FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
Introduction
FlashAttention-3는 Hopper GPU(H100)의 비동기 실행과 FP8을 활용하여 GPU 이론 성능의 75%를 달성했다. 하지만 FA3는 H100에 특화되어 있으며, AI 산업은 이미 Blackwell 기반 시스템(B200, GB200)으로 빠르게 전환하고 있다.
문제는 Blackwell이 Hopper와 근본적으로 다른 성능 특성을 가진다는 점이다. Tensor Core 처리량은 2배로 증가했지만, shared memory 대역폭과 지수함수(exponential) 유닛은 거의 그대로이다. 이런 비대칭적 스케일링(asymmetric scaling) 때문에, FA3의 알고리즘을 Blackwell에 그대로 이식하면 성능이 크게 제한된다.
저자는 이 비대칭 하드웨어 스케일링을 정면으로 다루는 FlashAttention-4를 제안한다. 핵심 기법은 다음과 같다.
- 파이프라인 재설계: Blackwell의 완전 비동기 MMA와 더 큰 타일 크기를 활용하는 새로운 소프트웨어 파이프라인
- 지수함수 병목 완화: 다항식 근사를 통한 소프트웨어 에뮬레이션 + 불필요한 softmax rescaling을 건너뛰는 조건부 rescaling
- Shared memory 트래픽 감소: Tensor Memory 활용과 backward pass에서의 2-CTA MMA 모드
FlashAttention-4는 B200 GPU에서 BF16 기준 cuDNN 9.13 대비 1.3배, Triton 대비 2.7배 빠르며, 최대 1613 TFLOPS/s (71% utilization)를 달성한다.
또한 FA4는 CuTe-DSL(Python 기반)로 전체 구현하여, 기존 C++ 템플릿 대비 컴파일 시간을 20-30배 단축했다.
Background: Blackwell GPU의 비대칭 스케일링
Hopper vs Blackwell 하드웨어 비교
| 하드웨어 | Hopper (H100) | Blackwell (B200) | 스케일링 |
|---|---|---|---|
| Tensor Core (BF16) | 1 PFLOPS | 2.25 PFLOPS | 2.25× |
| MMA 타일 크기 | 64 × N | 128 × N (또는 256) | 2× |
| MUFU (exp 등) | 16 ops/clock/SM | 16 ops/clock/SM | 1× (동일!) |
| SMEM 대역폭 | 128 bytes/clock | 128 bytes/clock | 1× (동일!) |
| Tensor Memory | 없음 | 256 KB/SM | 신규 |
| MMA 비동기성 | register writeback 필요 | TMEM에 직접 쓰기 | 더 높은 비동기성 |
핵심 관찰: Tensor Core가 2배 이상 빨라졌지만, exp를 계산하는 MUFU와 SMEM 대역폭은 그대로이다. FA3에서는 ping-pong 스케줄링으로 softmax를 GEMM 뒤에 숨길 수 있었는데, Blackwell에서는 GEMM이 2배 빨라져서 softmax를 숨길 시간이 부족하다.
Roofline 분석: Forward Pass
타일 크기 \(M \times N\)과 head dimension \(d\)에 대해, forward pass의 각 리소스별 소요 사이클:
\[T_{\text{MMA}} = \frac{4MNd}{8192} \text{ cycles}\] \[T_{\text{smem}} = \frac{3MNd}{8192} \text{ cycles (대략적)}\] \[T_{\text{exp}} = \frac{MN}{16} \text{ cycles}\]| Resource | \(128^3\) | \(256 \times 128^2\) |
|---|---|---|
| MMA compute | 1024 | 2048 |
| Shared memory | 768 | 1536 |
| Exponential unit | 1024 | 2048 |
MMA와 exponential이 동시에 병목이다. 즉, exp를 다른 하드웨어에서 실행하지 않으면 Tensor Core가 아무리 빨라도 성능이 제한된다.
이 분석에서 FA4의 설계 원칙이 도출된다.
- 큰 타일 크기를 사용하여 MMA와 softmax의 overlap을 극대화
- exp의 처리량을 높이기 위해 FMA 유닛으로 소프트웨어 에뮬레이션
- 불필요한 non-matmul 연산을 줄이기 — 조건부 rescaling
Forward Pass: 파이프라인 재설계
FA3 vs FA4 파이프라인 비교
FA3는 2개 warpgroup의 ping-pong 스케줄링을 사용했다. FA4는 이를 확장하여 역할별 전문화된 warp 그룹을 사용한다.
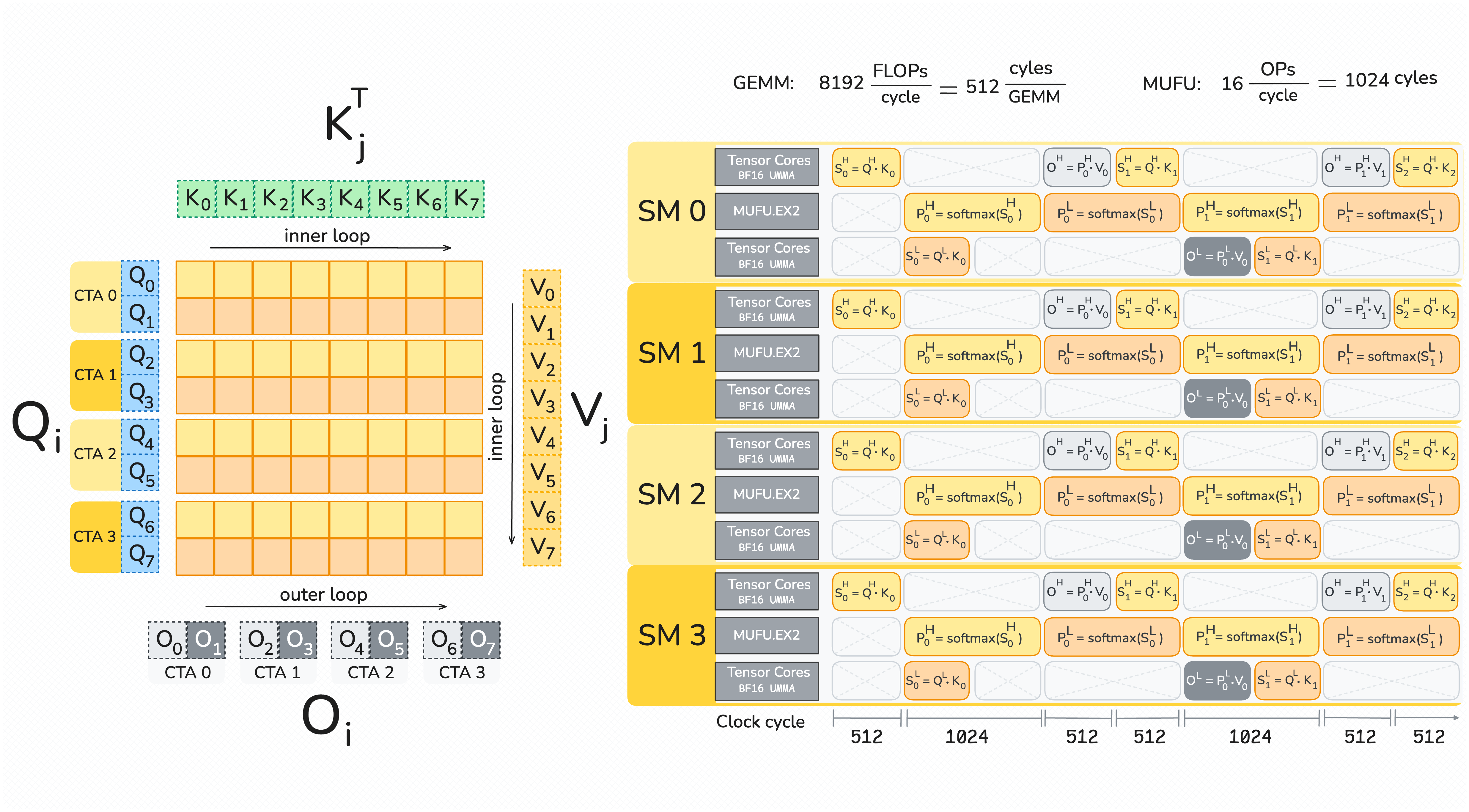
Blackwell에서의 핵심 변화
1. Accumulator가 Tensor Memory에 저장
Hopper에서는 MMA의 accumulator가 register에 저장되어, softmax warpgroup이 register에서 값을 읽어야 했다. Blackwell에서는 MMA가 Tensor Memory(TMEM)에 직접 accumulator를 쓴다. 이 덕분에:
- Softmax warpgroup이 TMEM에서 직접 값을 읽을 수 있다
- Rescaling을 별도의 correction warpgroup으로 분리 가능 — critical path에서 제거
2. 타일 크기 128 × 128
Hopper의 64 × 128 대비 2배 큰 타일. 한 번의 MMA에 더 많은 연산을 수행하므로, MMA와 softmax의 overlap 기회가 늘어난다.
3. Warp 역할 분배
각 thread당 하나의 행(row)을 담당하여 128개 원소를 register에 로드한다. 구체적으로:
| 역할 | 수량 | 기능 |
|---|---|---|
| MMA warpgroup | 1 | Tensor Core 연산 (\(QK^\top\), \(PV\)) |
| Softmax warpgroup | 2 | max, exp, rowsum 계산 |
| Correction warpgroup | 1 | Rescaling (\(e^{m_{\text{old}} - m_{\text{new}}}\)로 보정) |
| TMA (producer) | - | HBM → SMEM 데이터 로드 |
Softmax warpgroup과 correction warpgroup을 분리한 것이 FA3와의 핵심 차이다. Correction은 critical path 밖에서 실행된다.
지수함수 소프트웨어 에뮬레이션
문제: MUFU 병목
Blackwell에서 MUFU(Multi-Function Unit)는 clock당 SM당 16개 연산만 처리한다. Tensor Core가 clock당 8192 FLOPs를 처리하는 것과 비교하면 512배 느리다. Head dimension 128 기준으로 forward에서 matmul FLOPs는 exp 연산 대비 512배 많지만, MUFU가 512배 느리므로 exp가 matmul과 동일한 시간을 소비한다.
해결: 다항식 근사
FMA(Fused Multiply-Add) 유닛은 MUFU와 독립적으로 병렬 실행될 수 있다. 저자는 지수함수를 FMA 기반 다항식으로 근사한다.
핵심 분해:
\[2^x = 2^{\lfloor x \rfloor} \cdot 2^{x_{\text{frac}}}\]여기서 \(x_{\text{frac}} = x - \lfloor x \rfloor \in [0, 1)\)이다.
- 정수 부분 \(2^{\lfloor x \rfloor}\): IEEE 754 부동소수점의 exponent 필드를 직접 조작 (integer ALU 명령어)
- 소수 부분 \(2^{x_{\text{frac}}}\): 다항식 근사
Degree 3 다항식의 경우 3번의 FMA 명령어로 계산 가능하며, BF16 정밀도에서 하드웨어 MUFU와 거의 구분 불가능한 오차를 보인다.
| Method | FP32 Max Rel Err | BF16 Max Rel Err |
|---|---|---|
| Hardware MUFU.EX2 | \(1.41 \times 10^{-7}\) | \(3.89 \times 10^{-3}\) |
| Degree 3 polynomial | \(8.77 \times 10^{-5}\) | \(3.90 \times 10^{-3}\) |
| Degree 5 polynomial | \(1.44 \times 10^{-7}\) | \(3.89 \times 10^{-3}\) |
FP32 수준에서는 degree 3가 MUFU보다 약 600배 부정확하지만, BF16으로 반올림하면 양자화 오차가 지배적이어서 차이가 사라진다. Degree 3 이상에서 BF16 오차는 모두 \(\sim 3.9 \times 10^{-3}\)으로 동일하다.
Partial Emulation
모든 exp를 다항식으로 대체하면 register 압력이 증가하고 대역폭이 늘어난다. 따라서 softmax row의 일부(10-25%)에만 선택적으로 적용한다. 나머지는 하드웨어 MUFU를 사용한다. 적용 비율은 MMA와 exp의 처리량 비율에 따라 경험적으로 튜닝한다.
조건부 Softmax Rescaling
기존 방식의 비효율
FlashAttention의 online softmax에서, 새로운 블록을 처리할 때마다 max가 바뀌면 이전 결과를 보정해야 한다:
\[m_j = \max(m_{j-1}, \text{rowmax}(S_j))\] \[O_j = e^{m_{j-1} - m_j} O_{j-1} + e^{S_j - m_j} V_j\]이 rescaling (\(e^{m_{j-1} - m_j} O_{j-1}\)) 은 매 블록마다 발생한다. 하지만 실제로 max가 크게 변하지 않으면 \(e^{m_{j-1} - m_j} \approx 1\)이 되어 불필요한 연산이다.
FA4의 개선: threshold \(\tau\)
저자는 threshold \(\tau\)를 도입하여, max의 변화가 충분히 클 때만 rescaling한다:
\[O_j = \begin{cases} e^{m_{j-1} - m_j} O_{j-1} + e^{S_j - m_j} V_j & \text{if } m_j - m_{j-1} > \tau \\ O_{j-1} + e^{S_j - m_{j-1}} V_j & \text{otherwise} \end{cases}\]\(\tau\)가 \(m_{j-1}\)와 \(m_j\)의 차이보다 크면, 이전 max(\(m_{j-1}\))를 그대로 사용한다. 마지막에 true max \(m_{\text{final}}\)과 true normalizer \(\ell_{\text{final}}\)로 한 번만 보정한다.
\[\text{Output} = \frac{1}{\ell_{\text{final}}} O_{\text{final}}\]실용적으로 \(\tau = \log_2(256) = 8.0\)으로 설정한다. 이렇게 하면 rescaling 횟수가 약 10배 감소한다.
Backward Pass
Roofline 분석
Backward pass는 5개의 MMA를 수행한다: \(S^\top = KQ^\top\), \(dP^\top = VdO^\top\), \(dV = P^\top dO\), \(dK = dS^\top Q\), \(dQ = dS \cdot K\).
\(M = N = d = 128\) 기준:
| Resource | 1-CTA (\(M=128\)) | 2-CTA (\(M=256\)) |
|---|---|---|
| MMA compute | 2560 | 2560 |
| Total shared memory | 3328 | 2688 |
| Exponential unit | 1024 | 1024 |
Shared memory 트래픽이 MMA compute보다 30% 더 크다. Forward와 달리 backward에서는 shared memory가 주요 병목이다.
2-CTA MMA 모드
Blackwell은 2-CTA tensor core MMA 모드를 지원한다. 같은 thread block cluster 내의 2개 CTA가 협력하여 하나의 큰 MMA를 실행한다. \(M = 256\), \(N = K = 128\) 크기의 타일을 사용하면:
- 각 CTA는 operand B의 절반만 shared memory에 로드
- 나머지 절반은 peer CTA의 shared memory에서 읽음
- → Shared memory 트래픽 약 절반으로 감소
또한 \(dQ\)의 accumulation에서 atomic add가 필요한데, 2-CTA 모드에서는 각 CTA가 \(dQ\) 타일의 절반만 쓰므로 global atomic reduction 횟수도 절반이 된다.
Backward Computation Graph
FA4의 backward pass는 Prologue → Main Loop → Tail의 3단계로 구성된다. 5개 MMA + 2개 elementwise 연산이 파이프라인으로 실행된다. FA3 대비 핵심 개선:
- TMEM에 accumulator를 저장하여 MMA와 softmax gradient 계산을 overlap
- \(dQ\)와 \(dK\)의 MMA를 이전 iteration의 softmax 계산과 병렬 실행
- 2-CTA 모드로 shared memory 병목 완화
Deterministic Backward Pass
GPU의 atomic reduction은 비결정적(nondeterministic)이다. 강화학습 등 재현 가능한 학습이 필요한 경우를 위해, deterministic mode도 제공한다. Semaphore lock으로 \(dQ\) reduction 순서를 고정하며, CTA swizzling으로 stall을 최소화한다. Nondeterministic 대비 약 75%의 속도를 달성한다.
Scheduling: LPT와 Causal Masking
Longest-Processing-Time First (LPT)
Causal masking이나 variable sequence length 상황에서 SM 간 load imbalance가 발생한다. FA4는 LPT 스케줄링을 도입한다.
- SM들을 L2 cache를 공유하는 section으로 나누고
- 각 section 내에서 worktile을 실행 시간이 긴 순서대로 배치
- Causal masking에서는 대각선 근처의 긴 worktile을 먼저 처리
이 스케줄링은 Hopper에서도 적용 가능하며, BF16 hdim 128 기준 MHA에서 4-8% FLOPS 향상, MQA 8에서 7-14% 향상을 보인다.
Language: CuTe-DSL
FA4는 CUDA C++이 아닌 CuTe-DSL(Python 기반)로 전체 구현했다. CuTe-DSL은 CUTLASS의 일부로, Python 코드를 PTX → SASS로 컴파일한다.
| FA3 (C++) | FA4 (CuTe-DSL) | |
|---|---|---|
| Forward 컴파일 | 55s | 2.5s |
| Backward 컴파일 | 45s | 1.4s |
| Speedup | — | 22-32× |
C++ 템플릿 메타프로그래밍의 복잡한 컴파일 과정 없이, Python의 JIT 컴파일을 활용하여 빠른 iteration이 가능하다. FA2, FA3는 수백 개의 커널을 미리 컴파일해야 했지만, FA4는 필요할 때 JIT로 컴파일한다.
이 접근의 장점:
- 개발 생산성: C++ 템플릿 전문 지식 없이도 GPU 커널 개발 가능
- 모듈성: Block-sparse, FlexAttention, variable sequence length 등을 독립적인 primitive로 구현하여 자유롭게 조합
- PTX escape hatch: CuTe-DSL API에 아직 없는 기능은 직접 PTX를 삽입 가능
Empirical Evaluation
B200 GPU에서 BF16 입력으로 벤치마크를 수행했다. Hidden dimension 2048, head dimension 64 또는 128, 시퀀스 길이 1K-32K.
Forward Pass
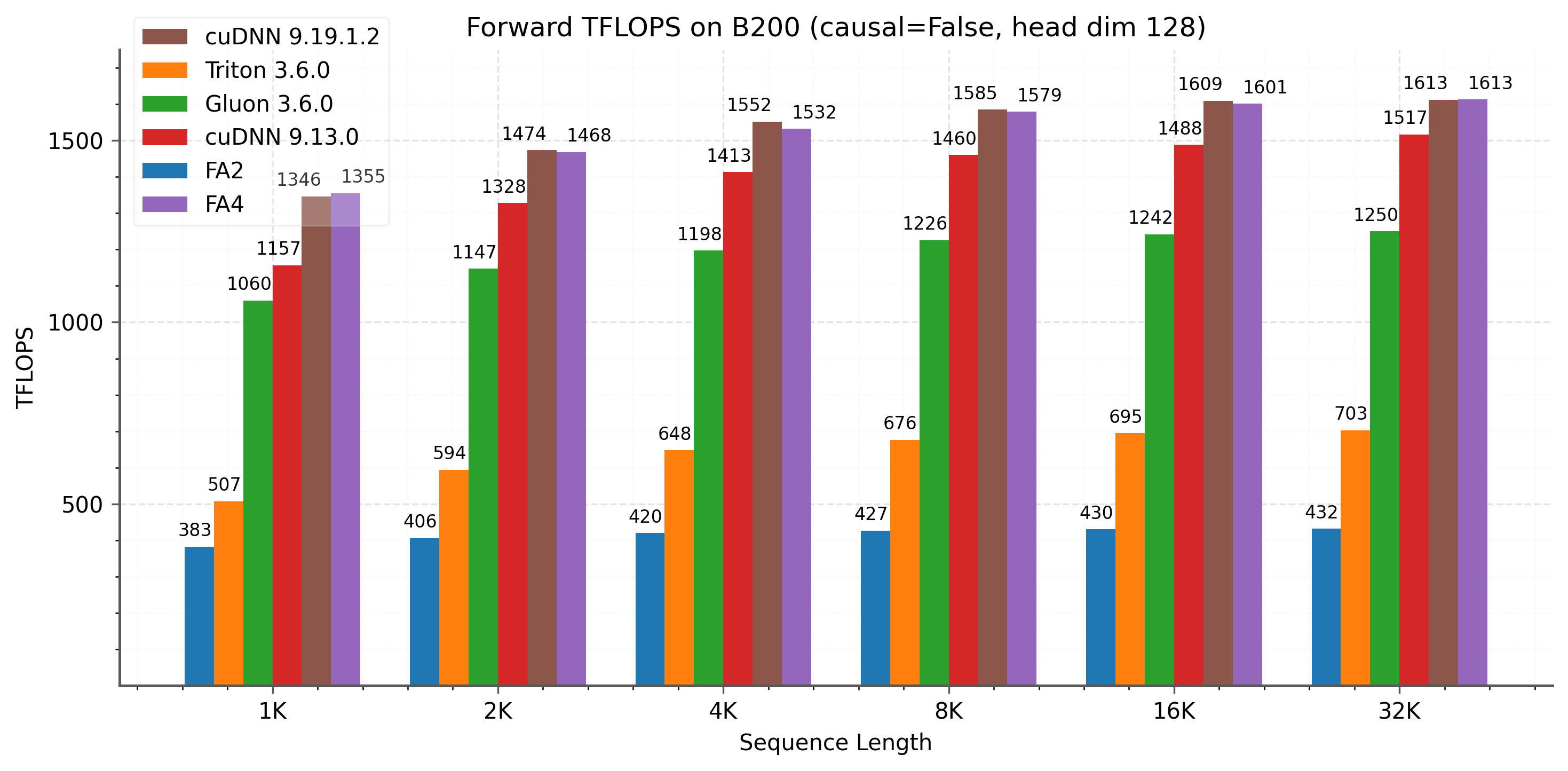
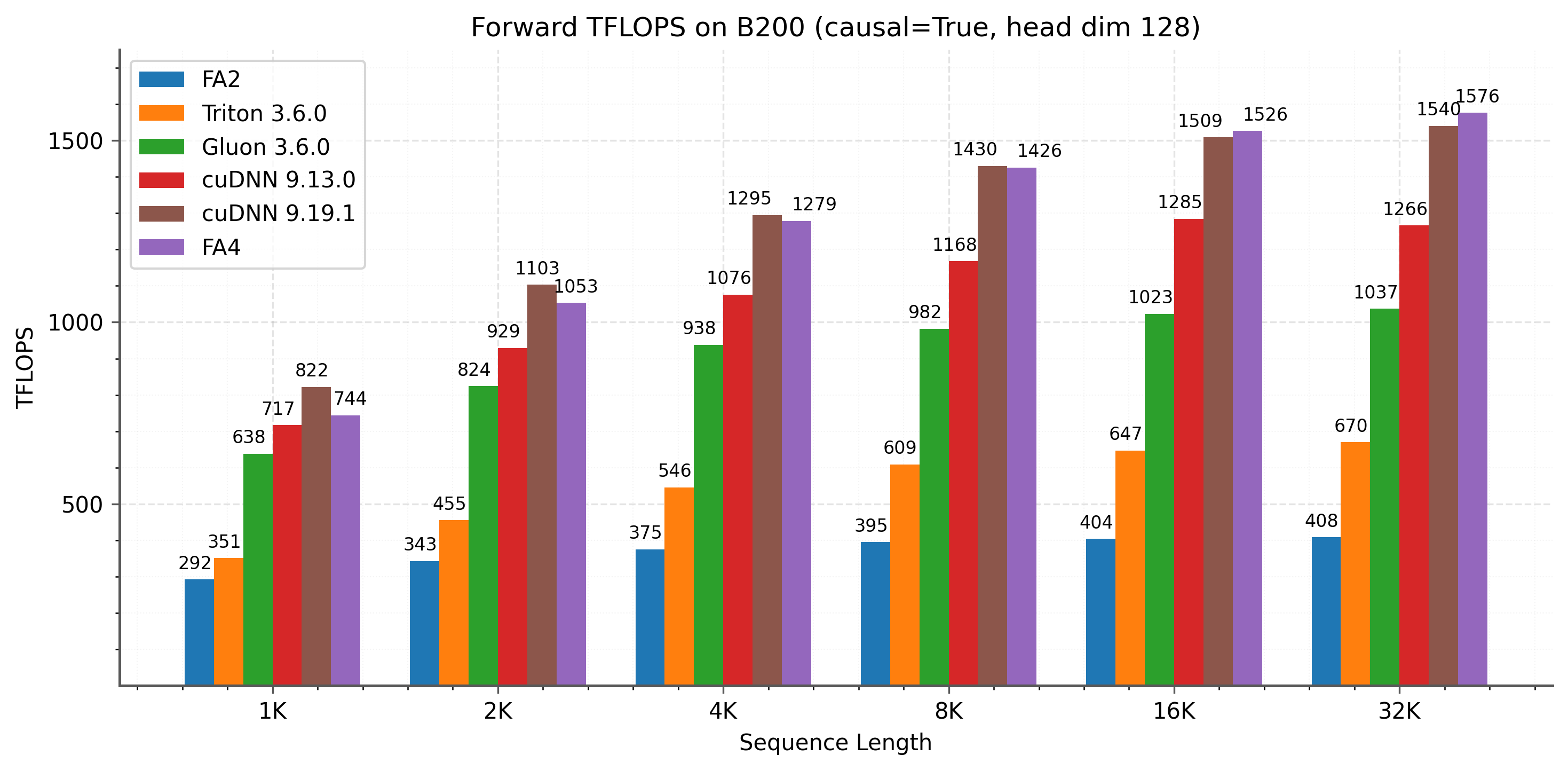
Head dim 128 기준:
- Non-causal: FA4가 cuDNN 9.13.0 대비 1.1-1.3× 빠르고, Triton 대비 2.1-2.7× 빠르다
- Causal: LPT 스케줄링 덕분에 특히 긴 시퀀스에서 이점이 크다
- 최대 1613 TFLOPS/s (이론 최대 2250 TFLOPS의 약 71%)
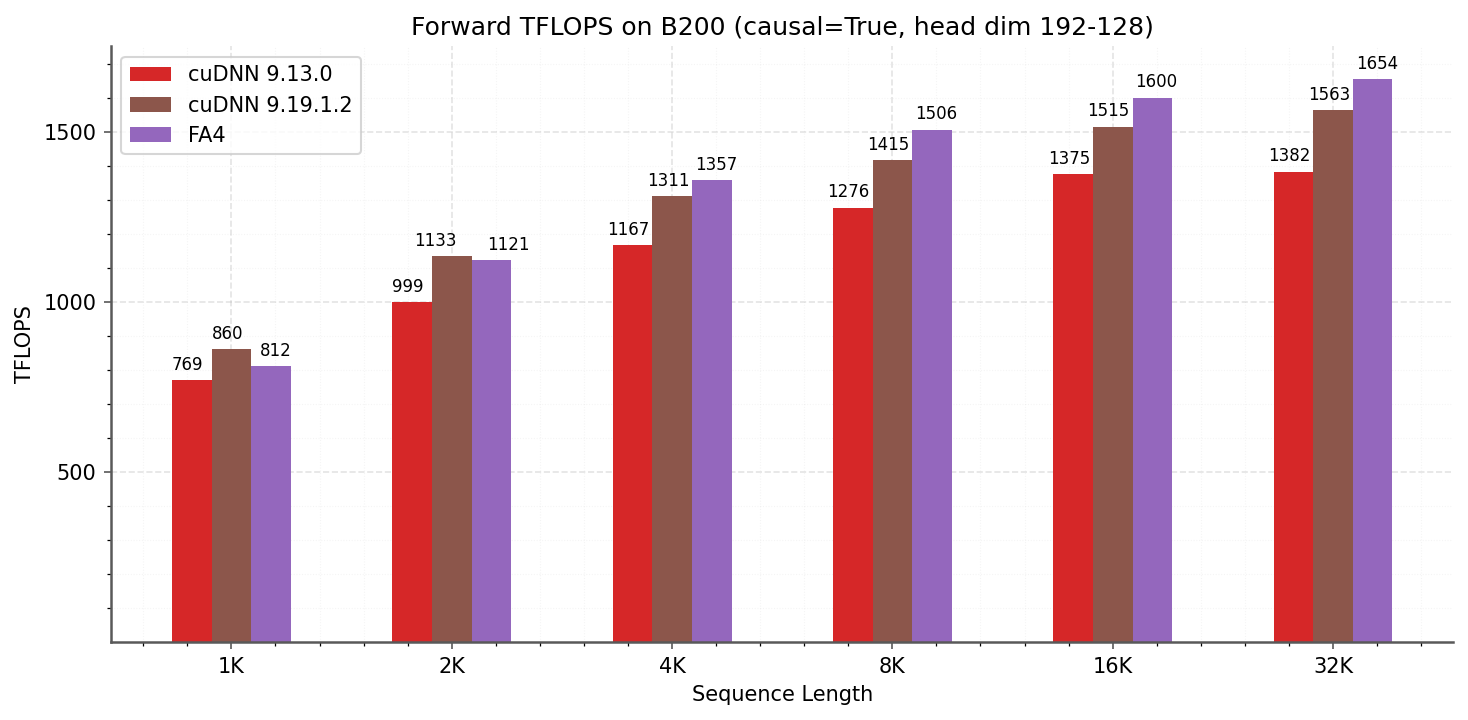
DeepSeek V3에서 사용하는 head dim (192, 128) 설정에서도 cuDNN 대비 일관되게 우수한 성능을 보인다.
Backward Pass
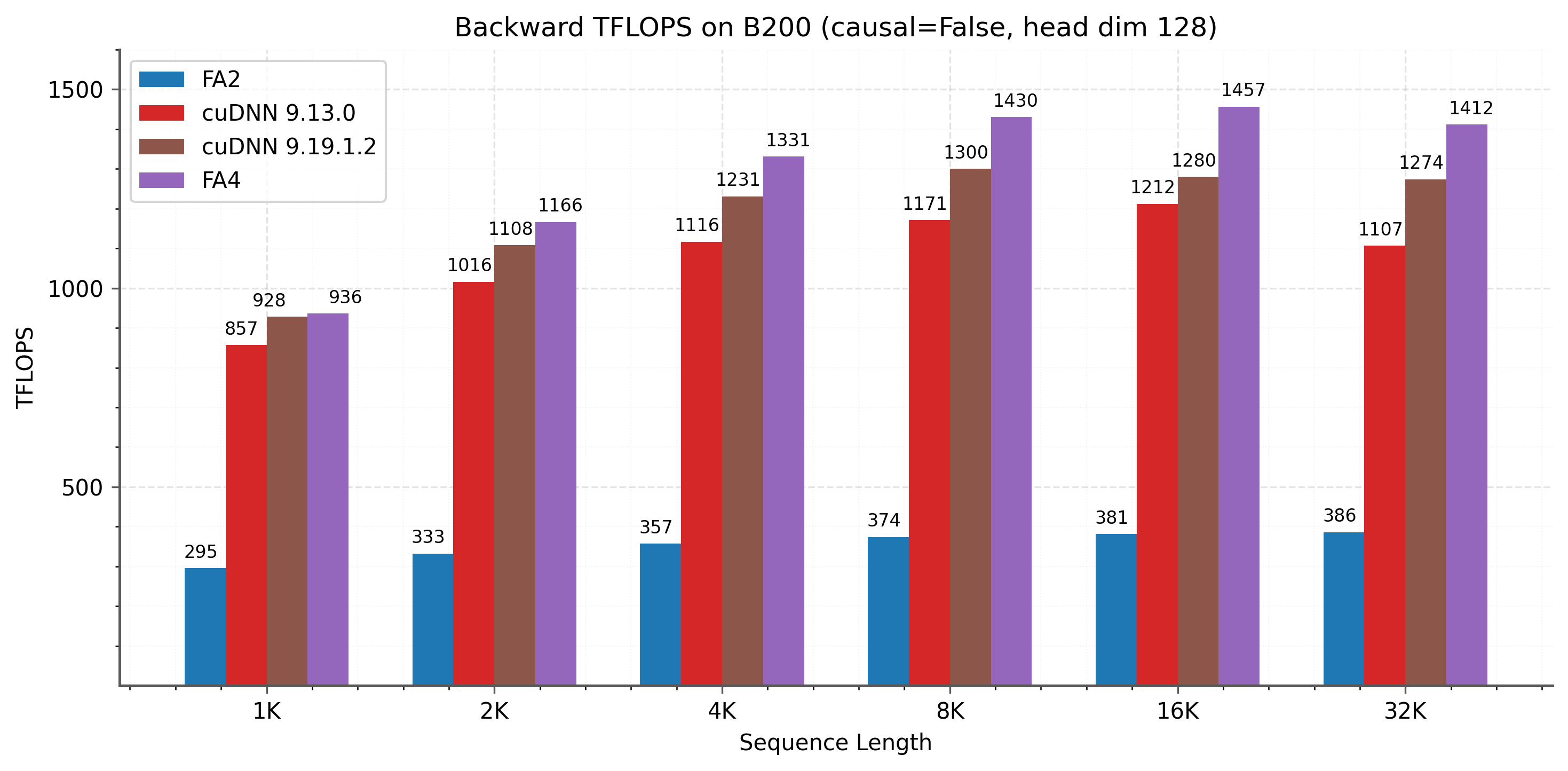
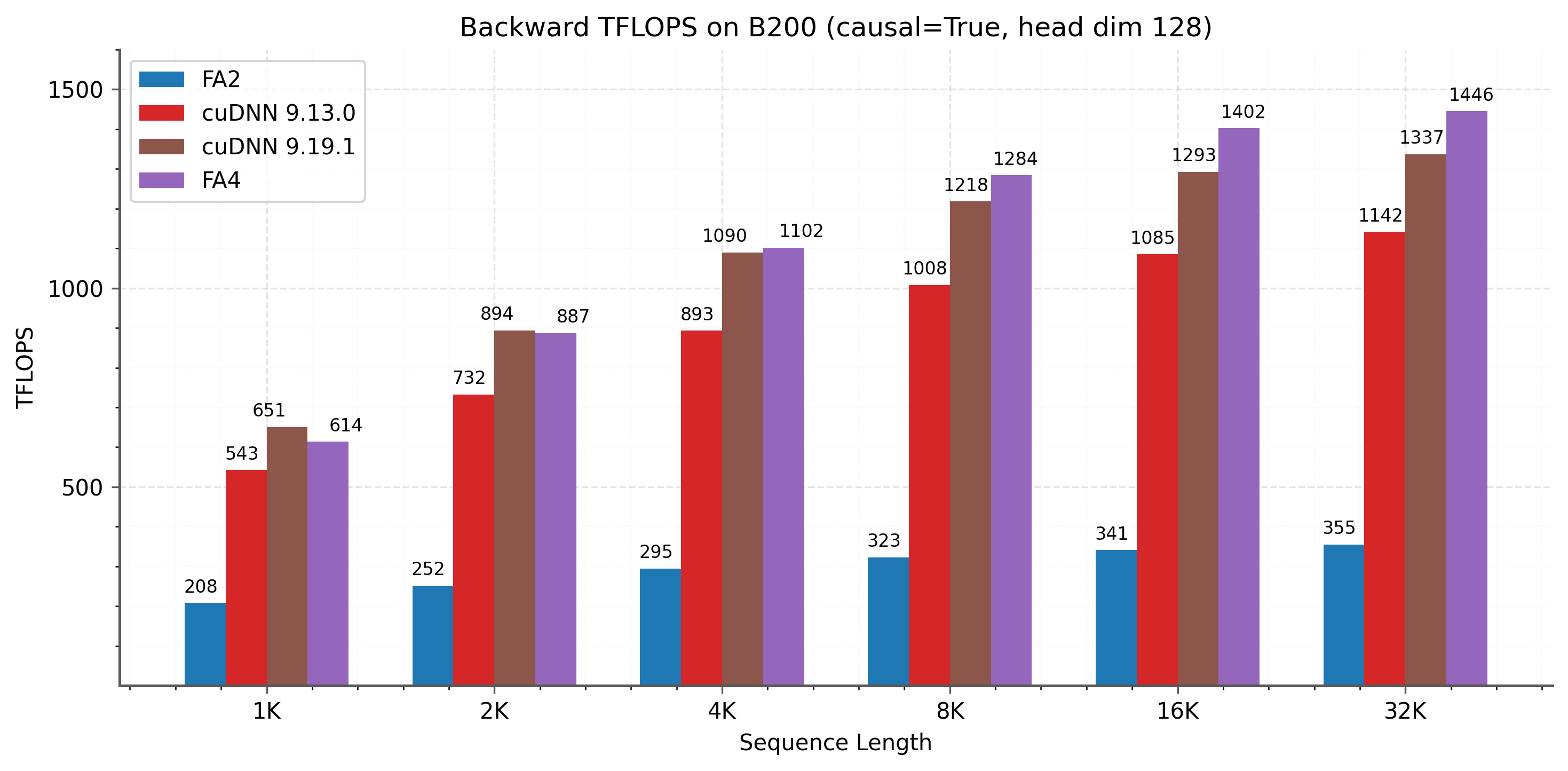
Backward에서도 cuDNN 대비 일관된 speedup을 달성한다. 2-CTA 모드가 shared memory 병목을 완화하여 특히 긴 시퀀스에서 효과적이다.
Deterministic Backward Ablation
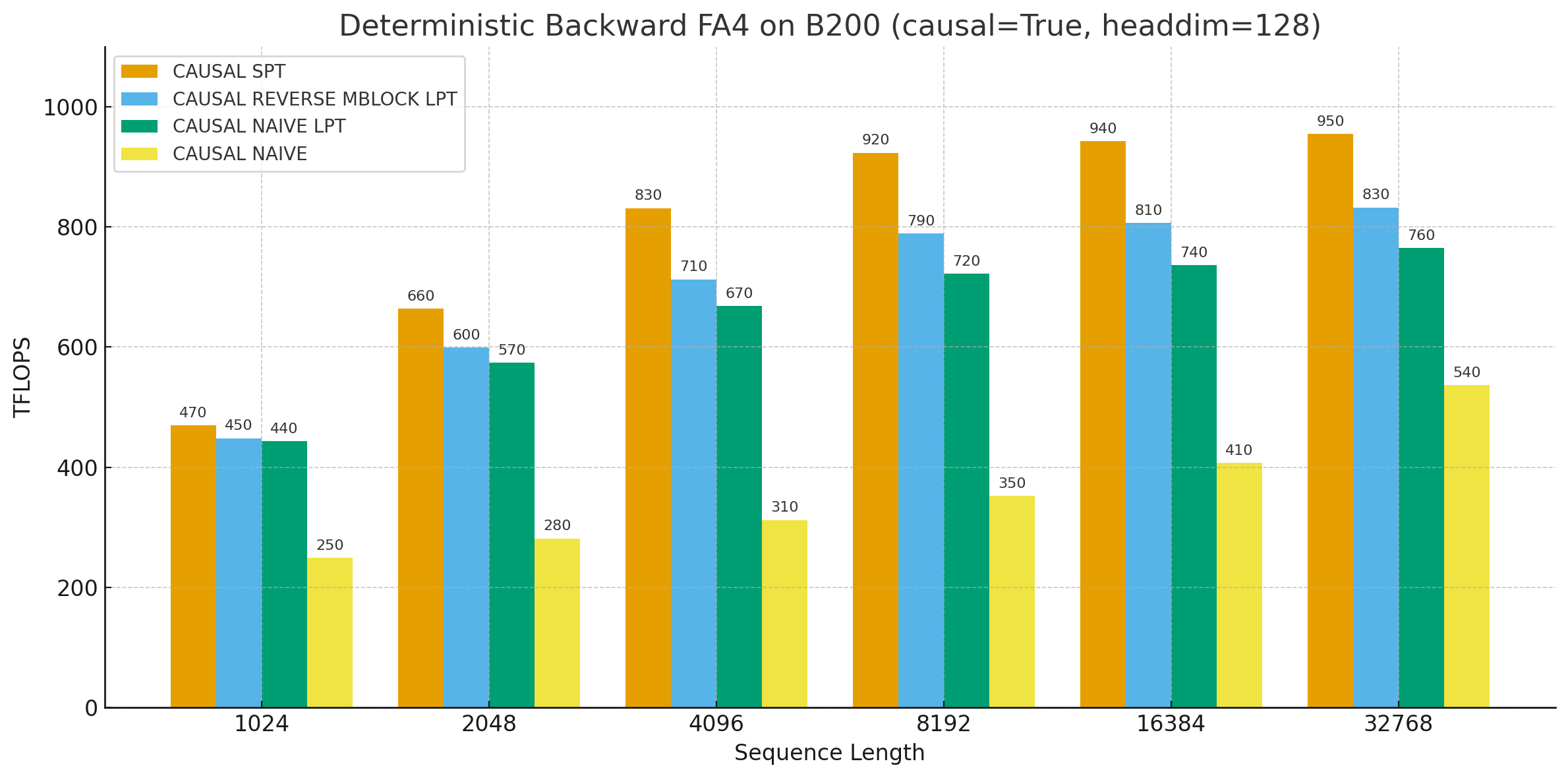
Deterministic backward의 스케줄링 전략 비교:
- SPT (Shortest-Processing-Time first): Causal에서 최적
- Reverse mblock LPT: 차선
- Naive: 스케줄링 없이는 성능이 크게 떨어짐
CTA swizzling과 LPT 스케줄링 조합이 deterministic 모드에서도 nondeterministic 대비 75%의 성능을 유지하게 한다.
FlashAttention 시리즈 비교
| FA1 | FA2 | FA3 | FA4 | |
|---|---|---|---|---|
| GPU | A100 | A100 | H100 | B200 |
| 핵심 아이디어 | Tiling + Recomputation | non-matmul 감소, split-Q | Ping-pong, FP8 | SW exp, conditional rescale, 2-CTA |
| 병목 | HBM IO | non-matmul FLOPs | GEMM vs softmax | exp + SMEM |
| MMA 명령 | mma.sync | mma.sync | WGMMA | tcgen05.mma |
| Accumulator | Register | Register | Register | Tensor Memory |
| BF16 성능 | — | ~230 TFLOPS | ~740 TFLOPS | ~1613 TFLOPS |
| GPU 활용률 | — | 50-73% | 75% | 71% |
| 구현 언어 | CUDA C++ | CUDA C++ | CUDA C++ | CuTe-DSL (Python) |
| 컴파일 시간 | — | ~55s | ~55s | ~2.5s |
Discussion and Conclusion
FlashAttention-4는 비대칭 하드웨어 스케일링이라는 현대 가속기의 근본적 추세를 정면으로 다룬 논문이다. Tensor Core가 다른 유닛보다 훨씬 빠르게 발전하면서, 병목이 matmul에서 shared memory 트래픽과 지수함수 처리량으로 이동했다. FA4는 이를 세 가지 방향에서 해결한다.
- 연산 분산: exp를 MUFU에서만 하지 않고 FMA 유닛에도 분산하여 처리량 증가
- 불필요한 연산 제거: 조건부 rescaling으로 보정 횟수 10배 감소
- 메모리 효율: TMEM과 2-CTA 모드로 shared memory 병목 완화
또한 CuTe-DSL로의 전환은 단순한 구현 선택이 아니라, attention 커널 개발의 접근성을 크게 높인 결정이다. FlexAttention, block-sparse attention 등 다양한 attention variant를 FA4 프레임워크 위에 빠르게 구현할 수 있다.
FA1이 “IO를 줄이자”, FA2가 “non-matmul을 줄이자”, FA3가 “GEMM과 softmax를 겹치자”였다면, FA4는 “하드웨어의 비대칭을 소프트웨어로 보상하자”라는 메시지를 던진다. 가속기가 더 빠르게, 더 비대칭적으로 발전할수록, 이런 하드웨어-소프트웨어 co-design의 중요성은 더 커질 것이다.
FlashAttention의 원리가 궁금하다면 FlashAttention 논문 리뷰를, 개선점이 궁금하다면 FlashAttention-2 논문 리뷰를, Hopper GPU 최적화가 궁금하다면 FlashAttention-3 논문 리뷰를, Triton으로 직접 구현하고 싶다면 Triton 05: Flash Attention을 참고하자.
참고 문헌
- FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling (arXiv)
- We reverse-engineered Flash Attention 4 — Modal Blog
- FlashAttention GitHub — Dao-AILab
- FlashAttention-4 CuTe-DSL Implementation
- NVIDIA Blackwell Architecture Technical Brief
- NVIDIA CuTe-DSL Documentation
- NVIDIA cuDNN Release Notes
Enjoy Reading This Article?
Here are some more articles you might like to read next: