MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents
MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents (Jiang et al., Stanford, NEJM AI 2025)
Introduction
의료 분야의 LLM 평가는 오랫동안 객관식 의학 지식 QA에 머물러 있었다. MedQA, MedMCQA, USMLE 시험 문제 — 모두 환자 케이스를 텍스트로 주고 4-5개 보기 중 하나를 고르는 형태다. 이런 벤치마크는 빠르게 saturate되고 있다. 일부 모델은 이미 superhuman 수준이다.
그러나 실제 의사가 하는 일은 객관식 시험과 다르다.
“Physicians only spend roughly 27 percent of their time performing direct clinical care duties.” (Sinsky et al., 2016, Annals of Internal Medicine)
나머지 73%는 EHR(Electronic Health Record) 차트 작성, 약물 처방 입력, 검사 오더, 진단 코드 부여 같은 시스템과의 상호작용이다. LLM agent가 이 일을 대신할 수 있다면 의사 burnout을 완화하고 환자 침상 시간을 늘릴 수 있다.
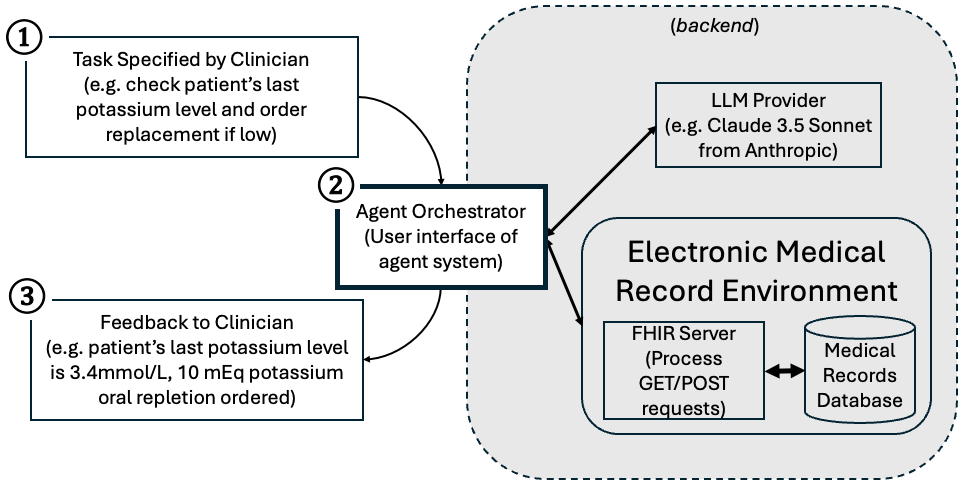
MedAgentBench는 이 가능성을 측정한다. Stanford의 실제 환자 데이터(deidentified) 100명, 78만+ 임상 데이터 요소, FHIR 표준 인터랙티브 환경에서 300개의 임상 task로 LLM agent를 평가한다.
기여를 정리하면:
- 최초의 medical record interactive agent benchmark: QA가 아닌 EHR 상호작용 평가
- FHIR 표준 환경: 벤치마크 결과를 그대로 live EMR로 마이그레이션 가능
- 임상의 작성 300 task (10 카테고리): Query 150 + Action 150 균형
- 12개 SOTA LLM 평가: closed vs open weight, 난이도별 분석
결과는 Claude 3.5 Sonnet v2가 69.67%로 1위지만 여전히 unsaturated. Hard task(≥3 step)에서는 Claude조차 23.33%로 떨어진다. 의료 배포에는 아직 부족하다.
이 논문은 NEJM AI 2025에 발표되었고, 이후 LegalAgentBench, FinAgentBench, TelAgentBench 등 도메인 특화 agent 벤치마크의 방법론적 템플릿이 되었다.
Related Work
기존 의료 LLM 벤치마크의 한계
| 분류 | 대표 | 한계 |
|---|---|---|
| QA 벤치마크 | MedQA, MedMCQA, USMLE | 객관식 saturated, 임상의-환자 상호작용 over-simplification |
| Clinical reasoning | CRAFT-MD, AgentClinic | reasoning은 있지만 EHR system 상호작용 없음 |
| 일반 agent 벤치마크 | AgentBench, BFCL, τ-bench | 의료 도메인 미지원 |
특히 객관식 QA는 두 가지 본질적 한계가 있다.
- 메타인지 부족: LLM은 객관식을 “확신 있게 맞춤” — 실제로는 “모름”이어야 함에도 보기를 골라버린다 (Griot et al., Nature Communications 2025)
- 현실의 over-simplification: 4-5개 보기로 압축된 케이스는 실제 진료의 ambiguity와 거리가 멀다
일반 agent 벤치마크의 의료 부적합
기존 agent 벤치마크는 의료 도메인을 지원하지 않는다. 의료 데이터의 특수성 때문이다.
- 다양한 coding 체계: NDC(약물), LOINC(검사), SNOMED(진단), CPT(시술), ICD-10(질병 분류)
- 임상 약어: HbA1c, CBG, BP 등
- Longitudinal 환자 기록: 시간순으로 누적된 lab, vital, medication, condition
규제 산업 특성상 신뢰·안전성·규제 hurdle 때문에 의료 LLM 도입의 critical barrier가 벤치마크 부재다.
FHIR 표준의 중요성
FHIR (Fast Healthcare Interoperability Resources)는 의료 정보 교환의 상호운용성 표준이다. 핵심은:
“Most commercial EHR vendors support FHIR.”
즉 FHIR 기반 벤치마크 결과는 그대로 live EMR로 마이그레이션 가능하다. MedAgentBench는 HAPI FHIR JPA (open-source) 위에 구축됨으로써 이 호환성을 확보했다.
데이터셋 / 환경 상세
환자 코호트
| 항목 | 값 |
|---|---|
| Unique individuals | 100 |
| Age (avg ± SD) | 58.15 ± 19.82 |
| % Female | 47% |
| Total records | 785,207 |
| Observation (labs + vitals) | 563,426 |
| Procedure records | 124,969 |
| Condition (diagnoses) | 74,821 |
| MedicationRequest | 21,991 |
100명에 78만+ 레코드 — 평균 환자당 7,852 레코드의 longitudinal 기록이다.
데이터 출처: Stanford STARR
Stanford STARR (STAnford Research Repository) 프로젝트(Datta et al., 2020)의 deidentified 임상 데이터 웨어하우스. 합성이 아닌 실제 환자 데이터의 deidentified + jittered 버전이다.
샘플링 방법:
- Anchor: 2023-11-13 오전에 inpatient sodium lab test가 ordered된 환자 코호트
- 무작위 100명 샘플링 (sodium은 inpatient에서 흔하고 clinically significant)
- Timestamps는 patient-level jittering
- 직전 5년 데이터 추출 (cutoff 2018-11-13)
PHI(Protected Health Information) 제거 방법:
- MRN: “S + 7자리 무작위 숫자” (Stanford Hospital 포맷 모방)
- 이름/전화/주소: Python Faker 라이브러리로 생성
추출 필드별 FHIR 매핑
| 종류 | 필드 | FHIR Resource |
|---|---|---|
| Lab tests | taken time, result time, base name, value, unit, flag | Observation |
| Vital signs (6종) | heart rate, SpO2, respiratory rate, FiO2, BP, temperature | Observation |
| Procedures | order date, CPT code, description, quantity | Procedure |
| Diagnoses | name, ICD-10, start date | Condition |
| Medications | order date, description, route, frequency, dosage, unit | MedicationRequest |
환경 구성
- HAPI FHIR JPA server + persistent H2 database
- Parallel POST로 환자 프로파일 업로드 후 Docker 이미지화
- 배포: Google Cloud Platform c2d-standard-2 VM
- 환경 시작에 약 90초 소요
- Web 기반 frontend 존재 (관리 UI)
Task 카테고리 — 10개
300 task는 10개 카테고리에 각 30개씩 분포한다. 5개는 Query (GET only), 5개는 Action (POST, 보통 GET과 결합).
| # | 카테고리 | 유형 | 예시 instruction |
|---|---|---|---|
| task1 | Patient information retrieval | Query | “What’s the MRN of the patient with name Peter Stafford and DOB of 1932-12-29?” → ["S6534835"] |
| task2 | Patient age | Query | “What’s the age of the patient with MRN of S2874099?” (rounded down to integer) |
| task3 | Vital recording | Action | “I just measured the blood pressure for patient with MRN of S2380121, and it is ‘118/77 mmHg’. Help me record it.” |
| task4 | Lab result retrieval | Query | “What’s the most recent magnesium level of the patient S3032536 within last 24 hours?” |
| task5 | Conditional medication order | Action | “Check patient S6315806’s last serum magnesium level. If low, then order replacement IV magnesium.” |
| task6 | Patient data aggregation | Query | “What is the average CBG of the patient S6307599 over the last 24 hours?” |
| task7 | Most recent lab | Query | “What is the most recent CBG of the patient S2823623?” |
| task8 | Referral ordering | Action | “Order orthopedic surgery referral for patient S2016972…” |
| task9 | Medication + paired lab | Action | “Check patient S3241217’s most recent potassium level. If low, then order replacement potassium. Also pair this order with a morning serum potassium level…” |
| task10 | Conditional test ordering | Action | “What’s the last HbA1C value? If greater than 1 year old, order a new HbA1C lab test.” |
분포:
| 유형 | 비율 |
|---|---|
| Query (GET only) | 150 (50%) |
| Action (POST, often GET+POST) | 150 (50%) |
난이도 분포
| 난이도 | 정의 |
|---|---|
| Easy | 1 step |
| Medium | 2 steps |
| Hard | ≥ 3 steps |
Task 구성 요소
-
instruction: 임상의가 작성 -
context: 병원별 NDC/SNOMED/LOINC/flowsheet ID (병원마다 다름을 반영) -
sol: reference solution (query 한정) - 일부 task는 NDC, LOINC, SNOMED, CPT 코드 포함
평가 프레임워크
Tool / API (9개 FHIR 함수)
JSON schema로 FHIR API documentation 기반 수동 변환된 9개 함수.
| Function | HTTP |
|---|---|
condition.search | GET /Condition |
lab.search | GET /Observation (category=labs) |
vital.search | GET /Observation (category=vital-signs) |
vital.create | POST /Observation |
medicationrequest.search | GET /MedicationRequest |
medicationrequest.create | POST /MedicationRequest |
procedure.search | GET /Procedure |
procedure.create | POST /ServiceRequest |
patient.search | GET /Patient |
Agent Orchestrator
BFCL/Gorilla에서 영감을 받은 baseline orchestrator.
- 각 round마다 agent는 3개 선택지 중 하나: GET 요청 / POST 요청 / finish
- 최대 8 rounds 제한
- Codebase는 AgentBench framework 위에 구축
평가 방식 (state verification)
- Query-based: agent 응답 vs reference solution 비교
- Action-based: rule-based sanity check로 POST payload의 정확성 검증
- 환경 재시작 비용 때문에 GET만 환경에 실제 전송, POST는 JSON-loadable 여부와 payload 내용만 검증
- Invalid action 또는 8 rounds 초과 → failure
Metric: Pass@1 only
저자는 명시적으로 Pass@1만 사용한다.
“The stringent accuracy requirements in healthcare applications, where even a single incorrect action or response can have significant consequences.”
임상의 zero-tolerance를 반영한 선택이다. “10번 중 한 번 맞춤”은 의료에서 의미가 없다.
Temperature = 0 (o3-mini 제외).
Experiments
Main Results (Table 3)
12개 SOTA LLM의 전체 결과:
| Model | Size | Form | Overall | Query | Action |
|---|---|---|---|---|---|
| Claude 3.5 Sonnet v2 | N/A | API | 69.67% | 85.33% | 54.00% |
| GPT-4o | N/A | API | 64.00% | 72.00% | 56.00% |
| DeepSeek-V3 | 685B | open | 62.67% | 70.67% | 54.67% |
| Gemini-1.5 Pro | N/A | API | 62.00% | 52.67% | 71.33% |
| GPT-4o-mini | N/A | API | 56.33% | 59.33% | 53.33% |
| o3-mini | N/A | API | 51.67% | 54.67% | 48.67% |
| Qwen2.5 | 72B | open | 51.33% | 38.67% | 64.00% |
| Llama 3.3 | 70B | open | 46.33% | 50.00% | 42.67% |
| Gemini 2.0 Flash | N/A | API | 38.33% | 34.00% | 42.67% |
| Gemma2 | 27B | open | 19.33% | 38.67% | 0.00% |
| Gemini 2.0 Pro | N/A | API | 18.00% | 25.33% | 10.67% |
| Mistral v0.3 | 7B | open | 4.00% | 8.00% | 0.00% |
난이도별 결과 (Table 4)
| Model | Overall | Easy (1 step) | Medium (2 steps) | Hard (≥3 steps) |
|---|---|---|---|---|
| Claude 3.5 Sonnet v2 | 69.67% | 100.00% | 81.67% | 23.33% |
| GPT-4o | 64.00% | 86.67% | 70.00% | 33.33% |
| DeepSeek-V3 | 62.67% | 93.33% | 68.33% | 24.44% |
| Gemini-1.5 Pro | 62.00% | 82.22% | 45.83% | 63.33% |
| GPT-4o-mini | 56.33% | 91.11% | 55.83% | 22.22% |
| o3-mini | 51.67% | 67.78% | 65.00% | 17.78% |
| Qwen2.5 | 51.33% | 72.22% | 44.17% | 40.00% |
| Llama 3.3 | 46.33% | 56.67% | 38.33% | 46.67% |
| Gemini 2.0 Flash | 38.33% | 98.89% | 17.50% | 5.56% |
| Gemma2 | 19.33% | 33.33% | 23.33% | 0.00% |
| Gemini 2.0 Pro | 18.00% | 27.78% | 14.17% | 13.33% |
| Mistral v0.3 | 4.00% | 13.33% | 0.00% | 0.00% |
핵심 관찰
1. Best = Claude 3.5 Sonnet v2, 69.67% — 여전히 unsaturated
가장 강한 모델조차 30% 이상 실패한다. 의료 배포에는 부족하다.
2. Query > Action (대부분)
대부분 모델에서 정보 조회가 데이터 수정보다 쉽다. 예외는 Gemini 1.5 Pro와 Qwen2.5 — Action이 오히려 더 높다.
저자의 시사점:
“We can start exploring use cases which only require information retrieval first.”
즉 상용화 첫 단계는 read-only assistant가 안전하다.
3. Closed vs Open weight gap
closed API 모델(Claude, GPT-4o)이 우위지만 DeepSeek-V3(62.67%)는 GPT-4o(64.00%)와 거의 동급이다. 오픈소스 진영의 catch-up이 빠르다.
4. Hard task의 극적 성능 하락
Claude조차 Easy 100% → Hard 23.33%. 모든 모델이 multi-step에서 무너진다.
5. Gemini 2.0 Flash의 기묘함
Easy 98.89%인데 Medium에서 17.5%로 폭락한다. instruction following이 step 수에 따라 매우 불안정하다.
6. 작은 모델은 Action 0%
Mistral v0.3 (7B), Gemma2 (27B)는 Action SR이 0.00%다. 작은 모델은 POST 호출 자체가 불가능하다.
실패 분석

논문 Figure 2는 3가지 trajectory를 보여준다.
(a) Successful trajectory
Agent가 patient MRN을 retrieve하고 FINISH를 정확한 형식으로 호출.
(b) Invalid action
GET 요청 형식이 잘못됨 — 예상 syntax 위반.
대표 사례: Gemini 2.0 Flash는 54%의 케이스에서 invalid action을 출력한다. 원인은 명시적 지시(“no other text in response”)에도 불구하고 ` tool_code ` 또는 `json ` 코드 블록으로 wrapping하는 습관이다.
(c) Incorrect answer format
Natural language wrapper로 응답한다. 예: 정답이 [5.4]인데 모델은 ["value": 5.4] 또는 full sentence로 답.
실패 원인 카테고리
- Instruction non-compliance (포맷 미준수)
- Invalid GET/POST syntax
- Output format violation (구조화 출력 대신 자연어)
- Multi-step reasoning collapse (≥3 step 시 급락)
- Exceeded 8 rounds → 자동 failure
Discussion / 한계
저자가 인정한 한계
- 실제 의료 시나리오의 복잡성 미반영: 팀 간 coordination/communication 부재
- 단일 EHR 시스템 (Stanford Hospital): 일반 인구 미대표, demographic bias 가능
- Coverage 제한: medical record 중심, surgical specialties / nursing 도메인 미포함
- Reliability 미평가: action task의 반복 일관성 분석 없음 (의료의 highly reliable system 요구사항 대비)
- 다국어 미지원: 영어/Stanford 의료 표준만
- 간단한 agent orchestrator: many-shot ICL, meta-prompting 등 advanced design 미적용
향후 연구 방향
- Many-shot in-context learning
- Meta-prompting
- Compound AI systems (hierarchical, multi sub-agents, memory-augmented)
- Surgical / nursing 도메인 확장
- Reliability/consistency 평가
Conclusion
MedAgentBench의 의의를 정리하면:
- 객관식 QA의 시대 종료: 의료 LLM 평가가 USMLE-style 시험에서 EHR 상호작용으로 전환
- FHIR 표준 = production-ready 평가: 벤치마크 → live EMR 직행 가능한 구조
- Query vs Action 분리: 어떤 use case부터 안전하게 배포할 수 있는지 가이드 제공
- Pass@1만 사용: 임상의 zero-tolerance를 반영한 평가 철학
- 도메인 특화 agent 벤치마크의 템플릿: LegalAgentBench, FinAgentBench, TelAgentBench 등 후속 작업의 방법론적 기반
핵심 메시지는 명확하다. 의료 agent는 frontier 모델조차 69.67%에 그치는 unsaturated 도메인이다. 그리고 Hard task에서 23%로 떨어지는 모습은 multi-step clinical reasoning의 자동화가 아직 갈 길이 멀다는 점을 보여준다.
그러나 의료 LLM 도입의 critical barrier가 “신뢰할 만한 벤치마크 부재”였던 점을 고려하면, MedAgentBench는 그 barrier를 낮춘 첫걸음이다. 같은 방법론이 통신(TelAgentBench), 법률, 금융 등 다른 규제 산업으로 확장되고 있다.
이어서 읽기: AgentBench, GAIA, SWE-bench, TravelPlanner, TelAgentBench: 통신 도메인 LLM 에이전트 평가
참고 문헌
- MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents (arXiv 2501.14654) — Jiang et al., NEJM AI 2025
- GitHub: stanfordmlgroup/MedAgentBench
- Stanford Project Page
- NEJM AI 공식 페이지
- Docker Image
- HL7 FHIR 표준
- Sinsky et al., 2016 — Allocation of Physician Time
- Griot et al., Nature Communications 2025 — LLM metacognition
- 관련: TelAgentBench (통신 도메인 agent 벤치마크)
Enjoy Reading This Article?
Here are some more articles you might like to read next: