준 — Standard 133, FA-2 370, cuDNN 610, FA-3 649 TFLOPS
- Head dim 256: Non-causal, seqlen 8K 기준 — FA-2 581, cuDNN 581, FA-3 746 TFLOPS (최대)
- Standard attention 대비 3~16배 빠르다
- cuDNN(NVIDIA 자체 최적화 라이브러리)보다도 대부분의 설정에서 빠르거나 비슷한 성능을 보인다
Head dimension이 클수록 matmul 비중이 커져서 GPU 활용률이 높아진다. Head dim 256에서 최대 756 TFLOPS, 이론 최대 989 TFLOPS의 약 75%에 도달한다.
FP16 Backward Pass
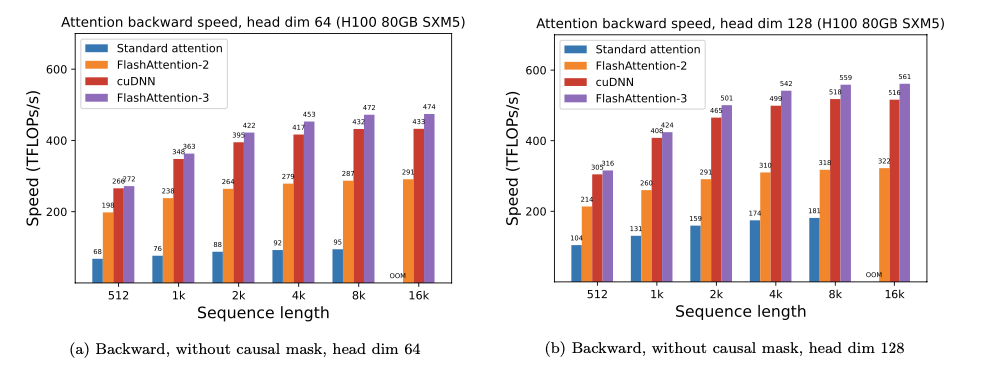
Backward pass에서도 FlashAttention-2 대비 1.5~1.75배 빠르다. Forward보다 speedup이 약간 낮은데, backward에는 5개의 matmul과 더 복잡한 데이터 의존성이 있어서 파이프라이닝 효과가 상대적으로 줄어들기 때문이다.
FP8 Forward Pass
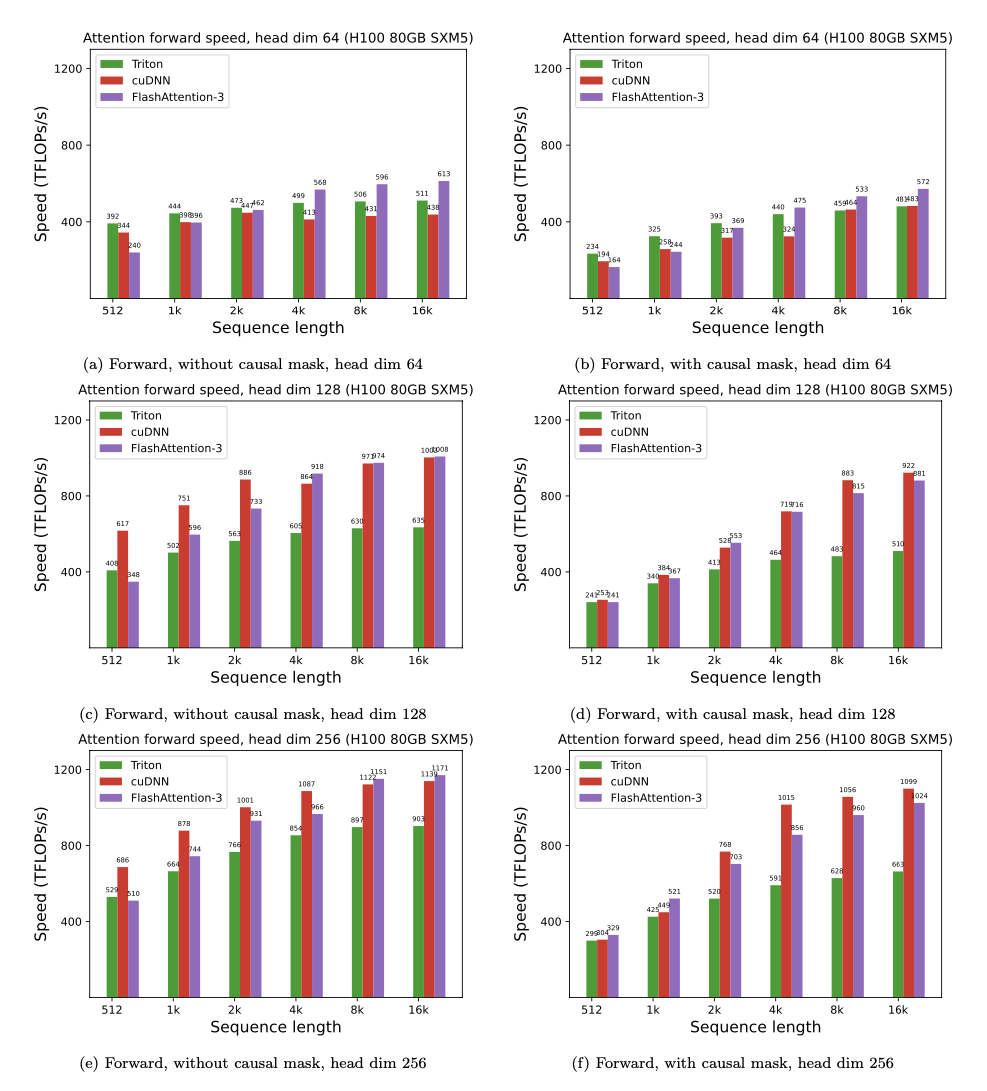
FP8에서는 head dim 256, non-causal, seqlen 16K 기준 최대 1,171 TFLOPS에 달하며, 1.2 PFLOPS/s에 근접한다. FP16 대비 약 1.5~2배의 추가 speedup이다.
다만 짧은 시퀀스와 causal masking 조합에서는 FP8 cuDNN이 더 빠른 경우도 있다. 이는 FP16 FlashAttention-3가 persistent kernel과 load balancing 전략을 사용하는 반면 FP8 버전은 아직 이를 적용하지 않았기 때문이다.
Ablation: 파이프라이닝 효과
Non-causal FlashAttention-3 (FP16, batch=4, seqlen=8448, nheads=16, hdim=128) 기준:
| Configuration | Time | TFLOPs/s |
|---|---|---|
| FlashAttention-3 (full) | 3.538 ms | 661 |
| No GEMM-Softmax pipelining, with warp specialization | 4.021 ms | 582 |
| GEMM-Softmax pipelining, no warp specialization | 4.105 ms | 570 |
Warp specialization만으로 570 → 582 TFLOPS, GEMM-softmax pipelining을 추가하면 582 → 661 TFLOPS로, 각 기법이 단계적으로 성능을 끌어올리는 것을 확인할 수 있다.
FlashAttention 시리즈 비교
| FlashAttention | FlashAttention-2 | FlashAttention-3 | |
|---|---|---|---|
| 핵심 아이디어 | Tiling + Recomputation | non-matmul FLOPs 감소, warp partitioning | 비동기 실행, FP8 |
| 타겟 GPU | A100 | A100 | H100 (Hopper) |
| 주요 명령어 | mma.sync | mma.sync | WGMMA + TMA |
| 정밀도 | FP16 | FP16 | FP16 + FP8 |
| GPU 활용률 | — | 35% (H100 기준) | 75% (H100) |
| FP16 성능 | — | ~370 TFLOPS | ~740 TFLOPS |
| FP8 성능 | — | — | ~1.2 PFLOPS |
| Softmax 처리 | 순차 실행 | 순차 실행 | GEMM과 겹침 |
| Backward 특이점 | — | outer loop을 K, V로 변경 | dQ-writer warp 추가 |
Discussion, Limitations, Conclusion
FlashAttention-3는 Hopper GPU의 하드웨어 특성을 적극적으로 활용하여 attention 성능을 크게 향상시켰다. 특히 WGMMA의 비동기 특성을 이용한 ping-pong 스케줄링과, FP8의 정확도 문제를 해결하는 incoherent processing이 인상적이다.
FlashAttention-2가 “어떤 GPU에서든 작동하는 범용 최적화”였다면, FlashAttention-3는 “Hopper의 능력을 극한까지 끌어내는 하드웨어 특화 최적화”라고 할 수 있다. GPU 아키텍처가 발전할수록 소프트웨어도 이에 맞춰 진화해야 한다는 것을 보여주는 좋은 사례다.
Limitations
저자가 언급한 한계는 다음과 같다.
- Hopper 전용: 현재 구현은 H100에 특화되어 있다. 다만 비동기 실행과 warp specialization이라는 개념 자체는 비슷한 하드웨어 특성을 가진 다른 GPU에도 적용 가능하다.
- FP8 커널 설계의 복잡성: Persistent kernel과 FP8을 통합하는 것이 아직 남은 과제이다.
- FP8 학습의 불확실성: 추론에서 FP8의 효과는 검증되었지만, 학습에서 저정밀도가 안정적인지는 추가 연구가 필요하다.
Related Work
FlashAttention-3와 관련된 연구 방향들도 간략히 정리한다.
- Distributed attention: Ring Attention 등은 FlashAttention을 여러 GPU로 확장하여 최대 100만 토큰까지 처리할 수 있다. FlashAttention-3의 개선은 이런 분산 attention 방법에도 그대로 적용된다.
- Alternative architectures: Mamba, RWKV, RetNet 등 linear attention 계열 모델이 등장하고 있지만, 대형 모델(Jamba, Zamba 등)에서도 여전히 attention layer를 포함하고 있어 FlashAttention의 최적화가 유효하다.
- KV cache quantization: QuIP, KIVI 등은 KV cache를 4bit, 2bit까지 양자화하여 추론 효율을 높인다. FlashAttention-3의 incoherent processing 기법은 이런 양자화 연구에서 영감을 받았다.
FlashAttention의 원리가 궁금하다면 FlashAttention 논문 리뷰를, 개선점이 궁금하다면 FlashAttention-2 논문 리뷰를, Triton으로 직접 구현하고 싶다면 Triton 05: Flash Attention을 참고하자.
Enjoy Reading This Article?
Here are some more articles you might like to read next: